
(图:阿里巴巴集团副总裁、数据技术及产品部负责人朋新宇 来源:199IT)
数据中台扎实有效
2015年,阿里巴巴在国内首次提出数据中台概念,它是集方法论、工具、组织于一体的“快”、“准”、“全”、“统”、“通”的智能大数据体系。
历经内部复杂场景的实践后,阿里巴巴在2018年正式通过阿里云全面对外输出数据中台能力,帮助企业实现数智化转型。
朋新宇在现场分享了来自餐饮、快消、服饰、商业地产、旅游业等行业的头部企业案例。
蓝光地产利用数据中台服务孵化出了更多销售创新场景,仅“老带新”的一个单一场景就为该企业实现了单日36亿元成交额。
雅士利则通过阿里云数据中台挖掘了5个业务场景,短期快速提效,去年双11期间实现了同期增长92%。
而今年“新冠”疫情的特殊考验,更是让越来越多企业感受到数字经济趋势下数智化的重要性。
疫情期间,红蜻蜓4000多家门店无法营业,但通过全员线上服务营销,7天内新设立了500多个粉丝群,日均销售额突破百万。
无独有偶,雅戈尔3000余家线下门店在疫情期间悉数歇业。但随着全员all in线上营销,一季度整体业绩已经恢复到同期的80% 。
根据亿欧智库针对过去一年内沪深两地上市公司公告的集中研究,已有超过500家企业将数据中台的实施进展纳入了上市公告中。
产品矩阵从“2”变“4”
据朋新宇介绍,阿里云数据中台核心产品矩阵从之前的两大核心产品——Dataphin、Quick BI,拓展到了Dataphin、Quick BI、Quick Audience和Quick A+四大核心产品。
聚焦智能数据构建及管理领域的Dataphin,完成了数据服务开放和自助式开发升级,并针对中小企业,提供了轻量化版本。
作为国内唯一成功进入国际知名机构Gartner魔力象限的BI产品而受到广泛关注的Quick BI,本次升级重点聚焦在与钉钉的协同合作上。升级后,用户可以实现“随时随地,智能决策”。
新亮相的Quick Audience定位于智能用户增长,帮助实现“全方位洞察、多渠道触达”的增长闭环。Quick A+则是跨多端的全域应用洞察平台,能够帮助企业对用户进行综合分析,了解用户的使用习惯并进行相应的预测和决策。
四大行业解决方案齐飞
除了丰富产品能力之外,阿里云数据中台本次峰会上,朋新宇还重磅发布四大行业数据中台解决方案:零售数据中台、金融数据中台、政务数据中台以及互联网企业数据中台,将进一步把数据中台引入全速重构业务数智化的深地。
据介绍,针对零售行业,阿里云数据中台可以提供多维的全方位洞察、全域自动化营销等服务,并通过与阿里巴巴生态联动,帮助更多零售企业实现数智化增长;
针对金融行业,提供理财业务线上用户增长、整体的数字化运营解决方案,通过联动蚂蚁生态,融合投资者教育的实践方法论,并集成支付宝小程序中,帮助金融机构实现业务增长;
针对政务行业,提供全套政务数字参谋解决方案,实现跨端、跨层级、跨系统等政务数据融通,支持政府决策科学化、社会治理精准化、公共服务高效化;
针对互联网企业,阿里云数据中台将与友盟+进行深度联动,让互联网企业能拥有阿里云数据中台的能力,在营销增长、风控、智能运营等场景中实现业务增长。
这四大数据中台行业解决方案是阿里云数据中台行业边界的一次重要拓展,标志着阿里云数据中台已经实现了从通用领域走向精细化垂直领域。
朋新宇表示,全新升级后的阿里云数据中台将成为企业数智化的新基建,未来将帮助超过100万企业,实现数智化加速升级。
更多阅读:
以下内容分三部分:算法的核心;算法有多大用;实际工程中算法怎么工作的
1. 算法的核心是什么
推荐算法的核心是基于历史信息寻找被推荐的东西(可能是人、物、信息)与用户的一种关联性,进而去预测你下一步可能喜欢什么,本质上还是基于统计学的一种推测(谷歌的深度学习除外)。
这里有两个关键点:历史信息;关联性
历史信息也就是大家所说的标准化数据
关联性也就是大家常说的算法,他做的事情就是猜测你可能会喜欢怎样的东西.要搞清楚这个问题,还是得回到人在不同的场景中会喜欢怎样的东西,这个在不同的场景中差别比较大。举两个例子说明一下
对于微信朋友圈:用户最关心的是我跟发布者的亲密度,其次是内容的质量和内容的发布时间,这也就是Facebook智能信息流的雏形,根据跟发布者的亲密度,内容的质量和内容的新鲜程度的一个混排算法。

对于美团外卖:用户最关心的是这家餐厅好不好吃,价格贵不贵,有没有优惠,配送时间长不长。至于我认不认识这家餐厅的老板,这家餐厅开业时间就不是重点,所以算法就可能是完全不一样的思路。
不管Facebook信息流还是美团外卖,核心还是得去理解用户在你的产品中到底喜欢怎样的东西,这个是基础,算法只是工具。
2. 算法真的有那么大效果吗
这几年今日头条的成功,包括业内各种AI、人工智能的吹,让我们以为算法无所不能,实际上算法真的有这么神奇吗?
答案是没有。。。
今日头条的成功我认为主要还是靠对流量的理解,战略和公司的运营、算法、数据化思维形成的执行力。算法在里面只是一环
举一个淘宝的例子,去淘宝的人从需求的强弱程度来看分三种:明确知道我要买啥的,知道我要买啥品类但具体买啥不知道,就是来逛的。
第一类算法没有增长点,我就要买个苹果的iphoneX,你再怎么推荐我也是买个苹果X
第二类算法的增长点一般,我要买个蓝牙耳机,算法处理的好能提高成单率,客单价,利润,但也是有限的,因为用户进来之前已经有了一些基本的预算之类的预设。
第三类是比较大的增量空间,因为第三类属于激发性需求。就像你去商场听导购一顿忽悠,买了本身不需要的东西。但是第三类的成单量本身的占比并没有那么大。
所以综合下来,算法实际的效果也就是在完全没有算法的基础上有1.1,1.2,1.3倍这样的效果,这是由用户的需求总量决定的。
当然我不是说算法没用,因为在同等成本结构的基础上,你的转化率哪怕比竞争对手高5%,那也是巨大的效率碾压。我只是想说算法没有大家吹得那么厉害,并不能直接决定一家公司的成败,算法只是一个辅助。
3. 水果店案例说明算法在实际工程中的工作过程
在实际的商品类的推荐系统中,主要分三大块:收集数据和整理(商品画像、用户画像);算法推荐;上线实验及回收结果。
收集数据及整理
假设小明开了一个有3家分店的大型水果连锁店,收集数据阶段主要包括:
商品属性信息:小明将店内的每一个水果以及水果的信息都记下来,甜的还是酸的,品质S还是A,有没有损坏,性寒还是热,单价贵不贵,有没有优惠等等。这是商品的基本属性信息。
商品反馈信息:销量咋样,停留率咋样,停留转化率咋样,用户的评价反馈咋样。这个是基本的反馈信息。
人的基本属性:什么人,什么小区,穿着打扮咋样,年龄多大,哪里人
人的行为信息:这次买了啥,下次买了啥,看了啥,咨询过啥,买完之后反馈咋样。
数据阶段收集是一方面,最关键的是收集的数据是结构化的,是在用户的购买决策中是有效的,比如说用户中途出去抽了一根烟这种信息就没啥用。。。
算法推荐
算法阶段关键的还是搞清楚用户在不同的场景中会喜欢怎样的水果。
我个人喜欢把商品推荐主干算法分为4个部分:质量评估,个性化,场景化,人工干预
质量评估:有些标准是存在绝对的好与坏的,水果是不是好的,性价比高不高,销量好不好,优惠力度大不大,用户反馈好不好这些是存在绝对的好与坏的,我相信没人想买个烂苹果。
个性化:有些东西是存在个体差异的,甜的还是酸的,进口的还是国产的,水果的品种是樱桃还是芒果,性凉还是热的,品质分级是S还是A(跟前面的烂没烂两个概念)。
举个例子:一个金融白领可能喜欢的是甜的车厘子,进口的,品质S级的,优惠不敏感,客单价高;而小区的家庭主妇喜欢的可能是杨梅,品质还过得去的国产的就行,很在乎优惠,客单价适中的。那对于前一种用户就可以推一些客单价高的,毛利高的进口产品,相应的也可以少设置优惠;对于后一种就应该推一些性价比高的,有折扣的清仓的商品。
场景化:不同的时间和地点会一定程度上影响用户的消费决策,比如夏天大家喜欢吃西瓜,在医院边上香蕉好卖,中午的时候不带皮可以直接吃的东西好卖因为大部分下午还要上班,晚上则需要处理的也卖的还可以。这个就是不同的场景带来的影响
人工干预:算法本身是不带意志的,但是很多时候人会强加一些意志上去,比如说最近年底冲业绩了,需要强推高毛利的商品了;比如这个樱桃是合作方的,需要强推;比如有些东西快过期了,需要强推。这个时候就需要人工去做一些干预
算法最后做的就是把里面每一个环节打上一个分,最后再把这些因素去加总得到一个最后的结果呈现在用户面前。但是这个分怎么打?这个就涉及到算法的价值观
所谓算法的价值观,就是你希望算法最终的结果是怎样的,我是希望销量最大化还是销售额最大化还是利润最大化。不同的目标带来不同的结果。因为算法只是为目标最大化负责的。
算法在处理每一项得分的时候也挺简单,简单说就是,如果我的目标是销量最大化,那有两个特征:优惠力度,评价,如果随着优惠力度的提高购买转化率急剧提升,那么我认为优惠力度这个特征权重就高,如果随着评价的提升购买转化率提升较慢,那么我认为评价这个特征的权重就一般。
这个过程并不复杂,算法的优势在于他能记录更丰富的信息(工程中特征数量可能达到百万级),处理海量的数据。这是算法比人有优势的地方
这个大概能支撑起一个算法的框架,实际的应用中会在一个主干算法的基础上去迭代很多小的策略。
下面举几个具体的细分迭代策略:
比如说买了芒果的用户很大比例都买了樱桃,那相应的会把买芒果的用户列表中的樱桃相应的往前提。这个就是大家常说的购物篮算法
比如说同样是国贸摩根大厦的用户更喜欢进口水果,那对于一个摩根大厦的用户他列表中的进口水果,高客单价水果需要往前提。这个类似协同过滤,通过找到跟你类似的人,再去看他们喜欢啥。
比如说你第一次买了榴莲之后打了差评,以后就需要降低榴莲及相关水果的权重。这个就是负反馈。
比如说你的列表中连续出现了3种葡萄,那这时候大概率是应该把他们打散一下,尽量一页别出太多葡萄。这就是打散
比如当你在浏览的过程中点击了樱桃,那根据购物篮原来喜欢买樱桃的人也喜欢买芒果,那下一页加载的时候需要动态的增加芒果的权重 — 这个是实时反馈
实验及回收效果
个人认为快速的实验迭代和效果回收是算法高效率的关键,也是互联网的核心。修路造桥错了就是错了,而互联网产品这版效果不好下一版还能优化。算法是将这种快速迭代推向了顶峰,同时几十个实验在线上AB测试,不需要发版,好不好马上就能看出来。
AB测试的过程有点类似如果我有5家水果店,我要验证新引进的樱桃设置怎样的价格能收益最大化,我可以5家店同时设置5种价格,卖一周看看结果。
实验主要分两个部分:实验及效果回收
实验就是在其它东西都一样的情况下,留出一个不一样的东西,然后观察最后的结果,这样比较好确定最后的结果差异就是由这个不一样的东西带来的。
效果回收主要是看数据和人去看实际推荐的结果,看数据需要覆盖多一些的指标,因为很可能销量好了毛利降了,或者毛利好了当天剩余率升高了。
人工去看结果主要是一个二次确定的过程,比如在头条里面各种数据都很好,但是推出来的内容很低俗,或者这种数据好人看完之后凭经验知道这不是长久之计,比如周围就一家水果店你恶性提价。。
作者:s_crat
更多阅读:
今年1月份,世界各国领导人齐聚达沃斯的世界经济论坛。来自中国、日本、南非、德国和其他国家的领导人在会议上出人意料地达成了一项共识,即:迫切需要提高数据采集、使用和共享的透明度并制定相关指南。
日本首相安倍晋三针对这一议题明确表示,在2019年6月28 – 29日于大阪举办的二十国集团(G20)峰会上,作为主席国,日本将致力于推动建立新的国际数据监督体系。安倍表示,“我希望G20大阪峰会因启动全球数据治理而被人们长久铭记。”
此外,二十国集团贸易和数字经济部长于近期也发表了声明:“数据、信息、思想和知识的跨境流动提高了生产力、增加了创新并促进了可持续发展。与此同时,我们也认识到,数据的自由流动带来了一些新的挑战。通过应对与隐私、数据保护、知识产权及安全问题相关的挑战,我们可以进一步促进数据自由流动并增强消费者和企业的信任。
从企业和政府的角度来看,以上情况均表明,世界各国普遍意识到了数据的重要性。这一觉醒让人们认识到,原有的企业数据管理方法将不再适合2020年以及之后的企业发展。
墨守成规是不行的。企业和政府部门需要齐心协力,在推动数据驱动的创新以及由此带来的经济增长的同时,共同采取积极措施,保护消费者。
政府的角度
我们正在见证数据治理背后的世界发展趋势。各国政府均意识到,我们所做的有关个人数据的每一件事都应考虑周全,且目的端正。因此,欧洲在去年出台了《通用数据保护条例》(GDPR)等隐私法规,美国则涌现出《加利福尼亚消费者隐私法案》(California Consumer Privacy Act)等一系列新的地方法规,很多人将其视为美国出台相关联邦法律的先兆。
这些全球范围内的立法工作试图解决与个人隐私、数据保护和安全性相关的诸多问题,同时,提高生产力,促进创新和可持续发展。在这些立法工作的推动下,数据治理已被世界各国提上了国家议事日程。
随着各机构将数据转化为创新平台,数字原生和既有品牌之间的界限变得越来越模糊。因此,从数据治理角度看,政府领导人承认,应采取恰当措施治理那些利用个人和敏感数据进行创新和实施管理的机构。
对于政府管控最担心的问题是,过度监管可能阻碍GDP增长,因为数字化所带来的生产力和创新机遇能够促进可持续且包容的经济增长。
在6月份的会议上,部长们认识到平衡两种需求的重要性,即:提高数据使用的透明度需求,以及欢迎并促进创新的需求。部长们表示:“我们认识到,数字时代的治理不仅要有利于创新,其本身也需要创新。同时,还不能丧失法律的确定性”。
令人鼓舞的是,决策者们明白,他们可以通过平衡经济发展和社会信任的方式在创新监管规定和最终实施方面发挥关键性作用。
企业的角度
对于各国政府的领导人来说,将数据治理作为优先任务还是一个重大新闻。但对于大型企业来说,这个话题在过去10年中一直在升温。虽然监管合规是数据治理的最初推动力,但是,基于高质量、可信数据的运营效率和不断提高的业务创新巩固了数据治理作为数据民主化根本推动力的价值。
对许多企业来说,早期的数据治理工作往往是在某个部门范围内,并且基于项目对目标计划提供支持,例如,监管合规性、事务性应用程序的数据质量,以及数据仓库和报表。但对于进入数据3.0时代(即利用数据驱动企业数字化转型)的每家企业而言,他们现在理解了对于整个企业范围内方案决策的方法需求,以便跨企业向技术和非技术数据消费者交付可信的、安全的数据,从而推动实施董事会的战略举措。随着数据量、用户和应用案例的增加、数据类型和用户技能水平的多样性变化,以及技术创新速度的加快,数据达到指数级规模且日趋复杂,这种情况在当下体现得尤为真切。现在,必须治理的信息已远不止在ERP、CRM或数据仓库系统中捕获到的结构化数据了。
我们正在管理数据湖中高达千兆字节(甚至数量更为庞大)的结构化和非结构化数据,以及跨越混合环境的数百个应用程序。各业务领域的人员都希望能访问以上所有数据源,以便提高决策能力和运营执行力,甚至迫切需要将这些数据运用到工作中,从而建立人工智能和机器学习模型,以实现企业未来的规模化发展。
企业也明白,他们的成功依赖于在正确的时间,基于正确的目的,使用正确的数据。获取这些数据需要所有利益相关者之间的信任,包括消费者、合作伙伴和政府部门,要使他们相信,这些数据的使用方式合规且合乎道德标准。实际上,像谷歌和微软这样的企业已经为人工智能和机器学习建立了各自的咨询委员会,并制定了工作指南。
部长们在早些时候的会议上重点讨论了如何确保“提供一个有利的环境,促进以人为本的人工智能,从而推动创新和投资”。部长们在声明中还发表了《G20人工智能原则》(G20 AI Principles),其中包括负责任地管理可信赖的人工智能。数据治理政策和标准将在清晰解释这些原则方面发挥主导作用。
共同的角度
G20大阪峰会已经成功召开,其中有一件事是肯定的:全世界都在关注数据治理,毫无疑问,这将会带来更大力度的监督和问责机制。现在,是国际社会达成共识的时候了,我们应继续培养并欢迎数据驱动创新,同时保护数据并尊重个人隐私。
对政府和企业来说,机会都是巨大的,且政府和企业均无法承担不作为带来的严重后果。如果政府和企业能够合作并认识到以合乎道德的方式使用数据是一种共同的责任,那么,数据就能推动全球经济,推动企业和社会发展。
为在当今数据驱动的经济中取得成功,甚至生存下来,政府和企业双方均应认识到,在数据被明智使用的情况下,数据治理不应被视为一种负担,而应被作为在企业中交付重要业务价值的同时建立信任的机会。我相信,政府和企业都会认同这一点,信任是最有价值的商品之一。
正如部长们给出的详尽阐述,“我们应密切合作,提升人们对数字经济的信任,利用数字化带来的优势,战胜相关挑战。”
更多阅读:
随着神盾推荐业务场景的不断深入,传统的离线训练+线上计算的模式可以说是推荐系统1代框架,已经不能完全满足部分业务场景的需求,如短视频、文本等快消费场景。下面先简单介绍下传统模式以及其在不断变化的场景需求中的不足点。
传统模式简单介绍
传统模式下,整个推荐流程粗略可分为,数据上报、样本及特征构造,离线训练评测,线上实时计算,abtest等。
• 优点:
系统架构简单
普适性较强,能满足大多数业务场景。
• 缺点:
数据及时性不够。
模型实时性不强。
下面举一个简单例子,来说明这样的问题:

小明同学在微视上看了一个视频,那么在推荐场景下,可能会遇到以上四类需求,并且每种需求对于数据的实时性要求并不一样。从推荐系统功能来看,可以概括为已阅实时过滤、用户行为实时反馈、物品池子更新等。所以如果要满足业务需求,从代码层面来看,这样的需求并不复杂,但是从架构层面或者可扩展性来说,神盾作为一个面向不同业务的通用推荐平台,就需要提供一个能满足大多数业务,对于快速据消费的通用平台。
针对不同业务、不同场景需求,神盾希望构建一个快数据处理系统,旨在满足更多业务场景的快速据消费场景。
任何系统的搭建及开发离不开特定的业务场景需求调查,神盾根据多年业务经验,收集归纳了相关快数据处理的相关需求,具体如下:

我们深入调研、讨论,结合业界实践以及神盾的实际情况,总结为两类系统需求:
• 1、 近线系统。满足业务对于物品、特征、及其他数据类服务的准实时更新。
• 2、 在线学习。满足业务对于模型的准实时迭代更新。
基于以上调研,神盾推出Quicksilver(快数据计算)系统,解决推荐场景下快数据计算及更新问题。
Quicksilver系统是一个集近线及在线学习能力为一体的通用架构系统,我们设计之初,从收、算、存、用四个维度来进行设计,如下:

• 收:数据的收集。目前主要支持基于DC、TDBank数据通道上报。
• 算:计算层。针对不同的数据类型,定义不同的计算模块。不同的计算模块,采样不同的技术方案来实现。例如对于物品池子此类分钟级更新要求的数据,我们采用sparkstreaming,而对于用户行为实时反馈等类数据,我们采用spp实时处理类服务器框架。设计中屏蔽掉用户对于底层实现的细节。
• 存:存储层。针对不同的数据规模及访问频率,神盾采用不同的存储介质来满足数据存储的要求及对线上服务延迟的要求。例如对于物品类特征、池子类数据,神盾采用自研的SSM系统,而对于用户类特征,数据量较大、存储访问实时性要求也较高,我们选型为公司的grocery存储组件。
• 用:使用对接层。通过Quicksilver计算得到的数据,我们均通过神盾产品化来配置管理,降低对于数据使用的门槛,最终可以通过配置,直接与线上的召回、精排、重排、规则等计算单元进行打通使用。

以上为Quicksilver整体架构实现图,主要分为近线系统及在线学习系统。下面详细介绍。
近线系统
近线系统主要为了满足以下几类细分需求:
• 实时召回:
Quicksilver处理物料,经过各通道后到线上 (要求秒级,实际分钟级)
• 实时因子:
Quicksilver统计计算,经过各通道后到线上(分钟级)
• 实时特征:
统计型(物料、行为、场景):Quicksilver计算,经过各通道后到线上(分钟级)
实时特征(用户):实时特征构造引擎构造,构造后直接对接线上(秒级)
于是,在选型上,我们针对不同的数据计算模式,选择不同的计算平台,对于统计类型数据,我们选择sparkstreaming来作为我们的计算平台,对于实时性要求较高的数据,如实时反馈类,我们采用spp来进行平台型封装。
数据批处理

数据批处理是基于sparkstreaming实现,如上,有几点说明:
1、对于使用者来说,采用api接口封装,下层通信等均透明化处理。用户只需在处理不同的数据时,选择不同的接口即可,如物品池子接口,特征接口等。使用PB协议进行下层数据通信。
2、底层数据生成后,使用kafka进行缓存。
3、数据线上使用时,统一在神盾产品化上进行配置管理,降低运维成本。
数据实时处理

数据实时处理是基于spp server实现,如上,有几点说明:
1、对于用户来说,希望一次转发,多次使用。Quicksilver通过接入层interface来实现,业务只需要转发到统一的对外L5,即可实现数据一次转发,多次使用,如部分业务可能想即进行特征构造,有可以将数据转发到样本构造,在此即可实现。而所有的这些配置,也通过神盾产品化进行配置管理。
2、对于不同的业务,由于数据上报标准不一样,那么如何实现不同的数据上报标准都可以在Quicksilver上使用,这是实际中遇到的挺头疼的一件事。我们将这样的问题拆解成不同的数据标准,转化成神盾统一的上报标准的问题。于是,在实际代码开发中,只需要留出这样的转化接口,不同的业务实现不同的接口,并可以根据配置选择不同的接口,那么即可解决这一的问题,在这里,反射即可以很好解决这一的问题。
在线学习
在线学习有两方面优点,一是充分利用数据时效性,实时跟踪用户对物品的偏好,比如10点钟上线的新游,在11点的推荐结果中就可以反馈出不同用户对新游偏好情况,使得在尽快适应用户偏好同时,提升了apps转化率;二是在线学习前提是标记数据和特征在线拼接,该操作可以在一定程度上缓解模型离线训练资源不足瓶颈。
以某apps推荐为例,面临效果提升瓶颈,我们分析有两方面原因导致,一是数据源红利降低(新增数据源成本越来越高);二是高维线性模型遭遇瓶颈,暴力式特征交叉是LR模型提升特征维数的主要手段,它存在两个问题,一方面,做不同特征之间交叉组合需要一定成本,另一方面,无法穷尽所有交叉组合方式。
面对推荐效果提升瓶颈问题,有三种解决方案,一是继续想办法引入新数据源构建特征;二是充分利用现有数据源,尝试更好特征工程方法,比如Stacking集成或者特征工程自动化;三是考虑充分利用数据时效性,引入在线学习方案,实时跟踪用户对apps偏好变化。
Quicksilver在线学习架构设计如下:

整个系统主要细分为5个小模块:
• 样本采样:根据模型的优化目标支持自定义采样方法,同时在后期也需要将场景特征考虑进来,采样的结果作为实时拼接的输入
• 实时拼接:将实时样本的userid 、itemid的全量特征进行拼接,拼接的结果一方面可以作为离线平台的输入,另外一方面也可以作为特征引擎的输入;
• 特征工程引擎:根据各个在线训练算法的特征配置,从拼接好特征的样本中进行特征选择、特征交叉等操作,并将处理的结果写入kafka消息队列,模型训练和模型评估模块消费消息队列里面的数据进行训练和评估;
• 流式训练:消费kafka里面的样本数据,采用onepass或者minibatch的形式进行模型参数更新;
• 模型评估:对模型训练出来的模型实例,从kafka消费实时样本数据对模型进行auc评估。
下面关于几个较重要模块进行较详细介绍:
样本采样

• 使用spp server实现类map、reduce操作,采样的结果支持存储到kafka或者下一个实时拼接模块。
• 采样规则引擎基于flex/yacc设计实现。
• 所有采样的配置信息,均通过神盾产品化实现管理。
特征拼接

实时拼接服务主要是将样本中包含的物品和用户的“全量”基础特征拼接到一起,为下一步实时特征提供原料。 特征来源有是三个不同的地方:
• 用户特征(包括实时用户特征):目前主要是来自grocery
• 物品特征(包括实时物品特征): 目前主要从SSM中读取
• 场景特征:是在采样的过程中生成。
实时特征拼接后,下一步便是特征工程引擎的环节,目前主要支持内积、外积、笛卡尔积三种模式,在此不详细介绍。
模型训练

• 目前主要实现基于FTRL的lr及fm算法实现,正在调研参数服务器大规模生产环境使用的路上。
• 动态采样:有的算法算法需要控制正负样本的比例,但线上的流式训练与离线的batch不同,不能再训练之前就知道本次训练总样本量是多少,以及正负样本的比例,故需要根据设置的正负样本比例值,根据时间的推移来动态控制,即在训练的过程中动态采样。
• 低特征覆盖:为了提高模型的可靠性,其中方法之一就是在模型中结合场景特征屏蔽掉低覆盖度特征,与动态采样一样,流式训练时,在训练前无法统计提前统计出每个出现的频率,故也需要动态过滤低频特征,此方法不仅可以用在模型启动时,对于新加入的特征同样适用
模型训练后,即效果评估及上线环节,目前主要支持AUC、MAE等主要评估指标,在此不再详细赘述。
对于任何系统设计来说,都不应该脱离实际的应用场景,这是神盾推荐系统一直贯彻的原则。Quicksilver系统也是神盾这么长时间来从实际的业务场景中收集需求、设计、实现的,已经在空间、电竞、手游、动漫、京东等多个业务场景中上线使用,并取得了不错的效果。神盾也不断在实际场景中继续完善、优化其中的相关能力,给业务带来更高的效果提升。
来源:腾讯QQ大数据
更多阅读:
查阅了部分资料,笔者拙见,打标签问题无论是文本、图像和视频,涉及到较多对内容的“理解”,目前没有解决得很好。主要原因有以下一些方面,标签具有多样性,有背景内容标签,细节内容标签,内容属性标签,风格标签等等;一些标签的样本的实际表现方式多种多样,样本的规律不明显则不利于模型学习;标签问题没有唯一的标准答案,也存在一定的主观性,不好评估的问题则更不利于模型学习。
依然笔者拙见,视频打标签问题目前还没有很好的解决办法,也处于探索阶段。方法上主要有以下一些思路:可以从视频角度出发,可以从图像角度出发;可以利用caption生成的思路,可以转化为多分类问题。
直接从视频角度出发,即从视频整体的角度出发,提取图像帧,甚至字幕或者语音信息,进一步处理得出视频标签的结果。Deep Learning YouTube Video Tags,这篇文章提出一个hybrid CNN-RNN结构,将视频的图像特征,以及利用LSTM模型对标签考虑标签相关性和依赖性的word embeddings,联合起来,网络结构如下图。

Large-scale Video Classification with Convolutional Neural Networks提出了几种应用于视频分类的卷积神经网络结构,在网络中体现时空信息。single frame:就是把一帧帧的图像分别输入到CNN中去,和普通的处理图像的CNN没有区别;late fution:把相聚L的两帧图像分别输入到两个CNN中去,然后在最后一层连接到同一个full connect的softmax层上去;early fution:把连续L帧的图像叠在一起输入到一个CNN中去;
slow fution:通过在时间和空间维度增加卷积层,从而提供更多的时空全局信息。如下图所示:

另一方面,为了提高训练速度,这篇文章还提出Multiresolution CNNs,分别将截取中间部分的图像和缩放的图像作为网络的输入,如下图所示:

这篇文章主要研究了卷积神经网络在大规模视频分类中的应用和表现。通过实验,文章总结网络细节对于卷积神经网络的效果并不非常敏感。但总的来说,slow fusion网络结构的效果更好。
从图像角度出发,即从视频中提取一些帧,通过对帧图像的分析,进一步得出视频标签的结果。对图像的分析,也可以转化为图像打标签或者图像描述问题。Visual-Tex: Video Tagging using Frame Captions,先从视频中提取固定数量的帧,用训练好的image to caption模型对图像生成描述。然后将文本描述组合起来,提取文本特征并用分类方法进行分类,得到tag结果。这篇文章对生成的描述,对比了多种不同的特征和多种不同的分类方法。可见,图像打标签对视频打标签有较大的借鉴意义。另一种思路,CNN-RNN: A Unified Framework for Multi-label Image Classification可以看作将图像打标签问题转化为多分类问题。将卷积神经网络应用到多标签分类问题中的一个常用方法是转化为多个单标签的分类问题,利用ranking loss或者cross-entropy loss进行训练。但这种方法往往忽略了标签之间的联系或者标签之间语义重复的问题。这篇文章设计了CNN-RNN的网络结构里,并利用attention机制,更好地体现标签间的相关性、标签间的冗余信息、图像中的物体细节等。网络结构主要如下图所示,主要包括两个部分:CNN部分提取图像的语义表达,RNN部分主要获取图像和标签之间的关系和标签之间的依赖信息。

针对空间部分短视频数据,笔者设计了一个简单的视频打标签的方案,并进行了实验。由于预处理和算法细节的很多进一步改进和完善工作还没有进行,在此只是提出一种思路和把实验结果简单地做个分享。
方法介绍:
整体思路:图片打标签 => 视频打标签
也就是说,对视频提取帧,得到视频中的图片;然后对图片进行打标签;最后将视频中帧图片的标签进行整合,得到视频标签。
1、从图片描述说起:
图片描述典型框架:利用deep convolutional neural network来encode 输入图像,然后利用Long Short Term Memory(LSTM) RNN decoder来生成输出文本描述。

2、在打标签任务中,我们把标签或类别组合,构造成“描述”:
一级类别+二级类别+标签(重复的词语进行去重)
3、利用预训练和强化学习,对训练样本图片和标签构造模型映射。

《Self-critical Sequence Training for Image Captioning》
网络模型有三种:fc model;topdown model;att2in model;模型细节见论文。
一般地,给定输入图像和输出文本target,,模型训练的过程为最小化cross entropy loss(maximum-likelihood training objective):

利用self-critical policy gradient training algorithm:

其中,是reward funtion
![]()
通过根据每一个decoding time step的概率分布进行采样获得,是baseline output,通过最大化每一个decoding time step的概率分布输出获得,也就是a greedy search。论文里提到,利用CIDEr metric作为reward function,效果最好。
4、根据视频帧图片的标签,对视频打标签。具体有两种思路:
记录视频提取的所有帧图片中每一个出现的标签,以及标签出现的次数(有多少帧图片
被打上了这个标签)。按照出现次数排序。
1.将帧图片的最多前n个标签,输出为视频标签。
2.将帧图片中,出现次数大于阈值c的标签,,输出为视频标签。
数据示例:

其中1class表示一级类别,2class表示二级类别。
实验结果示例:
截取一些实验结果展示如下,其中output指模型输出的结果,reference指人工标定的参考结果。


总的来说,游戏类视频的数据量最大,效果较好;但具体不同英雄的视频数据如果不平衡,也会影响算法结果。其他类型视频数据不算太稀疏的效果也不错,长尾视频的效果不行。
总结:
数据预处理、模型结构、损失函数、优化方法等各方面,都还有很多值得根据视频打标签应用的实际情况进行调整的地方。后续再不断优化。方法和实验都还粗糙,希望大家多批评指导。
来源:腾讯QQ大数据
更多阅读:
背景
“尊敬的XXX用户,您的话费已不足10元。为了您的正常使用,请及时充值。”
——移动公司
“温馨提示:XXX先生/小姐,您的住房贷款将于11月5日扣款,请在此账号中存足款项。”
——家银行
就算是在尊敬的称谓,就算是再温馨的话语,还是感觉有些冷冰事故,千里追债。
通信和金融业务,算是每个现代人的“刚性”需求。收到催费通知尚且不爽,何况是偏向娱乐的互联网业务催费通知。如何能让人觉得不突兀,稍微有点打动人心的感觉?以3年前某业务合作案例为例,抛砖引玉,与各位一起讨论从数据角度发现数据规律,同样是让用户付费场景,通过挖掘出不同用户的付费G点,以不同群体推送不同文案与图片的方式实现个性化催费,推动业务增长。
数据探索过程中12个字感悟:大胆想象,敢于尝试,小心验证
7步骤完成整个流程

行动
Step 1:大胆想象
和“传统”垄断行业相比,我们有哪些优势?
有数字化的用户数据。以计算机和网络为框架的服务模式,天然将用户属性和行为数字化并记录下来,变成和营收一样,公司最大的资产。
哪种服务是温度的,能打动人心的?
唯有高端私人定制。不管是葛大爷、白百何电影中的“圆梦方案”,还是大众辉腾使馆区的线下定制中心,均体现出浓浓的顶级个性化的感觉,红尘万千,只为伊人。这不正是互联网服务的终极吗?个性服务,千人千面。然而圆梦方案终究灯亮散场,低调辉腾亦低调隐退。
为什么?粒度太细,难以形成规模效益,导致每一单的成本太高,整体盈利太少。催费如果要做到真正千人千面,投入太高,收益暂时难以评估。所以初期尝试,我们化“点”为“面”,粒度不是每个人,而是某类人。
Step 2:数据发现挖掘点
算法+数据 => 增长点
如何化“点”为“面”,识别人群,在事先没有预期目标的情况下,称手的工具就是聚类算法了。
• 1 算法
聚类算法简单来讲,就是把全部对象按照其特征的距离远近,划分成若干簇。这些簇满足以下条件:
1)一个簇内部对象距离近
2)不同簇对象的距离远

类似于上图显示的效果,中心点为集群的核心,围绕中心点近的一批就是同一个簇。很容易分出来不同类别,不同业务特性的群体。分群体运营,比较容易获得更好的效果。
举个例子,比如某个业务的特征包括以下几类,具体应该如何应用聚类算法呢?

• 2 特征标准化
收集完上述行为数据后,需要对数据做“标准化”处理。标准化方式方法很多,这里做一个简单举例。
为什么要做标准化处理?这涉及到聚类算法K-means的实现原理。K-means是一种基于距离的迭代式算法,它将n个观察实例分类到k个聚类中,以使得每个观察实例距离它所在的聚类的中心点比其他的聚类中心点的距离更小。其中,距离的计算方式可以是欧式距离(2-norm distance),或者是曼哈顿距离(Manhattan distance,1-norm distance)或者其他。以我们初中学的欧式距离为例
![]()
其中为两个对象的对应特征量,比如都是播放时长,单位为秒。同理
为周播放天数。秒的量纲远远大于周播放天数,一首2分钟的歌曲有120秒的播放时长,一周无休播放,也只有7天的播放天数。最终导致播放天数对距离计算影响小,聚类特性偏向播放时长。其他常用的计算距离方法同样存在类似问题,比如:
曼哈顿距离:
![]()
闽科夫斯基距离:
![]()
解决思路在于无量纲化,方法就是标准化。
我们这次采用的是Z-score标准化,公式如下:
其中x为某一具体分数,μ为平均数,σ为标准差。
标准分数可以回答这样一个问题:”一个给定分数距离平均数多少个标准差?”在平均数之上的分数会得到一个正的标准分数,在平均数之下的分数会得到一个负的标准分数。
• 3 聚类结果输出与解释
得到三个有业务意义的簇,在三维空间上的投影如下:(由于业务敏感性,忽略具体描述)

可以看到,每种类别在空间中的位置和集中程度都有区别,我们就根据这些差异总结出上面三种类型的不同特点。接下来依据不同特点做不同的催费方式。
Step 3:产品沟通
与产品沟通,推动方案落地。由于业务关系,这里不做累述
说服产品经验技巧:
• 深知运营痛点,瓶颈点
• 成功案例举证(首个案例,靠个人或团队影响力)
• 算法初探举例
Step 4:线上测试
我们需要一种快速的,低成本的验证方法。在整体流程不变,后台接口不变的约束下,有什么替换图片与文档的方法更快速,风险和成本更低呢?通过多次迭代优化,所以最终效果如下:通过改变紫色框中的图片与红色框中的文案,对不同用户群体进行不同图片与文案触达

Step 5:效果跟踪与评估
7天流量灰度测试的结果如下:
• 1 常规的线上实际转化效果对比
衡量指标:成功发送催费消息到支付成功转化率均值
炫耀型:x1% 享受型:x2% 扮酷型:x3% 参照组:c1%
x2 > x1 > x3 > c1
• 2 因素影响显著性论证
好了,看到实验组的均值高于参照组,说明有效果。扩大灰度、发邮件、收工了?那么问题来了,如何知道上述效果是个性化文案导致的,还是环绕周围的随机性造成的?
将这个问题转换为统计学的问题,实验组和参照组的均值差异是显著的?
我们可以使用方差分析来尝试解答。方差分析(Analysis of Variance,简称ANOVA),又称“变异数分析 ”,是R.A.Fisher发明的,用于两个及两个以上样本 均数差别的显著性检验 。
工具我们使用喜闻乐见的R,套路如下:

由此我们可以大致认为,不同组的均值差异受不可控随机因素影响的可能性小,差异来自可控因素,基于用户行为的个性化文本的影响。
Step 6:自动化运营
用户数据+模型例行化,各接口联调,部署上线
Step 7:效果监控
通过邮件,短信,QQ,微信等各种形式对效果进行长期监控,关注变化情况及时优化。
[1]. Z-score
http://baike.baidu.com/link?url=n2HbtKxAC_wAyGEJMN-D7wwZNg2B3-dFa-0W9W8sAFJWf5BTry5hIAG6RlFWl-zlWNUUJht85XhoLIy4Hg9Gj_
[2]. 归一化
http://baike.baidu.com/link?url=egN4K40qIsxRxknS6uvOlL63MFGx5LCUq12ojBI-3caMRCYAM5WihO_o2t6vHP0rQKfyei-LKVuN7kbg4HExRK
[3]. K-means
http://www.cnblogs.com/bourneli/p/3645049.html
[4]. 方差分析
http://baike.baidu.com/link?url=-OkUo0mu0bfo9-F9PjvVXR5rdk02I16lJT3UHXDy0I66je4e0t2s-8dpAHW6FxYWf8m36hP-Bs69CJMH-MUJ-lyrRtqbKB9nFQZ0qregXmNvqO0deQNEOT4w_RJ9EaNw
来源:腾讯QQ大数据
更多阅读:
场景分析:
推荐场景一般可以抽象为:内容(Item)和受众(User),其中内容主要是指要推荐的Item,在购物场景中Item就是商品,歌曲推荐中Item就是歌曲,受众是访问当前场景的用户,一般是自然行为人;推荐模型一般是计算不同的User-Item对的得分,这个得分反映的是用户点击当前物品的概率,获取得分最高的Top n的Item推荐给用户,所以整个特征关联模型可以抽象为如下图-1所示:

图-1 推荐系统关系模型
其中,可以分解为如下几部分:User-Item特征、User特征、Item特征、User-Item属性分布特征,下面具体阐述每种特征的构造方法。
User-Item特征:
User-Item特征主要从三个维度来刻画User对Item的“兴趣”,如图-2所示:

图-2 User-Item类型的特征构造
1)时间序列上的统计特征:
统计特征从四个角度(绝对值,相对值,是否感兴趣和深度感兴趣)来刻画User对Item的“兴趣”。比如,时间序列中User累积对某个Item的行为次数就是User对Item的绝对兴趣值:如果时间序列分为:一天、三天、一周(实际中时间还需要继续拉长一点来刻画用户长期的兴趣),行为是“点击”。那么这一个特征构造语句就可以翻译成三个不同的特征:分别是最近一天,三天和七天用户对每个Item的点击次数;时间序列上User对Item是否有重复的行为用来刻画和区分哪些Item是对User有深度吸引力的,如果在一段时间上只发生了一次行为,那么很可能User对这个Item并没有兴趣,只是随便看看;时间序列上User对Item是否有行为,用来刻画User过去某一段时间用户的关注点在哪里,对哪些是可能喜欢的,和上面的一条特征的区别在于可以涵盖用户可能比较感兴趣的Item并且这样用户兴趣特征也会更加丰富。
2)时间特征:
时间特征从三个角度(最近时间,行为频度,行为稳定性)来刻画用户对于Item的兴趣在不同时间上的活跃度。比如,User对Item的最后行为时间,可以翻译成一个时间特征,可以将这个时间进行归一化为一个0—1的标量,越接近于1表示User对这个Item具有越强的新鲜度;User对某个Item的平均行为时间间隔用来刻画User对Item的活跃频率,时间间隔越小说明对用户的吸引力越大。User对Item的行为时间间隔方差可以用来刻画User对Item的喜好的稳定性。
3)趋势特征:
趋势特征主要刻画用户对某个Item的兴趣趋势。比如,User一天对Item的行为次数/User三天对Item的行为次数的均值,表示短期User对Item的热度趋势,大于1表示活跃逐渐在提高;三天User对Item的行为次数的均值/七天User对Item的行为次数的均值表示中期User对Item的活跃度的变化情况;七天User对Item的行为次数的均值/ 两周User对Item的行为次数的均值表示“长期”(相对)User对Item的活跃度的变化情况。
User特征:
User特征主要包括用户的属性特征以及从多个方面刻画用户的“活跃度”,User类型的特征构造方法如图-3所示:

图-3 User类型的特征构造
时间序列的统计特征:
主要从三个维度(User总活跃,用户深度活跃,用户对于Item的覆盖度)来刻画用户的活跃。比如,时间序列上User行为次数总和,在划分成三个时间细粒度的情况下,可以翻译成三个特征,分别是一天,三天和七天User的行为总和,来表示User在当前时间段上的活跃。时间序列上User重复行为次数用来刻画用户真实的活跃深度。时间序列上User有行为的Item的数量,可以用来刻画用户的活跃广度,来表示用户是否有足够的意愿尝试新的Item。
1)时间特征:
主要从三个角度(最近时间,行为频度,行为稳定性)来刻画用户的活跃度。比如,User最后行为时间,时间越接近当前时间说明User的活跃度越强;User的平均行为时间间隔用来刻画User的活跃度,时间间隔越小说明User的活跃度越强。User的行为时间间隔方差可以用来刻画User活跃的稳定性。
2)趋势特征:
趋势特征用来刻画User的活跃趋势。比如,User一天的行为次数/User三天的行为次数的均值,表示短期User活跃趋势,大于1表示活跃逐渐在提高;三天User的行为次数的均值/七天User的行为次数的均值表示中期User的活跃趋势;七天User的行为次数的均值/ 两周User的行为次数的均值表示“长期”(相对)User的活跃趋势。
3)属性特征:
主要用来刻画用户的一些属性特征包括性别、年龄、学历以及使用机型等。
Item特征
Item特征主要包括Item的属性特征以及从多个方面刻画Item的“热度”,Item类型的特征构造方法如图-4所示:

图-4 Item类型特征构造
1)时间序列的统计特征:
从三个维度(Item的行为热度,热度趋势和时间间隔)来刻画Item的热度。比如,时间序列上Item行为次数总和,在划分成三个时间细粒度的情况下,可以翻译成三个特征,分别是一天,三天和七天Item的行为总和,来表示Item在当前时间段上的热度。时间序列上Item被重复点击次数用来刻画Item真实的热度深度,尤其在APP的推荐上,重复的使用或者点击说明当前APP对用户的吸引力越强。时间序列上和当前Item发生行为的User的数量(去重)刻画了Item的热度的广度。时间序列上Item的点击和曝光的比值(User不去重)—CTR,刻画了Item在相同曝光下被点击的概率。时间序列上Item的点击和曝光的比值(User去重)—CTR,刻画了Item在相同曝光下被点击的概率,剔除了某些特殊情况某个User对某个Item的行为过于集中的情况。
2)时间特征:
主要从三个角度(最近时间,行为频度,行为稳定性)来刻画Item的热度。比如,Item最后行为时间,表示Item的最近活跃;Item的平均行为时间间隔用来刻画Item的热度,时间间隔越小说明的热度越高。Item的行为时间间隔方差可以用来刻画Item热度的稳定性。
3)趋势特征:
主要刻画Item的热度和CTR的趋势。比如,Item一天的行为次数/Item三天的行为次数的均值,表示短期Item的热度趋势,大于1表示热度逐渐在提高;三天Item的行为次数的均值/七天Item的行为次数的均值表示中期Item的热度趋势;七天Item的行为次数的均值/ 两周Item的行为次数的均值表示“长期”(相对)Item的热度趋势。另外一种特征表示CTR的趋势:其中一天的Item的CTR / 三天Item的CTR表示“短期”Item的CTR趋势信息。
4)属性特征:
主要用来刻画Item的一些属性特征主要包括所属的类别。
User和Item之间的属性分布特征:
主要通过计算在不同时间段上User和Item之间的行为的统计特征:如果当前的User的属性包括:性别、年龄和Device,Item的属性包括:Item_id和类别,那么特征构造方法如图-5所示:

图-5 User和Item之间属性分布特征构造
1)时间序列上Item在Age的分布特征:
通过计算Item在年龄段上的行为数量(User不去重和不去重)来刻画Item在不同年龄段上的热度;Item在年龄段上的行为数量/Item总的行为数量来表示User在年龄上的热度分布;Item在不同年龄段上的点击和Item在相应的年龄段上的曝光之间的比值来刻画Item在不同的年龄段上的CTR。
2)时间序列上Item在Gender的分布特征:
通过计算Item在性别上的行为数量(User不去重和不去重)来刻画Item在不同性别上的热度;Item在性别上的行为数量/Item总的行为数量来表示User在性别上的热度分布;Item在不同性别上的点击和Item在相应的性别上的曝光之间的比值来刻画Item在不同的性别上的CTR。
3)时间序列上Item在Device的分布特征:
通过计算Item在不同Device上的行为数量(User不去重和不去重)来刻画Item在不同Device上的热度;Item在不同Device上的行为数量/Item总的行为数量来表示User在Device上的热度分布;Item在不同Device上的点击和Item在相应的Device上的曝光之间的比值来刻画Item在不同的Device上的CTR。
4)时间序列上User在ItemType上的分布特征:
通过计算User在不同的ItemType上的行为数量来刻画Use对不同的ItemType的喜好,计算User在不同的ItemType上是否有行为来刻画在时间段上User是否对当前的Item的类型感兴趣,计算User的行为在不同的Item上的分布来刻画对不同的ItemType的喜好程度。User在一段时间内,是否在ItemType上有重复行为,来刻画用户是否对当前ItemType深度感兴趣。
5)时间序列上ItemType在Age上的分布特征:
通过计算ItemType在不同年龄段上的行为数量(User不去重和不去重)来刻画ItemType在不同年龄段上的热度;ItemType在不同年龄段上的行为数量/ItemType在年龄段上的用户数量来刻画当前ItemType对这个年龄段的User的吸引程度;ItemType在不同年龄段上的点击和ItemType在相应的年龄段上的曝光之间的比值来刻画ItemType在不同的年龄段上的CTR。
6)时间序列上ItemType在Gender上的分布特征:
通过计算ItemType在不同性别上的行为数量(User不去重和不去重)来刻画ItemType在不同性别上的热度;ItemType在不同性别上的行为数量/ItemType在当前性别上的行为用户数量来刻画当前ItemType对这个性别的User的吸引程度;ItemType在不同性别上的点击和ItemType在相应的性别上的曝光之间的比值来刻画ItemType在不同的性别上的CTR。
上面列举了一些常见属性之间的分布特征,都是User针对Item或者Item针对User的统计分布,这些只是大部分场景中会出现的场景,在具体的业务中可以根据实际可以获取到的属性结合和样本之间的相关性来进行建模。
特征选择:
在实际的业务中,首先需要思考的是如何正确的构建样本对,在恰当的样本对构造的基础上思考和样本标签具有相关性的因素,这些因素包括用户和物品侧,找到这些因素之后才是特征构建,不同的场景和算法情况下需要不同的特征选择:比如说游戏推荐中活跃时长、付费意愿很重要,而弱化了在性别上的分布,因为游戏属于用户粘性比较大的类型,在商品推荐中性别分布和浏览、加购物车行为则同等重要,因为用户的性别和用户之间的兴趣有很强的相关性;对于不同的算法同样也需要不同的特征体系,对于逻辑回归这种解释性很强的线性模型,通常需要根据建模场景选择特征的细粒度,然后生成和样本具有相关性的特征,获取相关性最直接的方法是对特征进行特征交叉,而对于树模型或者FM模型,理论上则不需要进行特征交叉,因为模型本身就具有了特征的交叉能力。总之,合适模型加上适配的特征特征体系才能获得较好的效果。
小结:
特征工程通常在算法调优中占据了大部分的时间,本文旨在通过梳理推荐系统中常用的特征构造方法,实现快速的特征构造。本文主要是面向初涉推荐系统的同学,可以快速构造一些简单有效的特征,同时,本文提到的一些特征构造方法在某些场景下是冗余的,并不能带来新的信息,所以在实际的应用场景中还需要根据需求进行选择。
附录:
整体特征构造框架如图-6所示:

图6 特征构造框架
来源:腾讯QQ大数据
更多阅读:
在最大化流量价值的驱动下,广告平台为广告主提供OCPC/OCPA(目标激活成本出价、目标注册成本出价和目标付费成本出价)这种投放方式几成标配。OCPC/OCPA的核心逻辑在于打通广告平台的曝光,点击,下载以及广告主后端的激活,注册及后续转化的数据通路,从而得以实现对广告投放的自动优化。
下图是媒体广告平台典型OCPC流程:用户在媒体上有点击广告行为时,这个动作被记录下来,上报到媒体服务器,媒体服务器会将这个点击事件同步给广告主的监测服务器,广告主记录下这个点击事件后,当对应的用户发生广告主想要的转化行为(比如激活,注册或者报名等行为)时,广告主就将这个转化信息回调给媒体广告平台。据此媒体广告平台就可以通过对点击用户和转化用户的比对,从而知道具备哪些特征的用户更容易转化。这样就可以在广告曝光的时候,对具备这些特征的人群进行重点定向,从而提升广告效果。

你不应该让OCPC/OCPA的数据长草
但OCPC/OCPA的数据绝不应用仅仅用于广告平台做投放优化,还可以通过对这些数据的分析,发现更多有助于改善广告投放效果的真相。如果过去你或你的团队还没有就这些数据进行分析,那么现在做还为时不晚。下面结合自己团队在OCPC/OCPA数据分析方面的经验给大家一些参考。
分析方向一:OCPC/OCPA可以让你排除那些异常的点击欺诈设备
大部分OCPC/OCPA平台会上报用户点击事件,这个点击事件一般包括用户IMEI信息,通过比对点击设备IMEI和后续的转化数据,你可以从中发现一些过去根本不会关注的问题。比如我们就曾在某媒体的点击上报数据中发现存在大量的无效点击设备ID情况。
我们对这些设备ID持续多天的点击事件和转化行为进行监测后发现,有多达10-20%的点击上报设备每天都在持续地点击我们的广告,但却无任何后续转化行为。很明显,这些设备存在点击欺诈问题,这些设备只能无端消耗你的广告费用,却不会带来任何真实用户。
我们把这些设备统计出来并做成了人群包,在在媒体投放端进行了人群包排除后,效果明显,成本和点击量下降了不少,转化效果提升了几个百分点,反复点击广告却从不发生转化行为的用户设备渐渐少了。
分析方向二:优化广告投放定向
通过对比点击设备和转化设备的画像数据,我们还可以把点击-转化率低的人群画像进行排除,只定向高点击-转化的人群。也可以通过这个指标去发现哪些素材/广告计划表现好或不佳,分析其原因并优化投放策略。
对点击设备进行画像分析的挑战在于很多企业并不拥有对手机设备打标签,识别其人群画像的能力。毕竟如果用户只有点击行为,却没有转化,很多企业就就很难了解其画像信息,这个时候就需要有第三方打标签的服务去补全这个信息。
分析方向三:识别应用商店“劫持”的情况
众所周知,用户在媒体上下载APK安装包时,手机厂商自带应用商店往往会弹出窗口提醒说,这个应用不安全,推荐你下载应用商店的官方安装包。毫无疑问,大部分用户在这种情况下都会选择安装应用商店推荐的包,而不是你放在媒体上投放的那个渠道包。这种情况下,就会导致信息流等媒体的渠道包带来的用户数量被低估,同时也会高估商店的安装数量。
OCPC/OCPA提供的点击设备的数据,可以帮助我们在渠道包归因的基础上,通过点击上报纬度去归因渠道数据。
那么商店拐跑用户带来的影响有多大?我们根据信息流媒体点击上报的设备信息,去跟踪这些点击设备ID最后安装的渠道包发现,在安卓渠道中,有近50%的用户安装了应用商店的包,也就是说如果你用渠道包作为归因,在安卓信息流渠道,你可能会低估数据一半左右。

当然用户也会存在多渠道点击的情况,比如用户可能今天既在媒体A点击你的广告,也可能在媒体B点击了你的广告,但这个情况发生的概率毕竟比较小。比如上图中其他媒体的渠道包数量为5%,我们视为这是一个可以接受的正常数据。
当然也可能存在有些无良信息流广告平台通过撞库的方式,恶意上报不属于本身媒体用户点击的情况。我们在iOS DSP渠道就曾发现过部分DSP渠道靠恶意捏造大量虚假点击设备上报,骗取钱财的情况。信息流上报的点击设备ID是不是该信息流本身带来的可以通过进一步的数据分析去证实。比如看被商店拐走的用户跟没有被拐走的用户行为差异是否非常显著,点击上报事件是否明显超乎寻常的高,点击到转化的时间窗是否正常等等。
分析方向四:识别代理商/媒体混量
通过比对点击上报设备和对应渠道包的转化数据,还有机会抓到代理商/媒体为了让成本看起来好看,而混入的一些没有经过广告平台点击上报的设备情况。如果存在大量的设备未经点击上报,却安装贵司APP,那么很大可能是你们这个渠道包被灰产拿去刷流量了。当然随着对方越来越高明,这种明显的差异应该会减少,但我们相信,目前还是会存在的。

关于OCPC/OCPA的数据,我们目前挖掘到的信息就这么一些,不知道业内各位大神,还从中发现了什么好玩的情况?欢迎交流。
更多阅读:
但是也不用太难过。因为即便是那些大名鼎鼎的经济学家、或者以洞察市场而著称的企业家、制定国家政策的官员们,他们看似天天跟数字打交道,把数据解读得头头是道,但是说实话,他们对数据的理解水平,可能也比我们高不到哪里去。

不久前出版的这本《真相:我们对世界充满误解的十个原因,以及为什么这个世界比你想象的要好》(Factfulness: Ten Reasons We’re Wrong About the World-and Why Things Are Better Than You Think),作者Hans Rosling是世界知名的医疗健康专家,他擅长通过借助不同领域的交叉数据,来对世界上的各类复杂问题进行解读。Hans Rosling在TED上的演讲非常受欢迎,比尔·盖茨夫妇都是他多年的粉丝,《真相》这本书被盖茨认为是2018年最重要的一本书。
Hans Rosling受邀参加达沃斯世界经济论坛的时候,他出了几道关于世界经济、人口、健康、教育的大数据题目来考参会的各国首脑、部长、世界500强的CEO们,结果发现他们对于这些问题的认识能力竟然还不如大猩猩们!因为他们的正确率,比大猩猩随机抽取答案的正确率还要低。
下面我们来看看其中几道题,看看你能正确回答几道:
1、下面哪张人口分布图正确地展现了现在全球人口的分布情况?

2、全球现在大约有70亿人,其中0到15岁的儿童占20亿人。到2100年,根据联合国的预测,全球人口会增长到110亿。那么到时候0到15岁儿童会有多少呢?
A:40亿 B:30亿 C:20亿
3、今天全球范围内,包括最富裕和最贫困的国家,能够有条件被接种疫苗的1岁儿童,占全球同龄儿童的比例是多少?
A:20% B:50% C:80%
这三道题的正确答案分别是:A,C,C。你做对了几道题呢?又读出了多少这些数据背后的深意呢?
 这个数字,是解开世界重大问题的密码
这个数字,是解开世界重大问题的密码
第一道题,展示的是目前全球人口的分布图,在Hans Rosling看来,这是解开世界重大问题的pin code(密码)。这道题的正确答案是A,美洲、欧洲、非洲和亚洲的比例分别是1:1:1:4,毫无疑问亚洲已经占据了世界人口的最大比重。从这个角度来说,亚洲是今天全球最重要的商业市场,谁错过了亚洲的经济增长,谁就会在今天的商业竞赛中落伍。
当然,能够看到这一点的人很多,那么你想过因此引申到未来吗?未来的亚洲还是全球最重要的“战场”吗?根据联合国的预测,世界人口到本世纪末会增长到110亿,届时美洲、欧洲、非洲和亚洲的比例分别是1:1:4:5,也就是说美洲和欧洲的人口基本没有变化,新增的40亿人口有30亿在非洲,有10亿在亚洲,届时世界80%以上的人口将生活在这两个地区。
随着这些地区消费能力和经济实力的崛起,非洲和亚洲将成为全球最重要的商业市场。今天主宰全球经济的美洲和欧洲之间的跨大西洋贸易,将会转移到亚洲和非洲之间的印度洋上。有一个数字更为惊人,到2040年,全球最富有的人群里,超过60%将生活在传统的西方世界之外,他们生活在亚洲或非洲。

可能你会觉得这是不是有点太乐观了呢?Hans Rosling借助历史数据,给我们展现了一幅更加丰富的经济变化趋势图。他所生活的瑞典,今天是全球人均收入和福利最好的国家之一,但是就在他出生的上世纪中叶,瑞典的经济发展程度跟今天的埃及没有两样,但是经过半个世纪之后,瑞典已经是全球最发达的国家之一。看看中国和印度,可能我们会有更深刻的感受。1997年,中印两国分别有将近半数的人生活在极端贫困之中(根据国际标准),但是短短20年过去了,印度的贫困人口下降到了12%,而中国的进步更是明显,只剩下0.7%的极端贫困人口。当然,这些数字在未来还会继续下降,同时这些地区的高消费人群还会持续增长。
如果你用静态的眼光来看待今天的所有数据,那么你得到的只是一个个孤零零的枯燥数字,而错过了数字里展示的世界正在发生的变化。
比如,我们今天看非洲,就如同是几十年前西方人看中国和印度一样。你看到的是非洲的贫困和落后,还是从数字的背后看到了这个地方的经济正在出现好转的迹象,人口结构正在变化,十年之后可能有新的机遇呢?

再比如,我们今天看到的美国和欧洲,还跟几十年前甚至十年前我们看这些市场的态度一样吗?当然不一样,美国和欧洲市场已经没有那么大的吸引力了。那么你想过,再过几十年,美国和欧洲的市场是什么样的吗?十年之后的机会,要从今天开始布局。
 卫生巾和小米手机
卫生巾和小米手机
第二个问题,探讨的是全球人口结构的变化,正确答案是C。世界人口在接下来80年里,会增加40亿,但是增加的都是15岁到74岁年龄段的人口,0到15岁的新生人口数量并没有变化。按照比例来看,则是大大地下降了。所以我们都能看到人口老龄化问题愈加严峻,这是人类面临的一大难题,值得重视。但我们如果仅仅只看到老龄化这一个问题,那么显然就太初级了,这道题目里还透露了很多富有深意的数据,值得我们好好挖掘和思考。
Hans Rosling在书里举了一个非常有趣的角度。他从这个数据变化里看到了婴儿出生率的下降。这个很容易理解,因为0到15岁的儿童数量没有增加,与此同时现代社会医术越来越高明,婴儿的生存率大大提高了,所以原因是婴儿的出生率下降了。这背后反映了女性的社会地位和受教育程度的普遍提高,她们不再是生育工具。
只有在贫困和落后地区,女性才会被当作生育工具,她们往往会生很多个孩子。但是一旦这个社会的经济水平、女性受教育程度提高之后,生孩子的个数立刻就下降。Hans Rosling在书里列举的另外一个数字也可以证明:世界范围之内,年龄在30岁的男性平均接受过10年的学校教育,而全球同年龄层的女性,她们平均接受到了9年的学校教育。平均来看,男女差别并没有我们想象得大。

如果你仅仅看到了人口老龄化问题,然后感叹消费市场的萎缩、消费人群的减少,那就大错特错了,因为你忽略了曾经贫穷的国家如今发生的巨大变化,以及当地女性社会地位、教育程度提高带来的消费需求,那么你就错过了一个超级巨型的市场。大约有50亿新兴市场的消费者,他们希望能够用上洗发水、摩托车、手机,甚至是卫生巾,这才是商业决策者们应该从数据背后看到的洞察。
但事实上,能够有如此洞察的人并不多。Hans Rosling曾经参加一个全球女性日用品的年度高层会议,他发现这些CEO们在探讨如何吸引新的消费者、如何提升销量的时候,都仅仅围绕的是他们能够看到的这群消费者。比如他们探讨的是“我们如何能够生产出形状更小的卫生巾,以方便这些女性在度假的时候穿比基尼的时候使用”,“我们是不是要针对女性在不同运动中不同的需求,生产不一样的卫生巾”,“女性都喜欢穿莱卡的紧身裤,我们要不要一款隐形卫生巾来满足”等等。
你是不是觉得这样讨论都似曾相识?CEO们在董事会讨论的话题是:今年我们要推出几款新产品,来满足90后的需求;公司的CMO也许在头疼,我究竟是应该把广告费投给微信上的自媒体公号还是抖音的网红;销售部门的老大们正在勒令手下们研究竞争对手的策略,制定出更加有吸引力的折扣价格,或者想更多新点子提高客单价……
 当他们绞尽脑汁地迎合已经非常成熟的市场里的客户们的时候,广大亚洲和非洲的女性,她们正在从生孩子的繁重负担中解脱出来,她们需要的是物美价廉的卫生巾产品,而不是穿紧身裤需要的隐形卫生巾,这些女性的数量多达数十亿人,远远超过今天美国和欧洲女性数量的总和。
当他们绞尽脑汁地迎合已经非常成熟的市场里的客户们的时候,广大亚洲和非洲的女性,她们正在从生孩子的繁重负担中解脱出来,她们需要的是物美价廉的卫生巾产品,而不是穿紧身裤需要的隐形卫生巾,这些女性的数量多达数十亿人,远远超过今天美国和欧洲女性数量的总和。
我在去印度之前,怎么也没办法想象小米、OPPO、vivo等中国手机厂商竟然会把印度市场放在甚至比中国市场更重要的位置上。去了之后才发现,相比较于中国智能手机市场增长放缓、市场饱和,印度市场简直就是一片蓝海。
印度满大街都是中国手机品牌广告和手机专营店,真是很有一种来到中国三四线城市的感觉。小米,vivo,OPPO等,几乎每个印度人都认识。小米公司最近正在上市,招股说明书上一大亮点就是小米在印度的表现非常抢眼。
当然,这并不是说商业决策者们需要赶紧扩展,进行国际化,去占领更多的潜在市场,而是需要对数据进行更加深入的思考,尤其那些看似不相关的数据,包括人口变化、经济增长指标、教育水平、儿童疫苗注射率等等诸多方面。仅仅是在中国市场,我们也能够从这些数据里看到很多新的投资机会和很多商业风险。

Hans Rosling的建议是,不论从事什么行业,是否具有决策权,都需要有一个以事实为基础的更大格局的世界观,这样数据在你的眼里不仅仅是单调乏味的数字,你其实能从所有人都看到的数字里看到不一样的东西。
 儿童疫苗和小龙虾
儿童疫苗和小龙虾
第三道题的答案是C,80%。可能你会小小地惊讶一下,哦,原来全世界这么多的1岁儿童都能够接种疫苗了,然后可能就没有然后了。但是Hans Rosling绝对没有就此停步。他从全世界绝大多数儿童都能够接种疫苗的这个公开数据里,发现了很多深刻的洞察。其中一点就是,他看到了全球冷链物流的成熟。
疫苗这个东西,并不是普通的商品。它的配送要求非常严格,从出厂到注射到孩子身体里,整个过程都需要经过严格的冷链保存。配有冷库的卡车把疫苗千里迢迢送到非洲边远地区的防疫站,然后被保存在防疫站的冷柜里,此后在一定的时候内给孩子接种。整个过程,需要的是完善的公路基础设施、电力配套设施,甚至是当地的经济条件、教育和医疗等等都要相对完善。
这背后还有一个数据可以印证:全球80%的人口已经在不同程度上使用到电力了。两个数字背后,意味着巨大的机会:能够通过冷链物流配送疫苗,就可以配送其他任何商品、食品、消费品,整个地区的经济基础已经有了一定的水平。也就是说,当我们刻板印象里,觉得非洲人民还处于水深火热的苦难之中,谁能想到他们都已经具备了配送小龙虾的全球冷链物流系统呢!
你觉得只有你爱吃小龙虾,非洲人民要么吃不起,要么不爱吃,但事实上,并非如此。Hans Rosling在书里介绍了一个非常有趣的研究。实验人员在全世界超过50个贫富差距、文化、信仰各异的国家里,调查了一共300户居民,他们的收入水平相差很大,背景也各不相同,然后得出了一个重要结论:影响人们生活方式的主要因素不是他们的宗教信仰,文化或居住的国家,而是他们的收入。
在非洲最贫穷的国家,你去当地最富裕的家庭,会看到他们家里的陈设跟美国、欧洲收入相当的人群家中的情况差不多。你去富裕的国家,看到最贫困的那些人,他们的生活条件有时候还远不如非洲落后国家的一般收入阶层。也就是说,这些目前落后、贫困的地区,一旦他们具备了消费升级的条件,他们就会有很强烈的升级意愿。
贫穷并没有限制他们的想象力,而只是暂时压制了他们的消费愿望。一旦条件成熟,他们可不会仅仅满足于用冷链物流运送疫苗,而是希望有更多的事情可以做。

所以Hans Rosling的建议是,作为商业决策者和政策制定者,你真的要多去想想数字背后的现实逻辑,能看到数据反映的各种反常现象,那绝对就能发现新的洞察和巨大的商业机会。
以上只是Hans Rosling《真相》这本书的一部分有趣的案例和故事。但是很可惜,这也是Hans Rosling出版的最后一本书,他本人在这本书正式出版之前不久去世了。在这本书里,他一共讲了十个原因阻碍了我们正确地洞察数据、了解世界,分别是:鸿沟思维、消极思维、直线思维、恐惧思维、规模思维、笼统思维、命中注定思维、急切思维、责怪思维、单一视角思维。不仅是对那些手握权力资源、可以决定一方政策的官员,或者是在全球拓展、寻找商业机会的企业家投资人,对于我们这些普通老百姓来说,能够读懂数据、了解数据背后隐含的各种联系、看到数据展示的未来趋势,都是至关重要的。
Hans Rosling一生致力于改变大部分人脑海中已经预设的对数据的各种判断,希望更多的人能够摒除先入为主的意识,客观地解读数据,从而做出更多更好的决策,造福更多的人,同时让世界少一点“统计文盲”。
来源微信公众号ID:qspyq2015
更多阅读:
1 问题
1.1 某业务拉新场景—冷启动决策问题
拉新场景是指在大流量业务场景中投放拉新业务的相关优质内容,从而吸引用户访问,快速增加用户量。这个拉新场景需要从4千+专辑池(每日会加入一些新的物品)中挑选出两个专辑投放给用户,使用这两个专辑来吸引新用户,从而达到拉新的目的。由于是投放给新用户,所以没有历史行为数据作为依据去推测该用户喜欢什么。能够依赖的数据包含专辑本身的特征,如:分类信息、更新时间等,用户的画像数据(达芬奇画像维护和挖掘了用户的基本画像数据),如:年龄、性别、地域等。开始时,我们使用传统的机器学习模型,如LR、FM等,将每日拉新用户量做到了5千-1.1万。这里存在的问题是,传统机器学习非常依赖正负样本的标注。对于某些新物品,如果它从来没有被曝光,那么它永远也不可能被标记为正样本,这对于新物品来讲是不公平的,也是推荐领域不愿看到的现象。一种比较直接的做法是,保留一股流量专门用来做新物品的探索,但是这里又会有一些新的问题产生,如:这股流量用多大?探索的时机该怎么把握?新物品中每一个物品曝光多少次、曝光给谁是最合适的?如何保证整体收益是最大的, 等等一系列问题,而MAB(Multi-armed bandit problem,多臂老虎机)方法正是解决这类决策问题的。所以我们尝试使用MAB的思想来解决新用户和新物品的推荐问题。事实证明,该方法是可靠的,使用MAB中的UCB算法之后,该拉新场景每日拉新量提高到最初base的2.3倍。
1.2 短视频推荐结果多样性控制
短视频推荐场景的特点是在保质的前提下,需要向用户推荐有创意、多样的、新鲜、热点等不明确讨厌的短视频。从直观的体验结合相关流水统计分析来看,用户非常反感连续推荐同一主题的短视频,所以需要使用一定的策略来对多样性进行控制,提高用户体验,尽可能把用户留下来。在腾讯内部某短视频推荐场景中,我们使用MAB中的Exp3算法来进行多样性控制。事实证明,Exp3用在探索新用户的兴趣场景下,与随机、Thompson sampling等方法对比,视频平均观看时长提升了10%,对于老用户增加了推荐结果的多样性,视频平均观看时长略有提升。
2 神盾如何解决拉新场景的冷启动问题
2.1 MAB如何解决决策问题
在说明神盾如何解决冷启动问题前,这里先对MAB问题做一个综述性的介绍。
什么是MAB问题?
MAB的定义非常有意思,它来源于赌徒去赌场赌博,摇老虎机的场景。一个赌徒打算去摇老虎机,走进赌场一看,一排排老虎机,外表一模一样,但是每个老虎机吐钱的概率可不一样,他不知道每个老虎机吐钱的概率分布是什么,那么想最大化收益该怎么办?这就是MAB(多臂赌博机)问题。怎么解决这个问题呢?最好的办法是有策略的试一试,越快越好,这些策略就是MAB算法。
推荐领域的很多问题可以转化为MAB问题,例如:
1. 假设一个用户对不同类别的内容感兴趣程度不同,那么我们的推荐系统初次见到这个用户时,怎么快速地知道他对每类内容的感兴趣程度?这就是推荐系统的用户冷启动问题。
2. 在推荐场景中,往往会有多个算法或模型在线上做A/B Test,一般情况下我们会把流量按照一定比率来进行分配,而在不同的时间点,不同的算法线上效果往往是不一致。我们期望每时每刻都能把占比大的流量分配给效果最好的算法。有没有比A/B Test更合适的流量分配方法来让业务的收益最大化?
可以看到全部都属于选择问题。只要是关于选择的问题,都可以转化成MAB问题。在计算广告和推荐系统领域,这个问题又被称为EE问题(Exploit-Explore问题)。Exploit意思是,用户比较确定的兴趣,要尽可能的使用。Explore意思是,要不断探索用户新的兴趣,否则很快就会越推越窄。
MAB的数学表述:
- A.设共有k个手柄(对应拉新场景中的k个专辑)
- B.k个手柄的回报分布<D1,D2,D3……Dk>(对应拉新中,专辑推荐带来的新用户量的分布情况)
- C.回报均值 u1,u2……uk(对应每一个专辑在以前的实验的平均收益)
- D.回报方差 v1,v2……vk(对应每一个专辑每一次实验收益的稳定性)
- E.最佳手柄平均收益

- F.T轮之后的Regret值 ,使用一定的算法策略使得其T轮之后最小

Rt是后悔值,T表示实验轮数,u*最佳手柄平均收益,ut表示t时刻,所选手柄的收益
MAB问题目前常用算法:
1. 朴素选择算法:其思想是对于每个手柄都进行k次实验,选择出平均收益最高的手柄。在之后的所有手柄选择中都选择这个最好的。
2. Epsilon-Greedy算法(小量贪婪算法):每一轮在选择手柄的时候按概率p选择Explore(探索),按概率1-p选择Exploit(历史经验)。对于Explore,随机的从所有手柄中选择一个;对于Exploit,从所有手柄中选择平均收益最大的那个。
3. Softmax算法:该算法是在Epsilon-Greedy算法的基础上改进的,同样是先选择是Explore(探索)还是Exploit(原有)。对于Exploit阶段,与Epsilon-Greedy算法一致。对于Explore,并不是随机选择手柄,而是使用Softmax函数计算每一个手柄被选中的概率。armi表示手柄i,ui表示手柄i的平均收益,k是手柄总数。

4. UCB(Upper Confidence Bound)算法:通过实验观察,统计得到的手柄平均收益,根据中心极限定理,实验的次数越多,统计概率越接近真实概率。换句话说当实验次数足够多时,平均收益就代表了真实收益。UCB算法使用每一个手柄的统计平均收益来代替真实收益。根据手柄的收益置信区间的上界,进行排序,选择置信区间上界最大的手柄。随着尝试的次数越来越多,置信区间会不断缩窄,上界会逐渐逼近真实值。这个算法的好处是,将统计值的不确定因素,考虑进了算法决策中,并且不需要设定参数。在选择手柄时,一般使用如下两个公式进行选择:

t表示t时刻或者t轮实验,arm(t)表示t时刻选择的手柄, ui均值表示手柄i在以前实验中的平均收益,ni表示手柄i在以前实验中被选中的次数。α是(0,1)为超参数,用以控制探索部分的影响程度。

“选择置信区间上界最大的手柄”这句话反映了几个意思:
如果手柄置信区间很宽(被选次数很少,还不确定),那么它会倾向于被多次选择,这个是算法冒风险的部分。
如果手柄置信区间很窄(被选次数很多,比较好确定其好坏了),那么均值大的倾向于被多次选择,这个是算法保守稳妥的部分。
UCB是一种乐观的算法,选择置信区间上界排序。如果是悲观保守的做法,是选择置信区间下界排序。
5. Thompson sampling:该算法跟UCB类似,Thompson sampling算法根据手柄的真实收益的概率分布来确定所选手柄。假设每个臂是否产生收益,其背后有一个概率分布,产生收益的概率为p。不断地试验,去估计出一个置信度较高的概率p的概率分布就能近似解决这个问题了。 假设概率p的概率分布符合beta(wins, lose)分布,它有两个参数: wins, lose。每个臂都维护一个beta分布的参数。每次试验后,选中一个臂,摇一下,有收益则该臂的wins增加1,否则该臂的lose增加1。每次选择臂的方式是:用每个臂现有的beta分布产生一个随机数b,选择所有臂产生的随机数中最大的那个臂去摇。
以上算法优缺点:
1. 朴素选择算法需要为每一个手柄准备合适次数的实验,用以计算每个手柄的平均收益,并不适合物品快速迭代的场景,同时会浪费大量流量。
2. Epsilon-Greedy算法与Softmax算法有一个很明显的缺陷是它们只关心回报是多少,并不关心每个手柄被拉下了多少次。这就意味着,这些算法不再会选中初始回报特别低的手柄,即使这个手柄的只被测试了一次。而UCB算法,不仅关注回报,同样会关注每个手柄被探索的次数。Epsilon-Greedy and Softmax的特点,默认选择当前已知的回报率最高的手柄,偶尔选择那些没有最高回报的手柄。
3. Thompson sampling。UCB算法部分使用概率分布(仅置信区间上界)来量化不确定性。而Thompson sampling基于贝叶斯思想,全部用概率分布来表达不确定性。相比于UCB算法,Thompson sampling,UCB采用确定的选择策略,可能导致每次返回结果相同(不是推荐想要的),Thompson Sampling则是随机化策略。Thompson sampling实现相对更简单,UCB计算量更大(可能需要离线/异步计算)。在计算机广告、文章推荐领域,效果与UCB不相上下。
LinUCB算法:
以上介绍的MAB算法都没有充分利用上下文信息,这里所说的上下文信息包括用户、物品以及其他相关环境相关的特征。而LinUCB算法是在UCB算法的基础上使用用户、物品以及其他相关环境相关的特征来进行UCB打分。LinUCB算法做了一个假设:一个Item被选择后推送给一个User,其回报和相关Feature成线性关系,这里的“相关Feature”就是上下文信息。于是预测过程就变成:用User和Item的特征预估回报及其置信区间,选择置信区间上界最大的Item推荐,然后依据实际回报来更新线性关系的参数。
相关论文中(见附件)提出两种计算办法,这里将论文中算法伪代码贴出来,方便大家阅读,详情请查阅附件论文。


2.2 神盾推荐如何使用UCB来解决拉新场景推荐问题
神盾在UCB算法的基础上,尝试为其添加上下文环境信息,该环境信息主要包括用户画像、物品画像、环境信息(时刻,节假日,网络环境)等,因此将其命名为PUCB(Portrait Upper Confidence Bound)。该算法包括两部分,第一部分使用用户已有的行为数据生成物品在某些画像特征下的UCB得分(该分数综合考虑物品的历史平均收益和潜在收益)。第二部分使用预训练好的分类器,在对user-item pair打分时,将原有特征值替换为UCB打分,然后计算最终的打分。
UCB打分
数据准备阶段

图 1 神盾PUCB-数据准备阶段示意图
该阶段的目的是确保使用用户行为数据和画像特征数据生成所需时间窗口下的【画像,物品ID,行为统计数】。这部分神盾在实现时,考虑了一些容错机制,如:当历史时刻数据不存在时,是否可以根据已有时刻的行为数据和已有时刻的【画像,物品ID,行为统计数】统计数据来重新生成等等。
统计打分阶段
使用公式6,基于时间窗口内的数据,采用一定的衰减策略来计算ucb分。对某一物品某种画像进行ucb打分。其中i表示物品ID,j表示画像特征MD5编码,cij 表示t时刻j特征编码的物品i的点击量,Cij 表示历史时刻j特征编码的物品i的点击量,λ表示新行为对得分的影响程度,λ越大表示最新行为越大,反之亦然,eij表示t时刻j特征编码的物品i的曝光量,Eij表示历史时刻j特征编码的物品i的曝光量,e为无意义初始值防止分母为0,Thj表示当前时刻j特征编码的物品总的曝光次数,Taj表示历史时刻和当前时刻所有专辑j特征编码的物品总的曝光数,α表示bonus项用于探索物品的权重,α越大越容易出新物品。

是否需要对Cij,Eij,Taj全部进行衰减,如下公式为计算历史数据的公式。d(t)表示t时刻的统计量,d’(i)表示i时刻的实际统计量,f(|t-i|)表示时间衰减函数,θ表示时间衰减参数,新时刻行为的影响越大,就应该跳大θ,反之亦然。


伪代码如下:
doStatistic()
Input: 历史时刻物品-画像曝光点击统计数据hisFirstItemPortraitStatis
(t-w+1, t)时刻物品-画像曝光点击统计数据otherItemPortraitStatis
isUseDefaultValue历史时刻数据是否使用默认值
toolItemID池子所有物品ID
Output: itemPortraitUCBScore ItemID,画像MD5的ucb得分
1 if isUseDefaultValue then
2 向hisFirstItemPortraitStatis补充缺失的物品曝光和点击数据(使用默认值)
3 hisRDD,realRDD←对hisFirstItemPortraitStatis,otherItemPortraitStatis分组合并统计
4 itemPortraitUCBScore ← 使用上述公式计算ucb得分
5 return itemPortraitUCBScore
分类器糅合UCB打分
经过上述处理之后,我们会得到图2所示信息,其中owner列为特征值,primary_key为历史实时行为标记,secondary_key为物品ID,value为统计到的次数。

图 2 PUCB算法中间统计结果-示例图
换句话说,经过上述处理,我们将原始的特征抽象为UCB得分,接下来需要做的事情是使用一定的策略将不同维度的信息糅合起来。论文中使用了岭回归的方式来为每一个特征维度计算权重,神盾这里设计的比较灵活,可以使用任意一种分类器(如:LR、FM等)来糅合最终的结果,需要注意的是该分类器所使用的特征应该跟计算UCB打分的特征体系一致。
3
神盾如何保证短视频推荐场景中的多样性
3.1 exp3多样性保证
Exp3(Exponential-weight algorithm for Exploration and Exploitation)算法是2001年提出来的一种解决MAB问题的算法。它的核心思想是维护一组臂的权重信息,然后使用数学方法得到一组臂的概率分布,接着每次掷骰子去选择臂,根据选择后观察到的收益情况去调整臂的权重,如此迭代下去。论文中证明了使用这种策略能够保证后悔值的在一定可以接受的范围内,从而保证了结果不会是最坏的一种情况。
Exp3算法伪代码如下:

ϒ是一个超参数,值域为[0,1],可以采用固定值,在实验轮数确定的情况下,建议使用公式9来计算ϒ,其中K为臂的个数,T为实验的轮数。

首先为每一个臂初始化权重为1,然后使用算法1步骤中的公式计算每一个臂的概率,该公式保证了所有臂的概率和为1,接着随机出一个[0,1]之间的值,观察该值落在哪个臂中,选择之后观察该臂的收益情况,使用公式11计算其预估收益。

使用公式12来更新权重。

该算法在计算臂的概率时,虽然有可能趋向于0,但是不会等于0,所以对于任意一个臂,都有机会被选中,只是收益高的臂更容易被选中,收益低的臂更不容易被选中。
3.2 神盾推荐如何应用exp3来做多样性控制

图 3 神盾Exp3算法流程
1. 首先规划Exp3的臂策略,最简单的臂策略为不同的召回策略,复杂一些可以按照一定的业务规则来对物品进行重分桶,如:在短视频推荐中按照物品类别信息(游戏、风景、美女等)构建了20+个臂。
2. 在tesla(腾讯内部集群任务调度系统)上配置Spark Streaming任务,这个任务的目的是分钟级消费TDBank业务数据,按照业务规则构建正负反馈数据,然后使用一定的更新策略来更新权重。神盾推荐在这里设计了三种权重更新策略。
a.原版算法更新策略,使用每条反馈数据来更新。这里存在的问题是由于TDBank数据收集,近线训练和线上服务链条较长,近线训练的结果不能非常实时的推送到线上去,存在一定的误差。
b.小batch更新策略,收集一段时间的数据(神盾使用1分钟的数据)对每个臂的收益值做归一化,然后更新算法参数。与a相比,优点是权重更新更加稳定,缺点是收敛速度相对比a缓慢。
c.在b的基础上引入窗口概念,会周期性的使用初始值来重置算法参数。
其他:在实际推荐业务场景中可以依照实际的应用情况,对正负反馈构建,权重更新策略,为每位用户构建Exp3选择器等。
3. 推送计算参数到Kafka Server,更新R2线上算法参数。
4. 神盾推荐在短视频推荐上应用Exp3的结构如下图所示,可以看到exp3被应用在ReRank层,每一个臂都可能被摇到,同时从数学角度保证整体选择的收益肯定远高于最坏情况,进而在保证多样性的同时,整体收益高于最坏收益。

图 4 神盾推荐短视频推荐上Exp3算法结构示意图
4 总结
综合上述场景的实际应用情况,说明在面临用户或物品冷启动的情况时,值得使用PUCB的方法进行尝试,而内容类对多样性有要求的场景,可以尝试使用Exp3来解决。
本文所述MAB方法的经验来自组内所有同事在实际业务中的总结。欢迎大家交流讨论!
参考资料:
exp3数学推导: https://jeremykun.com/2013/11/08/adversarial-bandits-and-the-exp3-algorithm/
Python版demo:https://github.com/j2kun/exp3
https://zhuanlan.zhihu.com/p/21388070
http://blog.csdn.net/scythe666/article/details/74857425
http://x-algo.cn/index.php/2016/12/15/ee-problem-and-bandit-algorithm-for-recommender-systems/
Adversarial Bandits and the Exp3 Algorithm
来源:腾讯QQ大数据
更多阅读:
随着社交网络的发展和积累,内容的产生、传播、消费等已经根深蒂固地融入在人们的生活里。随之内容分析的工作也就走进了人们的视野。近年来,各种公众趋势分析类产品涌现,各大公司都利用自身资源纷纷抢占一席之地。
公众趋势分析平台利用自然语言处理、机器学习方法对数据进行分析,给用户提供舆情分析、竞品分析、数据营销、品牌形象建立等帮助。其中,热点发现问题是公众趋势分析中不可或缺的一部分。热点发现通过对海量数据(本文集中在文本数据方面)进行分析,挖掘相关人群重点关注的内容。
在我们的业务场景中,快速高效地从海量社交短文本中发现出实时的话题,可以帮助产品、运营、公关等同学更好地吸引用户。然而,直接从海量文本中生成语法正确、意思明确的话题,是一件不容易的事情。本文主要介绍在话题生成上运用的一个较为简单高效的方法。
目前很多内容平台的话题收集有相关的产品策略或者运营同事支持。例如让用户自定义话题,并用特定的符号标识,如“#白色情人节#”。在一些文本场景中,没有这些条件支持,而需要我们直接从海量的用户社交文本中提取热点话题,或者说热点事件。本文的目的即是自动从海量社交短文本中,自动发现热点事件或热点话题。
不少相关的工作,将话题提取利用主题分析的方法来解决,利用主题模型(LDA等)、聚类等方法,但这种思路输出的各个话题的一些主题词或者相关词,而不是直接生成话题短语。可以考虑引入事件抽取或者文本摘要的思路来解决这类场景的热点话题提取问题,但其往往需要监督数据。本文介绍一种简单实用的热点话题提取方法的尝试。
本文提出一种从热词提取出发,提取热点话题的方法。下面是方法的整体流程图,首先提取热词,然后在热词的基础上,做话题提取。下面分两部分详细介绍。

主体思路是利用词频梯度和平滑方法。

如上图所示,词语的热度受很多方面的影响。
- 大盘影响:白天和凌晨、双休日和工作日、节假日和平常日子,社交消息的整体数量都会有一个较大的波动。
- 词间影响:也许语料中某个段子突然非常火,会导致一些平时关系不大的词语,一下子全部成为热词。
- 周期影响:24小时、星期、月份、节气等周期性的变化,常常会使得“早安”、“周一”、“三月”等事件意义性不强的词语成为热词。
- 自身趋势:这个就是我们最关心的热度信息了。这些由于事件引起相关词语的突发性、递增性等的增长,就是我们算法想要识别和分析出来的。
针对以上一些影响因素,我们从以下的一些方面进行热词提取工作。
1、预处理:这里主要包括文本去重、广告识别等方法,对数据进行一些去躁的工作。
2、梯度:词频增量的主要衡量指标。

3、贝叶斯平均:一种利用outside information,especially a pre-existing belief,来评价the mean of a population的方法。

贝叶斯平均的典型应用包括用户投票排名,产品评分排序,广告点击率的平滑等等。
以用户投票排名为例,用户投票评分的人很少,则算平均分很可能会出现不够客观的情况。这时引入外部信息,假设还有一部分人(C人)投了票,并且都给了平均分(m分)。把这些人的评分加入到已有用户的评分中,再进行求平均,可以对平均分进行修正,以在某种程度或角度上增加最终分数的客观性。容易得到,当投票人数少的时候,分数会趋向于平均分;投票人数越多,贝叶斯平均的结果就越接近真实投票的算术平均,加入的参数对最终排名的影响就越小。
4、热度分数计算:利用贝叶斯平均对梯度分数进行修正。

这里,公式中的平均词频是贝叶斯平均公式中的C,平均分是贝叶斯平均公式中的m。也就是说在热词提取中,我们用梯度分数的平均分作为先验m,用平均词频作为C。
热词提取中可以这么理解,词语每出现一次,相当于给词的热度进行了评分。
词频少,也就代表了评分的人数少,则评分的不确定性大,需要用平均分来进行修正、平滑。这里可以把一些词频很少的词语的高分数拉下来,例如一个词语今天出现了18次,昨天出现了6次,这里梯度分数就比较高,为0.75,但这种词语其实更可能不是一个热词。
词频大,远大于平均词频的词语,也就代表了评分的人数多。则分数会越趋向于自己的实际分数,这时平均分的影响变小。这是合理的,例如一个本来是百万量级的词语,第二天也出现了一个三倍的增量,这里热度价值就明显提高了。
5、差分:这里主要考虑是要解决热词的周期性影响的问题。具体做法非常简单,比较的时间间隔需包含一些影响较为明显的时间周期。例如按小时统计的热词,最好是拿今天和昨天一个相同的时间点进行比较。
6、共现模型:对于互为共现词的热词,进行一层筛选。
通过频繁项集、word2vector等方法,发现出共现词语的关系。利用共现词语的信息,对热词进行一轮筛选,提取出最有价值的热词,避免信息冗余。
7、时间序列分析:考虑更详细的历史因素。

通过对词频进行时间序列分析,可以更详细地区分短期、长期与周期性热点;对一些更有价值的热词做热度预警;对热词的增长趋势进行分析等等。
综上,我们在周期时间间隔内,通过贝叶斯平均修正的词语梯度分数来分析词语热度,并利用语料中词语的共现信息,进一步筛选得出热词。通过时间序列分析,得出热词的特性和增长趋势等。
提取出了热词,但一个词语对于事件或者话题的表达能力是有限的。这里我们从热词出发,进一步提取出话题。

这里话题提取的工作也分为两步,第一步先找出一些候选的话题词组;第二步利用Attention的思想,从候选词组中找出一个包含的词语更加重要的词组,作为输出话题。
候选词组提取
候选词组的提取主要根据信息熵的理论,用到以下一些特征。
1、 内部聚合度——互信息
这应该从信息熵说起。信息熵是用来衡量一个随机变量出现的期望值,一个变量的信息
熵越大,表示其可能的出现的状态越多,越不确定,也即信息量越大。

互信息可以说明两个随机变量之间的关系强弱。定义如下:

对上式做变换可以得到:

表示Y的不确定度;表示在已知X的情况下,Y的不确定度,成为已经X时,Y的条件熵。则可知表示由X引入而使Y的不确定度减小的量。越大,说明X出现后,Y出现的不确定度减小,即Y很可能也会出现,也就是说X、Y关系越密切。反之亦然。
在实际应用中,词组的内部聚合度即为词语间的内部聚合度。对于一个词组,我们选取使不确定性减少的程度最多的一种词语组合,来说明词组的内部聚合度。
2、 所处语境的丰富程度——左右信息熵
刚刚已经提到信息熵说明了信息量的大小。那么如果一个词组的左右信息熵越大,即词
组左右的可能情况越多,左右的搭配越丰富;则说明这个词组在不同的语境里可讨论的事情越多,越可能可以独立说明一个事件或话题。
3、 是否普遍——这个很直观地可以通过词组出现的频次来衡量。
话题精筛
对于某一个热词,挑选出来一批候选词组后,每个词组所含的词语不同,包含的信息量也不同。比如3月9日对于“巴黎”这个热词,我们提取出来的候选词组有“巴黎球迷”、“巴黎球员”、“淘汰巴黎”、“心疼巴黎”、“巴萨逆转巴黎”、“法国巴黎”、“巴黎时装周”。但“巴萨球员”、“巴黎球迷”、“淘汰巴黎”、“心疼巴黎”、“法国巴黎”这些词组中,“球员”、“球迷”、“淘汰”、“心疼”这些词语在很多其他的语境中也经常出现,它们的指向性并不明确;“法国巴黎”的信息量甚至只有一个地点。而“巴萨逆转巴黎”、 “巴黎时装周”则还包含了更具体的信息——足球比赛、球队、赛果、地点或者时装秀等,事件的指向更明确。这里,就需要我们对候选的话题词组进行筛选。

筛选的主要依据或思想,其实和Attention机制是一样的,关键是要找出重要的词语。比如与“巴黎”的搭配,“巴萨”、“逆转”、“时装周”比“球迷”、“球员”、“心疼”、“法国”包含的信息更多,意义更大。可以想到,“巴萨”、“逆转”、“时装周”这些词语在其他无关语料中不常出现,“球迷”、“球员”、“心疼”、“法国”在不同语料中都常会出现,信息不明确。所以,在我们的问题中,可以通过TF-IDF的思路来确定Attention。
具体说来,就是衡量词组中,各个词语在词组中的特异性。我们有理由相信,“巴萨”、“逆转”、“时装周”这些词语,在含“巴黎”的相关语料中出现的概率较高。热词的候选词组s的事件或话题表示能力分数可由以下公式求得:

其中,N为候选词组中的词语个数,为候选词组中包含的第i个词语,Corpus (w)表示含有词语w的相关语料。
另一方面,我们也需要考虑词组出现的频次,词组出现的次数越多,说明事件越重要。
综上所述,我们通过候选词组的事件或话题表示能力分数以及出现频次,精筛出热词的相关话题。
更多阅读:
本文介绍了神盾推荐系统中基于热传导模型的相关推荐模块. 神盾推荐系统是 SNG 数据中心立身 QQ 大数据构建的通用化推荐平台. 服务于应用宝, 手Q手游推荐, 企鹅 FM 等多个应用场景, 为业务方提升收入, 提高用户体验做出巨大贡献.
神盾的基于热传导模型的相关推荐模块的代号是 “反浩克装甲” (Hulk Buster), 来源于”复仇者联盟2” 中钢铁侠开发用来对抗绿巨人浩克的专用装备. 其以模块化思路设计, 平时运行在近地轨道中, 有需要的时候可以分散投射到战场组合使用.

反浩克装甲
神盾推荐的反浩克装甲起步于应用宝的推荐场景, 其后在企鹅 FM 的相关推荐场景上进行了快速的迭代升级. 最终取得对比原始 ItemCF 超过 25% 的效果提升.
在推荐系统发挥用武之处的各个场景中, 相关类的推荐是一个比较常见的场景. 其要面对的场景可以定义为:用户在找到自己喜欢的东西并进行消费的时候或者消费行为完成之后, 对用户展示一些相关的物品以便用户继续消费.
这可以是电台 app 里面的 “收听过这个电台的用户还听过…”, 也可以是书城里面的 “看了又看”, 也可以是视频网站里面的 “相关视频”. 通过相关推荐, 我们可以为用户提供更好的浏览体验, 并把用户和更多的服务连接起来.

应用宝和企鹅 FM 的相关推荐场景
本文讨论的问题是基于物品相关的解决方案:针对每一个待推荐的物品计算一个相似物品列表, 然后在用户访问的时候, 拉取相似度最高的几个物品用于展示.
这种方法的特点是每个用户的推荐结果是一样的, 是一种非个性化的解决方案. 由于所需存储资源和内容库里面的物品数量相关, 因此好处在于能够节省资源, 避免用户增长带来的成本问题. 而且只要物品相似度模型建好了, 用户体验都能够达到令人比较满意的程度. 但这种方法只适合物品数量不会爆发式增长的场景, 例如应用宝的应用推荐, 或者视频网站的视频推荐. 另外, 其毕竟是一个非个性化推荐算法, 每个用户看到的内容都是一样的, 从而推荐效果存在较低的天花板.
物品相关算法最经典的应该是 ItemCF 算法. 但在神盾的相关推荐场景中, 我们大量使用了周涛1提出的热传导算法, 因为其在我们大量线上实验中获得了更好的推荐效果.
但在此我们更想强调算法背后的复杂网络思维. 这个算法把推荐实例中的用户和待推荐物品的关系类比为二分图, 当用户对物品的行为有操作的时候, 我们就可以在中间连一条线. 通过构建用户 – 物品二分图, 我们可以认为被同一个用户操作过的物品是相互关联的. 这种把问题看做一个图的研究视角, 给我们之后的进一步优化提供了便利.

通过把用户和物品当作网络上的节点的形式, 我们可以更直观的思考推荐
ItemCF 等物品相关算法, 大多都是根据用户的行为利用统计方法计算得到, 并不是根据某个目标函数朝着最优解优化. 在实际的推荐场景中实现某个优化项的时候, 我们通常会面临许多超参数的选择. 例如, 要选择多长时间的用户行为去构建二分图, 或者热传导算法参数的选择. 有时候囿于流量我们可能没有办法把每一个候选集合都试一遍, 因此在实际操作中我们会构建一个离线训练场景, 用于调试新的算法特性, 然后推到线上用 a/b test 去验证.
至于离线场景的构建, 一般是利用用户的实际流水, 看相关推荐的结果是否能够预测用户的下一步行动. 这里的技巧在于, 构建离线训练场景之后需要依此在线上投放几次 a/b test, 以验证线下场景的有效性.
为了获得更精准的推荐结果, 神盾推荐团队在热传导模型的基础上做了大量的努力, 最终得到现在的代号为反浩克装甲的相关推荐模块. 下面介绍该模块的主要特性:
▲ 引入热传导, 调整热门和冷门物品的权重, 平衡推荐的精确度和多样性.
在热传导算法的论文中, 作者强调该算法能够平衡推荐的精确度和多样性, 能够在保证精确度的情况下, 让长尾物品的相关度靠前. 在实际操作中, 我们可以利用算法的参数, 调整 “冷门” 和 “热门” 物品的权重, 从而适应不一样的场景. 例如, 我们发现相比应用宝的 app 推荐, 企鹅 FM 的电台相关推荐应该要用一个更加偏向冷门的权重.

热传导算法1实际上是两种能量传递模式的组合, 一个倾向于推荐流行物品, 另一个倾向于推荐冷门物品. 图片来源2
▲ 用户和物品的链接, 应该是建立在用户真正喜欢这个物品的基础上
在用户 – 物品的二分图上, 边的定义是第一步, 也是最重要的一步. 因为有一些用户操作可能并不代表用户真正喜欢这个物品, 盲目投入用户对物品的所有操作行为, 可能会出现 “Garbage In Garbage Out” 的情况. 因此神盾团队在构建推荐算法时, 会分析先行, 用数据确定什么情况下用户和物品才能够有一条链接.
以企鹅 FM 为例, 我们统计企鹅 FM 用户收听比例 (收听时长/节目总时长) 的分布, 发现用户收听行为主要集中在两类, 一类是收听比例<10%, 一类是收听比例>90%. 我们可以认为, 如果用户收听一个节目不足总时长的 10% 就停止播放了, 那么很有可能他们并不喜欢这个节目, 把这些数据投入算法可能会造成不好的影响, 因此在构建二分图前去掉.
▲ 过滤用户数较低的物品, 让推荐更有把握, 多阈值融合, 保证覆盖率.
如果一个物品只被一个用户喜欢, 按照热传导的逻辑, 这个用户喜欢的其他物品会出现在这个物品的相关列表中. 但这样实际上很容易把不相关的东西联系在一起, 因为一个用户的兴趣可能非常广泛. 因此, 有必要过滤掉一部分用户数较少的物品.

度小于一定阈值的节点将会被被隔离在训练之外, 取阈值为2, Item3 会在训练前被舍去
以用户 – 物品二分图的视角来看, 喜欢某个物品的用户数量, 就是这个物品的度, 在我们看来, 这个度的越大意味着它的推荐结果越有把握. 对物品的过滤, 实际上就是把度较低的物品进行一次过滤.
支持度过滤阈值越大, 对推荐结果的把握也越大, 但是能够获得推荐结果的物品的数量就会越少. 为了保证覆盖率, 可以分别用两个阈值训练出两个模型, 然后用低阈值的结果给高阈值的结果做补充.
▲ 融合用户和物品的属性及不同行为的行为特征, 能提高推荐的覆盖率, 解决冷启动问题, 充分发挥不同特征的数据价值.
在推荐中, 一般除了用户在应用内的行为数据之外, 我们还能够获得其他的一些信息. 例如用户的基础画像, 或者物品的基础信息. 但热传导算法的作者并没有提出如何把多种特征融合到模型中.
这里我们采用了大特征的概念3, 把特征本身当作一个节点加入到二分图中. 例如, 我们可以把企鹅 FM 里面的专辑分类当作一个 “用户”, 专辑对某个分类的隶属关系, 在二分图中可以看做某个分类 “喜欢” 这个专辑. 用户的属性依然, 我们能够把性别(男/女)当作一个物品, 引入到二分图中.

用户的特征被当做一个物品加入到二分图中, 物品的特征则看做一个用户, 此时冷门 Item4 也能获得关联
这样做有一个好处, 就是能够提高推荐的覆盖率, 让一些没有用户操作过的冷门物品(或者新物品)也能够通过物品的基础属性(例如分类)连接起来. 从而能够解决冷启动问题. 但通过简单的推导可以发现, 如果有一个物品没有用户操作行为数据, 只有一个”分类”属性, 那么在热传导算法的推荐结果中, 它会给出同分类最冷门的物品, 也就是另一个没有用户操作行为的物品. 这实际上不怎么合理. 这里的解决办法有二, 一个是引入更多的物品信息, 让物品尽可能多维度的连接起来, 另一个是做物品度过滤.
▲ 利用时间因素, 去掉时间间隔较大的两次用户行为生成的链接.
现有的模型在选定了训练时长后, 会将用户该时间段内形成有效链接的所有物品关联在一起, 这样可能会把一些具有时效性的内容关联在一起. 以企鹅 FM 为例, 用户白天听的 DJ 摇滚和晚上的轻音乐, 躺在床上听的《鬼吹灯》和车上听的交通电台, 都有可能被链接起来.
为了解决这个问题, 我们把用户对物品的操作时间引入到推荐中, 从而让两个物品不再因为时间跨度较大的行为而联系在一起, 这里我们采用的方法是把处在不同时间窗口的用户看做多个节点, 从而强化同一个时间窗口内被操作的两个物品的联系.

用户根据操作日期被看做成多个节点, 从而只有同一天的操作行为会把物品关联起来, 这里 User1 被分割成 9月9日的 User1 和 9月12日的 User1
▲ 可以利用用户对推荐结果的反馈信息, 修正推荐结果.
虽然特征的丰富和模型的优化能够很大的提高推荐的效果, 但我们认为推出看起来不怎么准确的结果仍是很难避免的. 对此我们的一个做法是: 把推荐的结果推给用户, 看看用户是否有点击, 对于用户喜欢点击的物品, 提高它的权重; 对于没有点击的物品, 则降低它在推荐列表中的排序.
为了利用用户的实际行为修正推荐结果, 我们计算了每一个待推荐物品和相关物品的转化率, 然后用转化率对权重进行调整. 而这里需要考虑的是有些相关物品限于槽位并不会被用户看到, 从而无法计算转化率, 这里我们利用了神盾实现的点击转化率平滑4模块, 对点击量过小的物品赋予一个预估的转化率.
▲ 按用户属性分群, 各群分别构建热传导, 开创个性化的相关推荐模型.
在服务资源有限的情况下, 非个性化物品相关推荐能够用较少的资源为海量用户提供服务. 但当资源充足的时候, 我们可以考虑把用户的因素考虑进去. 在神盾推荐系统中, 我们实现了按照用户的基础信息和画像分群投放热传导的推荐逻辑. 具体的思路是针对每个群体训练一个热传导模型, 当用户发起推荐请求的时候, 给出对应群体的推荐结果. 为了发挥 QQ 海量用户画像的价值, 神盾对用户展现的推荐结果, 可以由用户所属不同群的推荐结果进行加权获得
本文介绍了神盾推荐团队这几个月内在相关推荐这个场景下的工作成果. 我们在一个简单的网络的基础上, 构建了一个多层次, 能利用多种数据源的推荐策略. 经过线上数据检验, 这个方法能够获得对比传统 ItemCF 算法超过 25% 的性能提升.
但是相关推荐并不是我们努力把物品更准确的链接起来的唯一目的. 计算物品关联还有其他的用处:
1、物品相关的结果可以直接或者间接的被用于个性化推荐,可以根据用户的历史行为, 找出跟用户历史最为相似的物品, 推荐给用户;也可以把物品相似度看做一个特征, 融入到其他模型中;
2、通过把物品关联起来, 我们可以构建一个物品网络, 对物品网络的分析, 能够让我们更加的了解每一个物品. 例如, 我们尝试把企鹅 FM 的电台通过物品相关构建一个电台网络,在分析中我们发现相似的电台会形成社团, 我们认为这隐含了物品的基础特征.

对企鹅 FM 的音乐分类的物品关联网络进行可视化, 节点大小与被关联次数相关, 颜色为社区发现结果
这两个应用场景, 我们认为将可以有效提升推荐效率以至于我们对用户的理解, 因此非常值得我们进一步探索和研究.
热传导算法是一个利用了复杂系统中热扩散思路计算物品相似度的推荐算法. 该算法的把用户和物品看做两类不同的点, 并把用户和物品的操作看做一条边连起来, 从而生成一个二分图. 算法假定每一个物品都分配了一定的能量, 然后沿着二分图的边, 进行能量的传递, 传递后的能量状态揭示了物品的相关程度.
算法原文探讨了两种能量传递的方法, 可以导出两种不同的物品相似度计算方式:

这里 α和 β是两个物品, aαi=1代表用户 i与物品 α有一条边, aαi=0表示没有. 而 ki=∑αaαi是用户的度, 即连接到用户的边的数目, 类似的 kα为物品的度.
可以看到两个相似度计算方式的差异主要在系数上. kα实际上计算了该物品被多少人操作过, 一定程度上代表了物品的热度. 因此 WαβP的计算方式很好的抑制了物品 α和热门物品的相似程度. 从而会让冷门的物品获得更高的关联得分.而真正的热传导模型, 则是通过引入控制参数 λ来实现兼顾精确度和多样性:

参考文献:
1、Zhou T, Kuscsik Z, Liu J G, et al. Solving the apparent diversity-accuracy dilemma of recommender systems[J]. Proceedings of the National Academy of Sciences, 2010, 107(10): 4511-4515. :leftwards_arrow_with_hook:
2、https://www.zybuluo.com/chanvee/note/21053 :leftwards_arrow_with_hook:
来源:腾讯QQ大数据
更多阅读:
前言
自手Q游戏中心V6.0改版以来,产品形态发生了较大的转变,不再是纯粹通过app列表做游戏分发,而是试图通过内容来带游戏分发,全新的产品形态给推荐算法带来了许多的挑战。截至4月初,算法一期的工作已接近尾声,借此机会写下总结,一方面是将整个游戏中心的推荐逻辑进行梳理,并将其中的一些经验沉淀总结,方便回溯;另一方面也试图在梳理的过程中,整理出遇到的一些挑战,能够更加明确算法二期的一些迭代思路。
背景
手Q游戏中心作为腾讯手游重要的分发渠道之一,既是用户发现感兴趣游戏的重要入口,同时也提供了各手游平台运营的能力。新版游戏中心不再是纯粹地通过传统app列表的方式做游戏分发,而是新增了一系列通过内容(攻略、视频、直播、礼包等)拉下载、拉活跃的场景(如图1所示)。为了更好地提升用户进入游戏中心的体验以及满足平台精细化运营(拉新、拉活、拉付费等)的需求,通过海量用户的行为流水挖掘用户游戏偏好,精准推荐用户感兴趣内容成为了必然趋势。为此,我们设计了全新的个性化推荐框架,给业务带来了显著的转化率提升。

图1:游戏中心个性化推荐场景
为了更好地制定算法二期的迭代计划,本文主要对算法一期的工作做一个简单的复盘,一方面是将项目开展过程中的一些经验进行总结沉淀,另一方面也是想对游戏中心推荐场景中比较有挑战性的问题进行梳理,以便算法二期迭代过程中更加具有针对性。
本节主要结合游戏中心个性化推荐的算法框架(如图2所示)以及工程框架(如图3所示),对项目过程中遇到的一些问题进行总结归纳。游戏中心所采用的推荐框架是业界常见的三段式推荐逻辑:offline—nearline—online。离线层主要负责存储全量用户在游戏中心的流水数据、计算用户长期的行为属性以及训练用户的游戏偏好模型等;近线层主要是为了解决离线层计算周期长,响应速度慢的缺点,通过实时计算用户的短期兴趣,反馈到线上,从而能够对用户在游戏中心的行为做到实时反馈;在线层可以理解为推荐引擎,主要是对业务请求通过一系列的计算,返回最终的推荐结果列表,在线层可以细分为召回层—精排层—重排层结构。

图2:游戏中心个性化推荐算法架构图

图3:游戏中心个性化推荐工程架构图
- 离线层
离线层适用于用户长期兴趣的计算、离线模型的训练、模型参数的实验以及其他对时效性要求不高的任务,因此离线层主要采取HDFS+Spark的工程实现(批处理的计算方式)。业务数据通过DC或者TDBank上报,累计一定的数据量(游戏中心是以每小时为周期)周期性落地到HDFS或者TDW中以库表的形式存在,以Spark为计算引擎,对库表数据进行一系列处理后,将结果数据推送到线上存储,构成线上推荐引擎的重要数据来源。对于游戏中心这个场景,离线层的工作流可以划分为6大步骤:推荐物料的准备、数据处理、样本设计、特征提取、模型训练、数据上线。
1、推荐物料的准备
对于推荐系统来讲,第一个需要确定的就是推荐物料(也就是推荐池子)。游戏中心推荐的物品主要有两大类:第一大类就是游戏app,目前游戏中心接入算法的游戏app主要包括精品游戏、单机游戏,基本上每天变化不大,因此该类物料由业务每天例行上报更新并推送到线上存储即可。第二大类就是游戏内容了,主要包括攻略、视频、直播等,该类物料相对来讲实时性要求会高一些(新游上线当天需要内容同步更新)。目前游戏中心的内容来源数据链路如图4所示,主要来源是一些上游PGC内容的采购,经过自动Tag提取之后进入到标签内容库,算法侧直接从标签内容库获取推荐物料,目前是按小时更新。

图4:内容源数据链路
2、数据处理
熟悉推荐流程的同学可能比较清楚,数据处理过程繁琐枯燥且耗时较长,占据了整个算法开发周期60%以上的时间,贯穿整个开发流程。没入坑之前有些人可能会以为推荐算法工程师是一个高大上的职位,每天舒舒服服地看下paper,研究下算法,做下实验,特别酷。入坑之后就会发现,每天干的最多的活就是处理数据。但这也充分说明了数据处理的重要性,毕竟只有充分了解数据才能更了解业务,才能更加合理地设计你的推荐策略。这儿讲的数据处理主要包括数据验证、脏数据过滤以及数据转换等。下面主要总结一下在数据处理过程中所踩过的坑:
(1)一定要做好数据上报准确性的验证:前端同学有时候可能不是特别了解算法同学对于上报数据的诉求,所以在上报的时候可能会出现目标不一致的情况。常见的情况有:上报逻辑出错(分页feeds曝光只上报了第一条feeds的数据)、上报id错位(曝光的operid报了下载的数据),上报id缺失等。而验证数据上报准确性的常规操作就是打开游戏中心,将每个场景你有可能会用到的用户行为都操作一遍,记下操作时间,一个小时后从流水中捞出你的数据,逐一验证是否合理(噩梦)。
(2)推荐逻辑出现问题时候优先考虑数据的准确性:当推荐结果产生问题或者出现bug的时候,优先检查数据的准确性。模型的鲁棒性以及容错性一般都较高,最可能出现问题的往往是数据环节。通常都是沿着数据链路往上游逐步排查从而定位问题。
(3)对业务流水数据做一层数据中间表做解耦:算法开发过程中,最好不要直接操作operid相关的逻辑,遇上业务改上报id时(比如产品改版换了新的一套operid),改代码改的你头疼。
(4)算法接入后一定要跟产品以及前端同学再三确认算法ID的上报准确性:业务在调用推荐引擎时都会获得一个算法ID,算法ID上报的准确性直接影响效果监控报表的可信度。很多时候上了一个算法策略结果发现线上效果突然下降,排查半天才发现原来部分转化行为的算法ID上报缺失,所以这儿一定要仔细验证清楚。
(5)脏数据过滤是一门玄学:脏数据的定义通常需要根据业务场景来决定,有时候信心满满地将所有脏数据都过滤之后,线上效果反而降了,所以在过滤数据时要留个心眼(什么样才是脏数据?脏数据是不是一定没用?不要想当然,还是用线上效果说话吧!)。
(6)建立完善的报表监控体系:推荐的一个重要环节就是报表监控,不仅仅包括对效果的监控,还包括对池子的监控、核心用户的监控、item场景表现的监控等。只有建立完善的监控体系,才能在推荐结果受到挑战时快速定位问题。

图5:游戏中心报表监控体系
3、样本设计
一般来讲,推荐问题都会转换成二分类问题,也就是判断用户对某个物品是否会产生操作行为(通常一个U-I对就是一个样本),那么要训练出一个看起来合理线上效果又比较理想的二分类模型,正负样本的设计显得极其重要,下面总结一下游戏中心在设计不同场景的样本时的一些经验:
(1)如何正确定义正负样本?在纯icon推荐的场景,咋一看可以理解为用户下载了该app就是正样本,没有下载就是负样本。但仔细一想这样做会产生两个问题,第一个问题就是正负样本极其不均衡(机器学习中经典问题之一),因为用户浏览几十个app可能也就下载1个app,当然,机器学习针对正负样本不均衡问题会有很多解决方法,这儿就不展开描述了;第二个问题就是用户没有下载并不代表就是不喜欢,这儿会有几个值得推敲的地方:1)用户曝光了但是从没有产生过下载行为,可能因为是无效曝光,用户关注的焦点不在这,所以无法判断用户到底是喜欢还是不喜欢;2)用户在游戏icon曝光的场景并没有产生下载行为,但是用户产生了点击行为,从而进入到游戏详情页后产生下载行为,这样是不是可以认为用户其实是喜欢的,产生的也是正样本呢?举这么个例子主要是为了说明,对于每个不同的推荐场景来说,正负样本的设计都应该充分结合业务特性,不然容易产生有偏样本。
(2)设计样本时应保证每个用户样本数的均衡:在app分发或者内容分发场景,容易存在一些刷量用户;该批用户频繁进入游戏中心从而产生多次操作行为,因此在设计样本时应对多次操作的U-I样本对去重,并保证每个用户样本数的均衡,从而避免模型被少数用户所带偏。
(3)样本权重的设计问题:在feeds推荐的场景中,不同推荐槽位所产生的样本权重应该有所不同;比方说首页feeds场景,用户刚进入场景时,注意力会比较集中,产生的负样本应该置信度较高,权重也较高;当用户下滑到后面feeds的时候,对feeds的内容可能会比较乏味了,产生的正样本置信度应该也是较高的,权重应该也设置较高。
(4)适当丰富样本来源的多样性:一般样本都是基于当前场景所产生的用户行为来选取的,而当前场景用户的行为某种程度是受推荐结果而影响的(“你给我推荐了王者荣耀,那么我只能喜欢王者,但是可能我更喜欢你没给我推的吃鸡呢”),随着算法的迭代,越到后面,算法其实是在迭代自身,越学越窄,这也是推荐系统经典的多样性问题。youtube所采用的一种缓解的方法就是从其他没有算法干扰的场景选取部分样本,来避免这个问题,而在游戏中心的样本设计中,都会单独开设一股没有算法干扰的小流量作为干净样本的补充。
4、特征提取
特征决定机器学习的上限,而模型只是在逼近这个上限。可想而知,特征设计的重要程度是多么的高。关于特征设计的方法论有很多,这儿就不具体讨论。这里主要介绍一下游戏中心各个场景在设计特征时候的通用思路以及为了解决首页feeds特征空间不一致时所采用的多模态embedding特征。
(1)通用特征设计思路:如图6所示。这儿需要提一下的是,游戏中心的推荐场景由于涉及平台利益,所以一般情况下,特征设计时都需要考虑特征的可解释性。

图6:特征设计思路
(2)多模态embedding特征向量:首页feeds流分发场景是一个具有挑战性的场景,其中一个比较有意思的难题就是待推荐的内容类型较多。传统的feeds推荐场景要么都是纯视频流、要么是纯文字feeds等,而游戏中心首页这儿待推荐的内容类型有攻略、视频、直播、活动、礼包等,而且每一种内容类型的二级承载页产品形态也不一致,这样会导致可提取的特征空间维度不一致。比方说视频承载页的观看时长与图文承载页的观看时长量级不一致,视频承载页有icon点击等操作而图文承载页则没有。特征空间的不一致会导致模型在打分的时候会有所偏颇,离线实验过程中发现视频由于特征维度较齐全,打分结果整体偏高。因此,为了减缓特征空间维度不一致问题,游戏中心首页feeds流引入了多模态embedding特征向量,该方法在企鹅电竞视频推荐场景已经取得了较好的效果(如图7所示)。多模态embedding特征向量的设计主要参考youtube的论文,从而获得每个user、item的低维特征向量,一方面解决item的原始特征空间维度不一致问题,另一方面也根据用户的历史行为,学习user、item的隐语义特征维度,起到信息补充的作用。
 图7:多模态embedding网络
图7:多模态embedding网络
5、模型训练
好了,终于到了别人所认为的高大上的步骤了——模型训练,其实一点都不高大上,尤其是有了神盾推荐这个平台。目前神盾推荐离线算法平台已经集成了大部分常见的推荐算法,包括LR,Xgboost,FM,CF等,因此离线训练只需要准备好样本跟特征,配置好参数,就可以一键点run喝咖啡了(开玩笑开玩笑,是继续搬下一块砖)。傻瓜式的模型训练(调包侠)其实并没有太大的坑,但是有几点经验也在这稍微写一下哈:
(1)注意调参的正确姿势:目前神盾默认是将数据集划分为train跟test,如果盯着test数据集的指标来调参的话,是很有可能出现线下高线上低的情况。因为盯着test指标进行调参的话容易加入个人先验,本身就是一种过拟合的操作,正规的操作应该是将数据集划分为train-test-validation。
(2)同样的业务场景建议共用一个大模型:新版游戏中心目前有9个场景需要算法接入,如果每一个场景都单独建模的话,一来维护成本高,二来浪费人力。适当对场景问题进行归纳,训练通用模型可以有效地节省开发时间。比如说首页分类列表推荐,游戏Tab的热游列表推荐等,其实都是纯icon的推荐,可以用统一的大模型来建模。通用模型首先要考虑的问题就是样本、特征的选取,样本可能比较好设计,汇总所有场景的样本即可,最多就是根据场景特性设计不同的权重;而特征就需要好好斟酌,是分场景提取特征还是汇总后提取、不同场景特征维度不一致如何处理等。
(3)选择合适的机器学习方案:目前首页feeds是将排序问题转化为二分类问题,评估指标选取的是auc,所以优化的重点在于尽可能地将正负样本区分开(正样本排在负样本前面),但对于正样本之间谁更“正”却不是二分类模型的关注重点。神盾近来已经支持pari-wise的LTR算法,可以解决任意两样本之间置信度问题,后续可以在首页feeds场景上做尝试。
(4)选择合适的优化指标:对于视频瀑布流场景,优化的目标可以有很多,比如人均播放个数、播放率、人均播放时长,具体需要跟产品同学沟通清楚。
(5)避免对分类问题的过度拟合:前面已经提过,在推荐场景,经常将推荐问题转化为分类问题来处理,但是需要注意的是,推荐问题不仅仅只是分类问题。分类问题是基于历史行为来做预测,但推荐问题有时候也需要考虑跳出用户历史行为的限制,推荐一些用户意想不到的item,因此,推荐是一个系统性问题,应当避免过度拟合分类问题。
6、数据上线
数据上线可以说是推荐系统中较为核心的环节,其中会面临很多难题。这儿的数据主要指的是离线计算好的物料数据、特征数据(用户、物品)、模型数据等。目前神盾会周期性地对需要上线的数据出库到hdfs,通过数据导入服务推送到线上存储,主要是grocery(用户特征)跟共享内存ssm(物品特征以及池子数据等查询较为频繁的数据)。目前这儿会有几个小问题:
(1)数据的一致性问题:离线模型在训练的时候,会对样本数据跟特征数据做拼接,通常都是将当前周期的样本跟上一周期的特征做拼接,以天为例,也就是今天的样本会跟昨天的特征数据做拼接。但是离线数据的计算以及上线是会有时间延迟的,尤其是特征数据。有可能今天的凌晨0点到5点,线上所拉到的特征数据其实是前天的特征数据,5点之后,昨天的特征数据才计算完并更新到线上。也就是说凌晨5点之前,所产生的推荐结果其实是用前天的特征数据来计算的,那么离线训练的时候,拼接的特征数据就会与实际的数据不一致。
(2)数据的实时性问题:前面也讲了,业务数据一般会周期(按小时)落地到hdfs或者tdw以库表形式存在,基于spark进行数据处理之后又推送到线上存储,这种复杂的数据处理链路导致数据时效性得不到保证(频繁地数据落地以及数据上线所导致)。因此,离线层仅适用于对数据时效性不高的任务,比如长期兴趣的计算等。
- 近线层
前面已经提到,离线层在数据时效性以及数据一致性的问题上面临较大的挑战。本质上是由于数据频繁落地以及上线导致的延迟所引起的,给游戏中心推荐带来较大的困扰。企鹅电竞也面临同样的问题,因此,两个业务联合设计了近线层(如图8所示)。目前整个数据链路已经打通,并且也在企鹅电竞业务上试点成功。整个框架是基于kafka+spark streaming来搭建的,目前主要实现两个功能点:实时特征的提取以及实时样本特征的拼接。由于近线层不需要落地以及线上导数据服务,而是直接对业务流水进行操作后写入线上存储,因此耗时较少,基本可以做到秒级别的特征反馈,解决了离线层计算周期长的缺点,适用于用户短时兴趣的捕捉。
实时样本特征的拼接主要是为了解决数据一致性问题。离线层对样本、特征进行拼接的时候一般都是默认当前周期样本拼接上一周期的特征,当由于特征上线的延迟,有部分当前周期样本的产生其实是由t-2周期的特征所导致,因此为了保证训练数据的准确性,我们在近线层设计了实时的样本特征拼接。当用户请求时,会带上读取的特征数据,拼接到用户的操作流数据上,构成离线层的训练数据。
 图8:近线层功能逻辑
图8:近线层功能逻辑
- 在线层
在线层是推荐系统的关键环节,直接影响最终的推荐结果。一般分为召回层,精排层、重排层(或者是matching、ranking、rerank)。召回层一般是起到粗筛的作用,对于内容推荐来说,推荐的池子一般都是上万级别,如果直接进行模型打分的话,线上服务压力会比较大,因此,通常都会采用各种召回的策略来进行候选集的粗筛。目前游戏中心所采用的召回策略主要有标签、热度、新鲜度、CF等。精排层所干的事情就比较纯粹了,一般就是模型加载以及模型打分,对召回的物品进行一个打分排序。最后就是重排层,主要是对模型打分结果进行一个策略的调整。游戏中心的重排排层主要有以下几个逻辑:1)分类打散:首页feeds在推荐的时候,如果只由模型进行打分控制的话,容易出现游戏扎堆的现象,也就是连续几条feeds都是同款游戏,因此需要重排层来调整展示的顺序;2)流量分配:游戏的分发涉及平台的利益,每款游戏的曝光量会影响平台的收入,因此需要合理分配每款游戏的展示量;3)bandint策略:主要是用于兴趣试探,feeds场景会涉及多种内容类型,如何在推荐用户历史喜欢的内容类型以及尝试曝光新的内容类型之间做平衡是推荐系统典型的E&E问题,这儿我们设计了一个简单的bandint策略,下面会详细讲一下。4)运营策略:一些偏业务性质的运营策略也会在重排层体现。
推荐系统中会遇到一个经典的问题就是Exploitation(开发) VS Exploration(探索)问题,其中的Exploitation是基于已知最好策略,开发利用已知具有较高回报的item(贪婪、短期回报),而对于Exploration则不考虑曾经的经验,勘探潜在可能高回报的item(非贪婪、长期回报),最后的目标就是要找到Exploitation & Exploration的trade-off,以达到累计回报最大化。对于游戏中心首页feeds而言,一味推荐用户历史喜欢的内容类型或者大量尝试曝光新的内容类型都是不可行的;首先用户的兴趣可能会有所波动,过去可能喜欢视频类型,但是下一刻就可能不喜欢了;其次一味推荐用户历史喜欢的内容类型,可能会让用户产生厌倦。为了平衡两者之间的关系,我们在重排层设计了一个简单的策略,具体如图9、图10所示。
 图9:游戏中心bandit策略算法逻辑
图9:游戏中心bandit策略算法逻辑
 图10:游戏中心bandit策略具体实现
图10:游戏中心bandit策略具体实现
目前游戏中心个性化推荐所遇到的难点以及下一步的迭代计划主要如下:
1、外部数据的引入:1)结合第三方数据做推荐:目前游戏中心个性化推荐的依据主要是用户的场景表现、游戏内表现以及一些基础的画像数据,数据来源较为单一。引入更多的第三方业务数据(比如企鹅电竞),一方面可以丰富用户的特征维度,另一方面可以给用户带来体验上的提升(用户刚在企鹅电竞看了个吃鸡的直播,来到游戏中心就给推荐了“刺激战场”)。2)丰富推荐物料:目前游戏中心的内容来源部分存在“同质化”现象,素材类型还不是特别丰富,需要引入更多优质的外部内容。
2、多模态特征提取:游戏中心的推荐内容类型较为丰富,包括了视频、图文、活动、礼包等,如何在同一个特征向量空间对各个item进行信息抽取是目前遇到的难题之一。现有的解决方案是基于youtube的embedding网络进行user、item的embedding向量学习。该网络的输入是无序的,也就是没有考虑用户历史行为的轨迹,那么是否可以用图来表示行为的轨迹,基于graph embedding的方法获得信息更加丰富的item向量?目前业界也有若干基于graph embedding的推荐案例(手淘首页 、阿里凑单 )。
3、内容元信息的提取:目前游戏中心对于item的特征提取要么是基于统计的特征,要么就是基于item历史行为的embedding特征或者tag提取,对于内容本体信息的提取还较为薄弱,如何有效地提取非结构化内容的信息是下一步迭代需要考虑的问题。
4、模型的快速更新:对于用户兴趣的实时捕捉,不仅依赖于数据的实时更新,同样依赖于模型的实时更新。目前线上的模型是按天例行更新,如何快速地训练模型以及部署模型是后续不可避免的问题。
5、优化指标考虑收入相关因子:当前的优化指标基本是转化率、时长等推荐系统常见的指标,但游戏中心涉及平台收入,需要综合考虑每个游戏的收益(类似广告系统中的竞价)。如何设计合理的优化指标(考虑游戏arpu、ltv等)以及在用户体验跟平台收入之间做平衡也是下一步迭代的关键。
6、流量分配问题:首页feeds场景既涉及游戏流量的分配,也涉及内容类型流量的分配,如何有效地设计流量分配方案,从而减轻重排逻辑的负担也是需要考虑的优化点。
7、拉活还是拉新:如何根据用户在游戏生命周期的不同阶段推荐合适的内容是首页feeds场景需要考虑的问题。
8、新品试探:目前我们只是在内容类型上做了一些简单的策略,后续还需要调研更加成熟的解决方案来解决E&E问题。
总结
本文主要是对游戏中心在算法一期的接入过程所遇到的问题做一些总结,以及梳理下一步迭代的计划。由于算法一期的重心在于算法的快速接入,因此整个个性化推荐框架中所涉及到的策略可能都略显“着急”,希望各位同行大佬多多包涵。关于游戏中心推荐问题,欢迎随时交流。
来源:腾讯QQ大数据
更多阅读:
导语 在内容推荐系统里,一个常用的方法是通过理解内容(挖掘内容属性)去挖掘用户的兴趣点来构建推荐模型。从大多数业务的效果来看,这样的模型是有效的,也就是说用户行为与内容是相关的。不过有一点常被忽略的是:相关性是对称的!这意味着如果可以从内容属性去理解用户行为,预测用户行为,那么也可以通过理解用户行为去理解内容,预测内容属性。
相关性是对称的
在内容推荐系统里,一个常用的方法是通过理解内容(挖掘内容属性)去挖掘用户的兴趣点来构建推荐模型。从大多数业务的效果来看,这样的模型是有效的,也就是说用户行为与内容是相关的。不过有一点常被忽略的是:相关性是对称的!这意味着如果可以从内容属性去理解用户行为,预测用户行为,那么也可以通过理解用户行为去理解内容,预测内容属性。
利用行为数据生成内容向量
推荐系统里我们一直有基于用户行为去理解内容,典型的例子是基于用户行为构造内容特征,例如内容的点击率、内容的性别倾向,内容的年龄倾向等。这样的理解是浅层的,仅仅是一些简单的统计。我们其实有更好的办法可以构建内容特征,它的第一步是利用用户行为将内容转化为向量,下面会以应用宝业务为例讲解利用用户行为将app转化为向量的思路。
从直觉上来看,用户下载app的先后关系是相关的,以图1的行为数据为例,一个用户之前下载过街头篮球,那么他接下来会下载体育类app的概率会比他接下来下载时尚类app的概率更大。也就是说 P(腾讯体育|街头篮球)>P(唯品会|街头篮球)



到这里我们已经大致介绍了利用用户行为将内容转化为向量的方法,这里将这种技术称作item2vec。以应用宝为例,它的item是app,它的实际应用也可以称作app2vec。
内容向量聚类
基于应用宝已有的类别体系观察,可以明显区分开角色扮演类游戏app和理财app。


也可以发现一些没有加入类别体系的特殊app群体。


now直播业务也基于该方法进行了生成了主播向量并对主播进行了聚类,初步结果来看是聚类是可以明显区分开男女主播的,并且也发现了几个有趣的主播类型,例如直播玩王者的主播,直播电影电视剧的主播,直播农村生活的主播。
基于内容向量的分类模型
应用宝的app分类(打标签)场景长期以来都存在这样的痛点:
- 分类体系经常会面临变动
- app的人工标注成本高,复杂标签体系下app的标注数据很少
- app属于复杂数据结构的内容,它的内在难以用已有算法进行挖掘,过去只能通过它的描述和图片来挖掘其信息
这里我们可以先思考一个问题:为什么要给app做分类和打标签?
答:给app做分类和打标签实际上是为了让用户可以更方便的找到自己想要的app,为了让我们可以更容易地结合用户兴趣给用户推送app。
从问题和答案我们可以得出一个结论:给app做分类和打标签有意义的前提是用户的行为是和app的类别、标签相关的!例如下面的这个例子里,第一位用户喜欢下载纸牌类游戏,第二位用户喜欢下载跑酷类和儿童类游戏,第三位用户喜欢下载休闲类游戏。

上面的分析我们知道用户行为应该可以用于判断app的类别标签。因此在给应用宝的app进行分类和打标签时,我们引入了基于用户行为生成的app向量。具体框架可看下图:

通过增加app向量作为分类模型的特征,可以很大程度上提高app分类的准确度(可以参考聚类中的例子),在实际业务中,部分标签的分类准确率和覆盖度都有大幅度提升。
基于内容向量的推荐召回
直观的例子是相关推荐,因为这一场景通常不会对召回结果做太多的加工。常见的召回结果生成方法是先计算item与item之间的相似度(一般使用cosine相似度),再取其中的top n相似item。

在应用宝的两个场景中基于app向量做了app的推荐召回进行了测试,相对于原模型效果有明显的提升。
基于内容向量的语义召回
在app搜索场景基于行为数据生成的搜索词向量优化了语义召回,明显增强了词的模糊匹配能力。例如搜索“潮流”,出来的结果是从用户行为角度跟“潮流”相关的app,而不是单纯基于语义匹配。
或者举一个更直观的例子,吃鸡游戏出来的时候,搜索吃鸡出来的都不是吃鸡游戏。但是对此感兴趣的用户后续还是会去找到正确的搜索词,例如之后搜索“绝地求生”,或是下载了“绝地求生”,基于这些词,基于这些行为,可以将“吃鸡”和“绝地求生”关联起来。
基于内容向量的应用场景还有很多,加入我们,我们一起来玩转机器学习!
来源:腾讯QQ大数据
更多阅读:
目前,某产品营收运营正处在从过去依赖产品经理的经验到通过数据来驱动增长(Growth Hacking)的过渡期。在这里梳理一下通过数据模型帮助该产品营收的一些经验。
正文
本文主要包括7部分:定义目标:转化为数据问题、样本选择、特征搭建、特征清洗、特征构造、特征选择、模型训练与评估。如图1下:

图1
一、定义目标:转化为数据问题
营收活动就是要从大盘中找出那些响应活动的高潜用户,这实际上是一个有监督的分类问题。通过训练集找出典型的响应用户特征,得到模型。再将模型用于实际数据得到响应用户的分类结果。这里选择逻辑回归(Logistic Regression)。为什么是逻辑回归?因为逻辑回归鲁棒性好,不容易过拟合,结果便于解释,近些年有很多新的算法可能分类效果会更好,但很多前辈的经验表明,精心做好特征准备工作,逻辑回归可以达到同样好的效果。
二、数据获取
特征主要包括画像和行为数据,画像数据最稳定且易获取,行为数据预测能力最强。基础特征包括画像数据(取自达芬奇)、特权操作、平台操作、历史付费行为、QQ和空间活跃等共计236个特征。
三、样本选择
选择最具代表性的样本,如果样本倾斜严重,则进行抽样,保证正样本比率不低于10%。
训练样本的选择决定模型的成败,选择最能代表待分类群体的样本。最佳选择是用先前该活动的数据做训练集,如果是新的活动,用先前相似的活动数据。
有时遇到这样的情况,先前活动的号码包是通过模型精选出来的,通常,这些号码包不是整体的有效代表,不能直接用来做为新的模型的训练样本,当然如果这些号码包占整体用户的80%以上基本就没问题。一种解决办法是随机选取样本投放活动等待响应结果来构建模型,这种方法比较耗时耗力,通常不用;另一种方法是抽取部分未投放的号码标记为非响应群体,这样构建的模型虽然不是效果最优的,但却能提升模型的泛化能力。
样本多大合适?没有标准答案,一般来说特征越多,需要的样本越大。我们建模一般有上百的特征,训练样本会选择几十万数据级。
当前计算机的计算能力已经提高了很多,抽样并不是必须的,但抽样可以加快模型训练速度,而且用单机来做模型的话,抽样还是很有必要的。通常目标用户的占比都很低,比如该产品某次活动的目标用户占比只有1‰,这样数据是严重倾斜的,通常做法是保留所有目标用户并随机抽取部分非目标用户,保证目标用户占比大于10%,在该产品营收模型训练中,一般用目标用户:非目标用户=1:4。
四、数据清洗
了解数据特性是保证优质模型的第一步。数据清洗是最无聊最耗时但非常重要的步骤。包括脏数据、离群数据和缺失数据,这里了解数据的先验知识会有很大帮助。用箱线图来发现离群点,这里关于数据的先验知识会有很大帮助。如果变量太多,不想花太多时间在这个上面,可以直接把脏数据和离群数据处理成缺失值。对于缺失值,先给缺失值建一个新变量来保留这种缺失信息,连续变量一般用均值、中位数,最小值、最大值填充。均值填充是基于统计学中最小均方误差估计。如果数据是高度倾斜的话,均值填充是较好的选择。或用局部均值填充,如年龄分段后所属年龄段的均值。还可以用回归分析来填充,实际中用的比较少。分类变量一般用频数填充。
五、特征构造
已经有原始特征,为什么要进行特征构造?特征构造的必要性主要体现在发现最适合模型的特征表现形式。
清洗工作之后,就可以进行特征构造了,主要有3种特征构造方法:汇总、比率、日期函数。
- 汇总:如按天、周、月、年汇总支付金额,近三天、近7天、近14天、近21天、近31天听歌/下载次数,统计用户近一年累计在网月份等。
- 比率:曝光点击转化率、曝光支付转化率、点击支付转化率、人均支付金额、次均支付金额。
- 日期衍生:首次开通服务距现在时长、最近一次到期时间距现在时长,到期时间距现在时长。
- 转换特征:对原始连续特征做平方、三次方、平方根、立方根、log、指数、tan、sin、cos、求逆处理。然后从所有转换中选择2个预测性最好的特征。实际中,使用最多log处理。
逻辑回归本质上是线性分类器,将预测变量尽量线性化,虽然我们的特征有连续变量和分类变量,模型训练时会把所有变量当做连续变量。
连续变量可以直接用来训练模型,但分段会使得变量更具有线性特征,而且可以起到平滑作用,经验表明分段后的特征会提升模型效果。分段一般依据经验划分或先分为均等10段然后观察各段中目标变量占比来确定最终分段。如年龄分段主要基于常规理解,分为幼儿园、小学、初中、高中、大学、硕士、博士、中年、壮年、老年。
六、特征选择
特征选择的目的是要找出有预测能力的特征,得到紧凑的特征集。
特征成百上千,对每一个变量进行深入分析并不是有效的做法,通过相关系数和卡方检验可以对特征进行初步筛选。相关性强的特征去掉其一,对每个特征进行单变量与目的变量间的回归模型,如果卡方检验小于0.5,说明预测能力太弱,去掉该变量。
做过初步变量筛选后,用剩余变量训练模型,根据得到的回归系数和p值检验,剔除回归系数接近0和p值大于0.1的特征,得到最终用于建模的特征集。
特征多少个合适?这个没有标准答案,主要原则是保证模型效果的同时鲁棒性好,并不是特征越少,鲁棒性越好。主要取决于市场,如果市场比较稳定,变量多一些会更好,这样受单个变量变动的影响会较小;当然如果想用用户行为来预测未来趋势,变量少一些比较好。对我们做营收增长来说,模型特征尽量简化,这样便于从业务角度进行解读,便于跟老板和产品同事解释。
七、模型训练和评估
前面花了大量时间来确定目标、准备特征、清洗特征。使用一些简单的技术来过滤一些预测性弱的特征。接下来,用候选特征来训练和验证模型。
模型实现步骤:
1、 通过挖掘算法获取不同群体的差异特征,生成模型用于分类。
2、 待分类用户群通过分类器筛选出目标人群,形成标识和号码包。
3、 用户号码包通过渠道进行投放,营销活动正式在外网启动。
4、 收集曝光、点击、成交数据用于评估模型效果,明细数据用于修正模型的参数。
5、 重复1——4

图2
另外,活动投放参见组选择很有必要,一般是依据产品经验或随机选取,参照组的效果一般不如模型选择的,这会导致收入有所减少,有时很难说服产品,但对于对比、监控和检验模型效果来说很有必要。
该产品营收依据模型精细化运营以来,收效显著,支付转化率提升30%~150%。
最后致上一句名言:Your model is only as good as your data!
参考文献
[1]. OP Rud. Data mining cookbook: modeling data for marketing, risk, and customer relationship management. 2001
[2]. https://zh.wikipedia.org/wiki/逻辑回归
来源:腾讯QQ大数据
更多阅读:

全球技术研究与咨询公司 Technavio 最近的《全球深度学习系统市场报告》中选出了全球 Top 6 的深度学习机构,分别是谷歌的母公司 Alphabet、BVLC、Facebook、LISA lab 以及微软。深度学习的应用越来越广,而起码在未来五年,这个领域仍将由这些顶尖的公司/机构领军。
Technavio 是一家全球技术研究与咨询公司,其最近的《全球深度学习系统市场报告》选出了全球 Top 6 的深度学习机构,分别是谷歌的母公司 Alphabet、伯克利视觉学习中心(BVLC)、Facebook、蒙特利尔大学的 LISA lab 以及微软公司。报告称,到2020年,全球深度学习系统市场规模将超13亿美元,2016~2020年期间的复合年增长率达到 38.73%。深度学习具有在现实生活中应用的巨大潜力,这也使得它越来越受到关注。在实际应用中,社交媒体、软件服务协议、硬件、网站Cookies 以及应用程序权限等为训练神经网络提供了大量数据。深度学习网络在从这些数据中提取有价值的信息方面很有优势,因为它们擅长无监督学习。
①美洲市场得到BFSI行业快速增长的数据的驱动。
②北美有超过1500家 AI 公司。
③2010年以来,金额最大的四项 AI 收购案例均发生在英国。
④亚太地区将是 AI 增长最快的区域,到2020年预计年复合增长率将达到41.58%。
全球范围里的深度学习系统是一个高度分散的市场,既有许多大型公司,也有无数的初创企业。Technavio 的分析师预计,随着不同类型的企业进入这个市场,市场竞争将加剧。拥有差异化产品的企业具有更大的竞争力,为了在这个市场上站稳地位,企业将持续创新。此外,随着先进技术的广泛普及,产品更加多样,产品的选择将变得更加复杂。
Technavio 评出的全球 Top 6 深度学习企业如下:
- Alphabet
2015年11月,Alphabet 的子公司谷歌宣布在开源 Apache 2.0 许可下开放 TensorFlow 深度学习框架。TensorFlow 是由谷歌机器智能研究团队开发的深度学习框架,可用于使用数据流图进行数值计算。该框架由 Python API 组成,使用数据流图执行数值计算。TensorFlow 拥有快速增长的用户和贡献者社区,使它成为非常受欢迎的深度学习框架。
- BVLC
BVLC(伯克利视觉学习中心)及其社区贡献者在 BSD 2-Clause 许可下开发了名为 Caffe 的深度学习平台。Caffe 是使用 C++ 开发的,具有表达简洁、快速和模块化的优势。Caffe 拥有许多特征,如富于表达力的结构、可扩展的代码以及不错的速度。
Facebook 开发了深度学习框架 Torch,能用于训练大规模卷积神经网络,适用于图像识别等AI应用。Torch 是一个系统的计算框架,广泛支持各种机器学习算法。它同时提供的 Tensor 库具有非常高效的 CUDA 后端,且神经网络库可用于构建具有自动微分功能的随机非循环计算图。
- LISA lab
蒙特利尔大学的 LISA lab 开发了名为Theano的深度学习框架。Theano 是一个软件包,或说是一个数学表达式的编译器,能够有效地定义、评估和优化包含多维数组的数学表达式。Theano 允许用户在不同的架构(如 CPU或 GPU)上编程。Theano 不仅可用于 CPU 密集型的机器学习,也可用于大规模神经网络或深度学习。
- 微软
CNTK(微软认知工具包)是微软的一个开源深度学习工具包,可用于加速 AI 开发,使在多个 GPU 和服务器上组合训练多种深度学习模型变得容易。CNTK 适用于许多应用,例如语音识别、机器翻译、图像说明、图像识别、语言建模、自然语言理解、文本处理等。
- Nervana Systems
今年8月英特尔正式收购深度学习创业公司 Nervana Systems,其目的是加强英特尔内部AI解决方案的作用。Nervana 开发了基于 Python 的深度学习框架 Neon,并且最近在 Apache 2.0 许可下开源了。Neon 具有定制化的 CPU 和 GPU 后端,分别名为 Nervana CPU 后端和 Nervana GPU 后端。
来源:technavio
更多阅读:

当前的数据挖掘形式,是在20世纪90年代实践领域诞生的,是在集成数据挖掘算法平台发展的支撑下适合商业分析的一种形式。也许是因为数据挖掘源于实践而非 理论,在其过程的理解上不太引人注意。20世纪90年代晚期发展的CRISP-DM,逐渐成为数据挖掘过程的一种标准化过程,被越来越多的数据挖掘实践者成功运用和遵循。
虽然CRISP-DM能够指导如何实施数据挖掘,但是它不能解释数据挖掘是什么或者为什么适合这样做。在本文中我将阐述我提出数据挖掘的九种准则或“定律”(其中大多数为实践者所熟知)以及另外其它一些熟知的解释。开始从理论上(不仅仅是描述上)来解释数据挖掘过程。
我的目的不是评论CRISP-DM,但CRISP-DM的许多概念对于理解数据挖掘是至关重要的,本文也将依赖于CRISP-DM的常见术语。CRISP-DM仅仅是论述这个过程的开始。
第一,目标律:业务目标是所有数据解决方案的源头
它定义了数据挖掘的主题:数据挖掘关注解决业务业问题和实现业务目标。数据挖掘主要不是一种技术,而是一个过程,业务目标是它的的核心。 没有业务目标,没有数据挖掘(不管这种表述是否清楚)。因此这个准则也可以说成:数据挖掘是业务过程。
第二,知识律:业务知识是数据挖掘过程每一步的核心
这里定义了数据挖掘过程的一个关键特征。CRISP-DM的一种朴素的解读是业务知识仅仅作用于数据挖掘过程开始的目标的定义与最后的结果的实施,这将错过数据挖掘过程的一个关键属性,即业务知识是每一步的核心。
为了方便理解,我使用CRISP-DM阶段来说明:
- 商业理解必须基于业务知识,所以数据挖掘目标必须是业务目标的映射(这种映射也基于数据知识和数据挖掘知识);
- 数据理解使用业务知识理解与业务问题相关的数据,以及它们是如何相关的;
- 数据预处理就是利用业务知识来塑造数据,使得业务问题可以被提出和解答(更详尽的第三条—准备律);
- 建模是使用数据挖掘算法创建预测模型,同时解释模型和业务目标的特点,也就是说理解它们之间的业务相关性;
- 评估是模型对理解业务的影响;
- 实施是将数据挖掘结果作用于业务过程
总之,没有业务知识,数据挖掘过程的每一步都是无效的,也没有“纯粹的技术”步骤。 业务知识指导过程产生有益的结果,并使得那些有益的结果得到认可。数据挖掘是一个反复的过程,业务知识是它的核心,驱动着结果的持续改善。
这背后的原因可以用“鸿沟的表现”(chasm of representation)来解释(Alan Montgomery在20世纪90年代对数据挖掘提出的一个观点)。Montgomery指出数据挖掘目标涉及到现实的业务,然而数据仅能表示现实的一 部分;数据和现实世界是有差距(或“鸿沟”)的。在数据挖掘过程中,业务知识来弥补这一差距,在数据中无论发现什么,只有使用业务知识解释才能显示其重要 性,数据中的任何遗漏必须通过业务知识弥补。只有业务知识才能弥补这种缺失,这是业务知识为什么是数据挖掘过程每一步骤的核心的原因。
第三,准备律:数据预处理比数据挖掘其他任何一个过程都重要
这是数据挖掘著名的格言,数据挖掘项目中最费力的事是数据获取和预处理。非正式估计,其占用项目的时间为50%-80%。最简单的解释可以概括为“数据是困 难的”,经常采用自动化减轻这个“问题”的数据获取、数据清理、数据转换等数据预处理各部分的工作量。虽然自动化技术是有益的,支持者相信这项技术可以减 少数据预处理过程中的大量的工作量,但这也是误解数据预处理在数据挖掘过程中是必须的原因。
数据预处理的目的是把数据挖掘问题转化为格式化的数据,使得分析技术(如数据挖掘算法)更容易利用它。数据任何形式的变化(包括清理、最大最小值转换、增长 等)意味着问题空间的变化,因此这种分析必须是探索性的。 这是数据预处理重要的原因,并且在数据挖掘过程中占有如此大的工作量,这样数据挖掘者可以从容 地操纵问题空间,使得容易找到适合分析他们的方法。
有两种方法“塑造”这个问题 空间。第一种方法是将数据转化为可以分析的完全格式化的数据,比如,大多数数据挖掘算法需要单一表格形式的数据,一个记录就是一个样例。数据挖掘者都知道 什么样的算法需要什么样的数据形式,因此可以将数据转化为一个合适的格式。第二种方法是使得数据能够含有业务问题的更多的信息,例如,某些领域的一些数据 挖掘问题,数据挖掘者可以通过业务知识和数据知识知道这些。 通过这些领域的知识,数据挖掘者通过操纵问题空间可能更容易找到一个合适的技术解决方案。
因此,通过业务知识、数据知识、数据挖掘知识从根本上使得数据预处理更加得心应手。 数据预处理的这些方面并不能通过简单的自动化实现。
这个定律也解释了一个有疑义的现象,也就是虽然经过数据获取、清理、融合等方式创建一个数据仓库,但是数据预处理仍然是必不可少的,仍然占有数据挖掘过程一 半以上的工作量。此外,就像CRISP-DM展示的那样,即使经过了主要的数据预处理阶段,在创建一个有用的模型的反复过程中,进一步的数据预处理的必要的。
第四,试验律(NFL律:No Free Lunch):对于数据挖掘者来说,天下没有免费的午餐,一个正确的模型只有通过试验(experiment)才能被发现
机器学习有一个原则:如果我们充分了解一个问题空间(problem space),我们可以选择或设计一个找到最优方案的最有效的算法。一个卓越算法的参数依赖于数据挖掘问题空间一组特定的属性集,这些属性可以通过分析发 现或者算法创建。但是,这种观点来自于一个错误的思想,在数据挖掘过程中数据挖掘者将问题公式化,然后利用算法找到解决方法。事实上,数据挖掘者将问题公 式化和寻找解决方法是同时进行的—–算法仅仅是帮助数据挖掘者的一个工具。
有五种因素说明试验对于寻找数据挖掘解决方案是必要的:
- 数据挖掘项目的业务目标定义了兴趣范围(定义域),数据挖掘目标反映了这一点;
- 与业务目标相关的数据及其相应的数据挖掘目标是在这个定义域上的数据挖掘过程产生的;
- 这些过程受规则限制,而这些过程产生的数据反映了这些规则;
- 在这些过程中,数据挖掘的目的是通过模式发现技术(数据挖掘算法)和可以解释这个算法结果的业务知识相结合的方法来揭示这个定义域上的规则;
- 数据挖掘需要在这个域上生成相关数据,这些数据含有的模式不可避免地受到这些规则的限制
在这里强调一下最后一点,在数据挖掘中改变业务目标,CRISP-DM有所暗示,但经常不易被觉察到。广为所知的CRISP-DM过程不是下一个步骤仅接着上一个步骤的“瀑布”式的过程。事实上,在项目中的任何地方都可以进行任何CRISP-DM步骤,同样商业理解也可以存在于任何一个步骤。业务目标不是简 单地在开始就给定,它贯穿于整个过程。这也许可以解释一些数据挖掘者在没有清晰的业务目标的情况下开始项目,他们知道业务目标也是数据挖掘的一个结果,不是静态地给定。
Wolpert的“没有免费的午餐”理论已经应用于机器学习领域,无偏的状态好于(如一个具体的算法)任何其他可能的问题(数据集)出现的平均状态。这是因为,如果我们考虑所有可能的问题,他们的解决方法是均匀分布的,以至于一个算法(或偏倚)对一个子集是有利的,而对另一个子集是不利的。这与数据挖掘者所知的具有惊人的相似性,没有一个算法适合每一个问题。但是经 过数据挖掘处理的问题或数据集绝不是随机的,也不是所有可能问题的均匀分布,他们代表的是一个有偏差的样本,那么为什么要应用NFL的结论?答案涉及到上 面提到的因素:问题空间初始是未知的,多重问题空间可能和每一个数据挖掘目标相关,问题空间可能被数据预处理所操纵,模型不能通过技术手段评估,业务问题本身可能会变化。由于这些原因,数据挖掘问题空间在数据挖掘过程中展开,并且在这个过程中是不断变化的,以至于在有条件的约束下,用算法模拟一个随机选择的数据集是有效的。对于数据挖掘者来说:没有免费的午餐。
这大体上描述了数据 挖掘过程。但是,在有条件限制某些情况下,比如业务目标是稳定的,数据和其预处理是稳定的,一个可接受的算法或算法组合可以解决这个问题。在这些情况下, 一般的数据挖掘过程中的步骤将会减少。 但是,如果这种情况稳定是持续的,数据挖掘者的午餐是免费的,或者至少相对便宜的。像这样的稳定性是临时的,因为 对数据的业务理解(第二律)和对问题的理解(第九律)都会变化的。
第五,模式律(大卫律):数据中总含有模式
这条规律最早由David Watkins提出。 我们可能预料到一些数据挖掘项目会失败,因为解决业务问题的模式并不存在于数据中,但是这与数据挖掘者的实践经验并不相关。
前文的阐述已经提到,这是因为:在一个与业务相关的数据集中总会发现一些有趣的东西,以至于即使一些期望的模式不能被发现,但其他的一些有用的东西可能会被 发现(这与数据挖掘者的实践经验是相关的);除非业务专家期望的模式存在,否则数据挖掘项目不会进行,这不应感到奇怪,因为业务专家通常是对的。
然而,Watkins提出一个更简单更直接的观点:“数据中总含有模式。”这与数据挖掘者的经验比前面的阐述更一致。这个观点后来经过Watkins修正,基于客户关系的数据挖掘项目,总是存在着这样的模式即客户未来的行为总是和先前的行为相关,显然这些模式是有利可图的(Watkins的客户关系管理定律)。但是,数据挖掘者的经验不仅仅局限于客户关系管理问题,任何数据挖掘问题都会存在模式(Watkins的通用律)。
Watkins的通用律解释如下:
- 数据挖掘项目的业务目标定义了兴趣范围(定义域),数据挖掘目标反映了这一点;
- 与业务目标相关的数据及其相应的数据挖掘目标是在这个定义域上的数据挖掘过程产生的;
- 这些过程受规则限制,而这些过程产生的数据反映了这些规则;
- 在这些过程中,数据挖掘的目的是通过模式发现技术(数据挖掘算法)和可以解释这个算法结果的业务知识相结合的方法来揭示这个定义域上的规则;
- 数据挖掘需要在这个域上生成相关数据,这些数据含有的模式不可避免地受到这些规则的限制
总结这一观点:数据中总存在模式,因为在这过程中不可避免产生数据这样的副产品。为了发掘模式,过程从(你已经知道它)—–业务知识开始。
利用业务知识发现模式也是一个反复的过程;这些模式也对业务知识有贡献,同时业务知识是解释模式的主要因素。在这种反复的过程中,数据挖掘算法简单地连接了业务知识和隐藏的模式。
如果这个解释是正确的,那么大卫律是完全通用的。除非没有相关的数据的保证,否则在每个定义域的每一个数据挖掘问题总是存在模式的。
第六,洞察律:数据挖掘增大对业务的认知
数据挖掘是如何产生洞察力的?这个定律接近了数据挖掘的核心:为什么数据挖掘必须是一个业务过程而不是一个技术过程。业务问题是由人而非算法解决的。数据挖 掘者和业务专家从问题中找到解决方案,即从问题的定义域上达到业务目标需要的模式。数据挖掘完全或部分有助于这个认知过程。数据挖掘算法揭示的模式通常不 是人类以正常的方式所能认识到的。综合这些算法和人类正常的感知的数据挖掘过程在本质上是敏捷的。在数据挖掘过程中,问题解决者解释数据挖掘算法产生的结 果,并统一到业务理解上,因此这是一个业务过程。
这类似于“智能放大器”的概念,在早期的人工智能的领域,AI的第一个实际成果不是智能机器,而是被称为“智能放大器”的工具,它能够协助人类使用者提高获取有效信息的能力。数据挖掘提供一个类似的“智能放大器”,帮助业务专家解决他们不能单独完成的业务问题。
总之,数据挖掘算法提供一种超越人类以正常方式探索模式的能力,数据挖掘过程允许数据挖掘者和业务专家将这种能力融合在他们的各自的问题的中和业务过程中。
第七,预测律:预测提高了信息泛化能力
“预测”已经成为数据挖掘模型可以做什么的可接受的描述,即我们常说的“预测模型”和“预测分析”。这是因为许多流行的数据挖掘模型经常使用“预测最可能的结果”(或者解释可能的结果如何有可能)。这种方法是分类和回归模型的典型应用。
但是,其他类型的数据挖掘模型,比如聚类和关联模型也有“预测”的特征。这是一个含义比较模糊的术语。一个聚类模型被描述为“预测”一个个体属于哪个群体,一个关联模型可能被描述为基于已知基本属性“预测”一个或更多属性。
同样我们也可以分析“预测”这个术语在不同的主题中的应用:一个分类模型可能被说成可以预测客户行为—-更加确切的说它可以预测以某种确定行为的目标客户,即使不是所有的目标个体的行为都符合“预测”的结果。一个诈骗检测模型可能被说成可以预测个别交易是否具有高风险性,即使不是所有的预测的交易都有欺诈行为。
“预测”这个术语广泛的使用导致了所谓的“预测分析”被作为数据挖掘的总称,并且在业务解决方案中得到了广泛的应用。但是我们应该意识到这不是日常所说的“预测”,我们不能期望预测一个特殊个体的行为或者一个特别的欺诈调查结果。
那么,在这个意义下的“预测”是什么?分类、回归、聚类和 关 联算法以及他们集成模型有什么共性呢?答案在于“评分”,这是预测模型应用到一个新样例的方式。模型产生一个预估值或评分,这是这个样例的新信息的一部 分;在概括和归纳的基础上,这个样例的可利用信息得到了提高,模式被算法发现和模型具体化。值得注意的是这个新信息不是在“给定”意义上的“数据”,它仅 有统计学意义。
第八,价值律:数据挖掘的结果的价值不取决于模型的稳定性或预测的准确性
准确性和稳定性是预测模型常用的两个度量。准确性是指正确的预测结果所占的比例;稳定性是指当创建模型的数据改变时,用于同一口径的预测数据,其预测结果变 化有多大(或多小)。鉴于数据挖掘中预测概念的核心角色,一个预测模型的准确性和稳定性常被认为决定了其结果的价值的大小,实际上并非如此。
体现预测模型价值的有两种方式:一种是用模型的预测结果来改善或影响行为,另一种是模型能够传递导致改变策略的见解(或新知识)。
对于后者,传递出的任何新知识的价值和准确性的联系并不那么紧密;一些模型的预测能力可能有必要使我们相信发现的模式是真实的。然而,一个难以理解的复杂的 或者完全不透明的模型的预测结果具有高准确性,但传递的知识也不是那么有见地;然而,一个简单的低准确度的模型可能传递出更有用的见解。
准确性和价值之间的分离在改善行为的情况下并不明显,然而一个突出问题是“预测模型是为了正确的事,还是为了正确的原因?” 换句话说,一个模型的价值和它的预测准确度一样,都源自它的业务问题。例如,客户流失模型可能需要高的预测准确度,否则对于业务上的指导不会那么有效。相 反的是一个准确度高的客户流失模型可能提供有效的指导,保留住老客户,但也仅仅是最少利润客户群体的一部分。如果不适合业务问题,高准确度并不能提高模型 的价值。
模型稳定性同样如此,虽然稳定性是预测模型的有趣的度量,稳定性不能代替模型提供业务理解的能力或解决业务问题,其它技术手段也是如此。
总之,预测模型的价值不是由技术指标决定的。数据挖掘者应该在模型不损害业务理解和适应业务问题的情况下关注预测准确度、模型稳定性以及其它的技术度量。
第九,变化律:所有的模式因业务变化而变化
数据挖掘发现的模式不是永远不变的。数据挖掘的许多应用是众所周知的,但是这个性质的普遍性没有得到广泛的重视。
数据挖掘在市场营销和CRM方面的应用很容易理解,客户行为模式随着时间的变化而变化。行为的变化、市场的变化、竞争的变化以及整个经济形势的变化,预测模型会因这些变化而过时,当他们不能准确预测时,应当定期更新。
数据挖掘在欺诈模型和风险模型的应用中同样如此,随着环境的变化欺诈行为也在变化,因为罪犯要改变行为以保持领先于反欺诈。欺诈检测的应用必须设计为就像处理旧的、熟悉的欺诈行为一样能够处理新的、未知类型的欺诈行为。
某些种类的数据挖掘可能被认为发现的模式不会随时间而变化,比如数据挖掘在科学上的应用,我们有没有发现不变的普遍的规律?也许令人惊奇的是,答案是即使是这些模式也期望得到改变。理由是这些模式并不是简单的存在于这个世界上的规则,而是数据的反应—-这些规则可能在某些领域确实是静态的。
然而,数据挖掘发现的模式是认知过程的一部分,是数据挖掘在数据描述的世界与观测者或业务专家的认知之间建立的一个动态过程。因为我们的认知在持续发展和增 长,所以我们也期望模式也会变化。明天的数据表面上看起来相似,但是它可能已经集合了不同的模式、(可能巧妙地)不同的目的、不同的语义;分析过程因受业 务知识驱动,所以会随着业务知识的变化而变化。基于这些原因,模式会有所不同。
总之,所有的模式都会变化,因为他们不仅反映了一个变化的世界,也反映了我们变化的认知。
后记:
这九条定律是关于数据挖掘的简单的真知。这九条定律的大部分已为数据挖掘者熟知,但仍有一些不熟悉(例如,第五、第六、第七)。大多数新观点的解释都和这九条定律有关,它试图解释众所周知的数据挖掘过程中的背后的原因。
我们为什么何必在意数据挖掘过程所采用的形式呢?除了知识和理解这些简单的诉求,有实实在在的理由去探讨这些问题。
数据挖掘过程以现在的形式存在是因为技术的发展—-机器学习算法的普及以及综合其它技术集成这些算法的平台的发展,使得商业用户易于接受。我们是否应该期望因技术的改变而改变数据挖掘过程?最终它会改变,但是如果我们理解数据挖掘过程形成的原因,然后我们可以辨别技术可以改变的和不能改变的。
一些技术的发展在预测分析领域具有革命性的作用,例如数据预处理的自动化、模型的重建以及在部署的框架里通过预测模型集成业务规则。数据挖掘的九条定律及其 解释说明:技术的发展不会改变数据挖掘过程的本质。这九条定律以及这些思想的进一步发展,除了有对数据挖掘者的教育价值之外,应该被用来判别未来任何数据 挖掘过程革命性变化的诉求。
更多阅读:
企业越来越重视数据,84%的企业将数据视作建立经营策略的一个组成部分;29%的企业认为如果消费者数据精确就能增加销量;97%的企业致力于获得单一顾客视图。
但是,企业仍然面临着挑战,企业掌握的数据中23%是不精确的,只有14%的企业认为使用复杂方法管理数据质量。
网络数据爆炸给数据管理带来更大挑战,81%的企业使用社交媒体数据;78%的企业使用移动应用数据;39%的企业有50个以上消费者联络数据库,和2014年的10%比增长明显。
数据越来越复杂,企业对专业人才的需求也在增长。82%的企业积极寻找数据专家参与数据管理策略;79%的企业认为应当由企业自己负责数据质量,偶尔需要获得IT部门的帮助。
 199IT.com原创编译自:Experian 非授权请勿转载
199IT.com原创编译自:Experian 非授权请勿转载
更多阅读:














更多阅读:
听起来炫酷,不过数据可视化确实是一门艺术,它用赏心悦目的方式展现复杂的数据。
以这种方式展示数据能让数据更引人入胜,更容易理解,因此这在和客户或大股东交流时大有助益。
为什么数据可视化如此重要?
2010年David McCandless在TED的演讲中说视觉是五官中接受信息最快也是最多的感官,“我们接受的信息中约80%来自视觉”。
学生“看见”数据都会兴奋,更不用说决策者和企业了。
Emre Soyer 和 Robin Hogarth曾经对三组经济学家就同一个数据集询问了同样的问题,结果显示:
- 第一组专家看到的是数据和标准数据统计分析,72%的受访者得出错误结论;
- 第二组专家看到的是数据,统计分析和图表,61%的受访者得出错误结论;
- 第三组专家看到的只有图表,只有3%的受访者得出错误结论。
调查结果显示视觉化的数据其实更强大。
实时互联网数据
这里显示了互联网各大网站的实时数据可视化图像,即使是在互联网行业工作的人也会惊叹不已。
网络巨头之战
这个页面显示了各大网络巨头的实时收入。
百万推特地图
这个页面是展示Twitter地理数据的好例子,它使用聚类搜索引擎显示全球各地具体推特话题。
下图的关键词是“Terry Wogan”。
Tweetping
直播全球各地推特情况,记录了每条推特的地理位置,因此地图播放时间越长,地理趋势越清晰。
聆听 Wikipedia
这是一个用视觉和声音展示维基百科编辑的页面。铃声象征增加词条,弦声象征减少,音调随编辑规模改变,修改越多,音调越低。
绿色圆圈象征来自非注册访客的编辑,紫色圆圈表示是自动机器人进行的修改。
这个非常让人着迷,所以除非你准备好聆听一整天再去点击。
Google趋势
Google趋势已经众所周知,这里想要展示的是像Google一样简洁的数据可视化。
整个屏幕显示当前的趋势,点击关键词就可以进入相关的搜索结果页面。
“地球风”地图
世界各地的风速、风向的可视化地图。拖动地球放大特定地区,就能获得更多细节。
NOAA气象图
全球天气数据可视化图像,可以看到不同气象数据,如温度、降雨量、气压等。
“Every noise at once”
这是一个散点图,展示了几乎所有你能想到的音乐风格,点击文本能听到30秒的音乐片段。
由Echo Nest(刚被Spotify收购)的Glenn McDonald设计建造,他解释说:“往下是有机音乐,向上是机械和电子音乐;左侧更急促更大气,右侧更活泼。”
不再恐同
网站实时显示了Twitter上所有仇视同性恋的语言。
网络攻击地图
页面显示了全球正在发生DDOS攻击的地区,DDOS攻击就是通过利用合理的服务请求来占用过多的服务资源,从而使合法用户无法得到服务的响应。
航班地图
游客必备,鼠标滑过机场就能了解航班可视化信息,例如出航班机及其实时状态。
绿色代表正常,红色代表异常。
Spotify音乐地图
这个交互式地图以城市为单位展示了全球的人们都在收听哪些音乐。
显然,伦敦的的朋友现在正在收听Grime。
世界人口
极度简单却令人着迷, 这个网站以可视化的形式展示了全球人口实时的增长情况。
点击 ‘watch as we increase’ 按钮,就能看到小火柴人儿实时的增长。
199IT.com原创编译自:Econsultancy 非授权请勿转载
更多阅读:

在各种各样的数据科学论坛上这样一个问题经常被问到——机器学习和统计模型的差别是什么?
这确实是一个难以回答的问题。考虑到机器学习和统计模型解决问题的相似性,两者的区别似乎仅仅在于数据量和模型建立者的不同。这里有一张覆盖机器学习和统计模型的数据科学维恩图。

在这篇文章中,我将尽最大的努力来展示机器学习和统计模型的区别,同时也欢迎业界有经验的朋友对本文进行补充。
在我开始之前,让我们先明确使用这些工具背后的目标。无论采用哪种工具去分析问题,最终的目标都是从数据获得知识。两种方法都旨在通过分析数据的产生机制挖掘 背后隐藏的信息。
两种方法的分析目标是相同的。现在让我们详细的探究一下其定义及差异。
定义
机器学习:一种不依赖于规则设计的数据学习算法。
统计模型:以数学方程形式表现变量之间关系的程式化表达
对于喜欢从实际应用中了解概念的人,上述表达也许并不明确。让我们看一个商务的案例。
商业案例
让我们用麦肯锡发布的一个有趣案例来区分两个算法。
案例:分析理解电信公司一段时间内客户的流失水平。
可获得数据:两个驱动-A&B
麦肯锡接下来的展示足够让人兴奋。盯住下图来理解一下统计模型和机器学习算法的差别。

从上图中你观察到了什么?统计模型在分类问题中得到一个简单的分类线。 一条非线性的边界线区分了高风险人群和低风险人群。 但当我们看到通过机器学习产生的颜色时, 我们发现统计模型似乎没有办法和机器学习算法进行比较。 机器学习的方法获得了任何边界都无法详细表征的信息。这就是机器学习可以为你做的。
机器学习还被应用在YouTube 和Google的引擎推荐上, 机器学习通过瞬间分析大量的观测样本给出近乎完美的推荐建议。 即使只采用一个16 G 内存的笔记本,我每天处理数十万行的数千个参数的模型也不会超过30分钟。 然而一个统计模型需要在一台超级计算机跑一百万年来来观察数千个参数。

机器学习和统计模型的差异:
在给出了两种模型在输出上的差异后,让我们更深入的了解两种范式的差异,虽然它们所做的工作类似。
- 所属的学派
- 产生时间
- 基于的假设
- 处理数据的类型
- 操作和对象的术语
- 使用的技术
- 预测效果和人力投入
以上提到的方面都能从每种程度上区分机器学习和统计模型,但并不能给出机器学习和统计模型的明确界限。
分属不同的学派
机器学习:计算机科学和人工智能的一个分支,通过数据学习构建分析系统,不依赖明确的构建规则。 统计模型:数学的分支用以发现变量之间相关关系从而预测输出。
诞生年代不同
统计模型的历史已经有几个世纪之久。但是机器学习却是最近才发展起来的。二十世纪90年代,稳定的数字化和廉价的计算使得数据科学家停止建立完整的模型而使用计算机进行模型建立。这催生了机器学习的发展。随着数据规模和复杂程度的不断提升,机器学习不断展现出巨大的发展潜力。
假设程度差异
统计模型基于一系列的假设。例如线性回归模型假设:
(1) 自变量和因变量线性相关 (2) 同方差 (3) 波动均值为0 (4) 观测样本相互独立 (5) 波动服从正态分布
Logistics回归同样拥有很多的假设。即使是非线性回归也要遵守一个连续的分割边界的假设。然而机器学习却从这些假设中脱身出来。机器学习最大的好处在于没有连续性分割边界的限制。同样我们也并不需要假设自变量或因变量的分布。
数据区别
机器学习应用广泛。 在线学习工具可飞速处理数据。这些机器学习工具可学习数以亿计的观测样本,预测和学习同步进行。一些算法如随机森林和梯度助推在处理大数据时速度很快。机器学习处理数据的广度和深度很大。但统计模型一般应用在较小的数据量和较窄的数据属性上。
命名公约
下面一些命名几乎指相同的东西:

公式:
虽然统计模型和机器学习的最终目标是相似的,但其公式化的结构却非常不同
在统计模型中,我们试图估计f 函数 通过
因变量(Y)=f(自变量)+ 扰动 函数
机器学习放弃采用函数f的形式,简化为:
输出(Y)——> 输入(X)
它试图找到n维变量X的袋子,在袋子间Y的取值明显不同。
预测效果和人力投入
自然在事情发生前并不给出任何假设。 一个预测模型中越少的假设,越高的预测效率。机器学习命名的内在含义为减少人力投入。机器学习通过反复迭代学习发现隐藏在数据中的科学。由于机器学习作用在真实的数据上并不依赖于假设,预测效果是非常好的。统计模型是数学的加强,依赖于参数估计。它要求模型的建立者,提前知道或了解变量之间的关系。
结束语
虽然机器学习和统计模型看起来为预测模型的不同分支,但它们近乎相同。通过数十年的发展两种模型的差异性越来越小。模型之间相互渗透相互学习使得未来两种模型的界限更加模糊。
原文链接:
http://www.analyticsvidhya.com/blog/2015/07/difference-machine-learning-statistical-modeling/
原文作者:TAVISH SRIVASTAVA
翻译:数据工匠
更多阅读:

2015 年,优秀的可视化作品生机勃勃,我可以确定,明年也会有很多好作品。横跨不同主题和应用形式的项目大量涌现,但如果让我选一个年度主题的话,那一定是“教学”,不管是通过解释说明,模拟说明还是深刻分析的方式。有时候会感到可视化创作者很大胆,试着让读者们不再用惯有的思维方式来理解数据和统计学。我很喜欢这一点。
以下是我选出的 2015 最佳项目。按照惯例,排名不分先后。同时,也有很多不在这个名单上的作品,它们同样很优秀。
我们一起来看看它们。
1.亲爱的数据
这是一个值得跟踪的有趣项目,它涉及的两个话题——可视化和自我监测——引起了我的注意。

亲爱的数据是一个 Stefanie Posavec 和 Giorgia Lupi 做的一年项目。每个人会追踪一周中每天发生的事情,比如每个人接多少次电话,然后把这些数据可视化在一张明信片上。然后他们把这些明信片寄给对方—— Lupi 现居纽约而 Posavec 住在伦敦。
2.你来画:家庭收入如何预测孩子的大学入学几率
感觉今年似乎是挑战读者如何在一个更高的统计学视角上理解数据的一年。

纽约时报 Upshot 的 Gregor Aisch, Amanda Cox 和 Kevin Quealy 请读者画一条反映家庭收入和上大学孩子数百分比的线。所以你能看到你自己画的线,真实数据画出的线和其他人是怎么看待这个关系的。
关于Upshot/New York Times 和数据假设,参见 this quick puzzle to test your pattern-finding ability (快速测试你的模式识别能力)和 3-D chart of the economy’s future(经济未来发展3D图)。
3.“黑”出你的科学荣耀
纽约时报的 538 也通过他们的可视化互动进行了一些数据科学教学活动。其中最好的一节课是教人们如何通过“窃取 P 值”( p-hacking )来从同一数据集中得到你想要的结果.

这个项目发布的时候正是一个刚毕业的学生被曝出伪造数据的时候(hyperlink)。Christie Aschwanden和Ritchie King的重点不是怀疑一个荒唐的结果是如何通过了严格的同行评审的,相反,他们想说的是,科学地做研究并解释数据才是真正的难点(阅读更多)。
4.制作歌曲“你现在在哪里”
纽约时报的这个团队做了一个有关 Justin Bieber 的访谈,不仅不错,还很有趣。

尽管 Bieber 更像一个配角,因为 Diplo 和 Skrillex 才是详尽研究如何制作一首大卖歌曲的人,但是这个配在视频旁边的音乐可视化作品可以帮助你更好地理解音乐家们到底在说什么。
5.麻疹如何在接种了疫苗的儿童中传播及何时不传播
卫报的 Rich Harris,Nadja Popovich 和 Kenton Powell 展示了当一个国家的孩子们不接种麻疹疫苗时会发生什么。

作为父母,我想把这整个列表做成交互式的。
6.机器学习的可视化介绍
机器学习似乎像一个有魔力的概念,仿佛意味着一个机器人可以不受你的教导去做奇怪的事。Stephanie Yee 和 Tony Chu 对此用一个可视化例子进行了解谜。

这个可视化例子如卷轴般带着你一步一步了解机器是如何“学习”的。过渡图表让整个图衔接得非常顺畅。现有成果似乎是一个系列项目的第一部分,但是我们可能得等一段时间才能看到后面的。
7.第二次世界大战的结束
Neil Halloran 的这个项目的一部分是记录,另一部分是交互式可视化,二者无缝衔接在了一起。

我很惊讶地发现并没有很多人做这个类型的项目。当我意识到他们在做这样一个项目时,我非常希望这个能继续下去(阅读更多)。
8. 2014 年是有记录以来最热的一年
最直观的可视化这类数据的方式是单线图。但把线进行分解后,我们可以得到更多的信息。

彭博社的 Tom Randall 和 Blacki Migliozzi 做的这张动态图展示了月度平均气温。每条线代表一个完整的年份,随着时间由远到近,这条线在几英寸几英寸地升高。
9.网络效应
距离上一次看到 Jonathan Harris 的这类项目已经过去一段时间了

他和 Greg Hochmuth 合作了这个项目,“网络效应”是对整个互联网的点评,可以让人通过一种奇妙而引人入胜的方式了解互联网的方方面面,一次花几分钟。
10.常用比喻
“比喻修辞是写作者常用的,在读者脑海中有特定形象的,一种工具和写作习惯”。Bocoup 数据可视化团队做的“常用比喻”项目研究了比喻修辞中常用的词。

如果你想了解电影里的性别角色和人物性格,这个项目正是你要找的那个。
原文链接:http://flowingdata.com/2015/12/22/10-best-data-visualization-projects-of-2015/
原文作者:NATHAN YAU
译者:Fibears
via:数据工匠(微信订阅号ID:shujugongjiang)
更多阅读:

在过去的一年中,我们有幸通过RE•WORK节目与从事人工智能和计算机科学方面的许多大牛进行交流,我们期待在2016年会晤更多的专家,并向他们学习。
作为Q&A系列的一部分,我们邀请了一些深度学习方面最为资深的人士,来预测深度学习领域未来5年的可能发展情况。
未来5年我们可能看到深度学习会有怎样的发展?
Ilya Sutskever,OpenAI研究总监:我们应该会看到更为深层的模型,与如今的模型相比,这些模型可以从更少的训练样例中学习,在非监督学习方面也会取得实质性进展。我们应该会看到更精准有用的语音和视觉识别系统。
Sven Behnke,波恩大学全职教授、自主智能系统小组负责人:我期望深度学习能够越来越多地被用于多模(multi-modal)问题上,在数据上更结构化。这将为深度学习开创新的应用领域,比如机器人技术,数据挖掘和知识发现。
Christian Szegedy,谷歌高级研究员:目前深度学习算法和神经网络的性能与理论性能相去甚远。如今,我们可以用五到十分之一的成本,以及十五分之一的参数来设计视觉网络,而性能比一年前花费昂贵成本设计出的网络更优,这完全凭借改善的网络架构和更好的训练方法。我坚信,这仅仅只是个开始:深度学习算法将会更高效,能够在廉价的移动设备上运行,即使没有额外的硬件支持或是过高的内存开销。
Pieter Abbeel,加州大学伯克利分校计算机科学副教授、Gradescope联合创始人:有很多技术都基于深度监督式学习技术,视频技术也是一样,搞清楚如何让深度学习在自然语言处理方面超越现在的方法,在深度无监督学习和深度强化学习方面也会取得显著进步。
Eli David,Deep Instinct CTO:在过去的两年中,我们观察到,在大多数使用了深度学习的领域中,深度学习取得了极大的成功。即使未来5年深度学习无法达到人类水平的认知(尽管这很可能在我们有生之年发生),我们也将会看到在许多其他领域里深度学习会有巨大的改进。具体而言,我认为最有前途的领域将是无监督学习,因为世界上大多数数据都是未标记的,而且我们大脑的新皮层是一个很好的无监督学习区域。
Deep Instinct是第一家使用深度学习进行网络安全研究的公司,在今后几年,我希望有更多的公司使用深度学习进行网络安全研究。然而,使用深度学习的门槛还是相当高的,尤其是对那些通常不使用人工智能方法(例如,只有少数几个解决方案采用经典机器学习方法)的网络安全公司,所以在深度学习成为网络安全领域广泛运用的日常技术之前,这还将需要数年时间。

Jörg Bornschein,加拿大高级研究所(CIFAR)全球学者:预测未来总是很难。我希望无监督、半监督和强化学习方法将会扮演比今天更突出的角色。当我们考虑将机器学习作为大型系统的一部分,比如,在机器人控制系统或部件中,掌控大型系统计算资源,似乎很明显地可以看出,纯监督式方法在概念上很难妥善解决这些问题。
Ian Goodfellow,谷歌高级研究科学家:我希望在五年之内,我们将可以让神经网络总结视频片段的内容,并能够生成视频短片。神经网络已经是视觉任务的标准解决方案了。我希望它也能成为NLP和机器人任务的标准解决方案。我还预测,神经网络将成为其他科学学科的重要工具。比如,神经网络可以被训练来对基因、药物和蛋白质行为进行建模,然后用于设计新药物。
Nigel Duffy,Sentient Technologies CTO:目前大数据生态系统一直专注于收集,管理,策展大量数据。很明显,在分析和预测方面也有很多工作。从根本上说,企业用户不关心那些。企业用户只关心结果,即“这些数据将会改变我的行为方式吗?将会改变我做出的抉择吗?”我们认为,这些问题是未来5年需要解决的关键问题。我们相信,人工智能将会是数据和更好的决策之间的桥梁。
很明显,深度学习将会在演变中起到显著的作用,但需要与其他人工智能方法结合。在接下来的5年里,我们会看到越来越多的混合系统中,深度学习用于处理一些难以感知的任务,而其他人工智能和机器学习(ML)技术用于处理其他部分的问题,如推理。

Charlie Tang,多伦多大学机器学习小组博士生:深度学习算法将逐步用于更多的任务并且将“解决”更多的问题。例如,5年前,人脸识别算法的准确率仍然比人类表现略差。然而,目前在主要人脸识别数据集(LFW)和标准图像分类数据集(Imagenet)上算法的表现已经超过了人类。在未来5年,越来越难的问题,如视频识别,医学影像或文字处理将顺利由深度学习算法解决。我们还可以看到深度学习算法被移植到商业产品中,就像10年前人脸检测如何被纳入相机中一样。
原文:Deep learning experts discuss the next 5 years
译者/刘翔宇
更多阅读:
但问题是,谷歌现在需要检索250亿个页面,而这些页面上大约95%的文本仅由大约一万个单词组成。也就是说,对于大多数搜索而言,将会有超级多的网页含有搜索短语中的单词。我们所需要的其实是这样一种办法(或称算法),它能够将这些符合搜索条件的网页按照重要程度进行排序,这样才能够 将最重要的页面排在最上面 。
本文将介绍谷歌的网页排序算法(PageRank Algorithm),以及它如何从250亿份网页中捞到与你的搜索条件匹配的结果。它的匹配效果如此之好,以至于“谷歌”(google)今天已经成为一个被广泛使用的动词了。
如何辨别谁重要
如果你曾建立过一个网页,你应该会列入一些你感兴趣的链接,它们很容易使你点击到其它含有重要、可靠信息的网页。这样就相当于你肯定了你所链接页面的重要性。谷歌的网页排序算法每月在所有网页中进行一次受欢迎程度的评估,以确定哪些网页最重要。网页排序算法的提出者,谢尔盖?布林(Sergey Brin)和拉里?佩奇(Lawrence Page)的基本想法是: 一个网页的重要性是由链接到它的其他网页的数量及其重要性来决定。
我们对任意一个网页P,以I(P)来表述其重要性,并称之为网页的网页排序。在很多网站,你可以找到一个近似的网页排序值。(例如,美国数学会的首页目前的网页排序值为8,最高分是10。你可以试试找到一个网页排序值为10的网页吗?)这个网页排序值仅是一个近似值,因为谷歌拒绝提供真实的网页排序值,以阻止那些试图干扰排序的行为。
网页排序是这样确定的。假定网页Pj有lj个链接。如果这些链接中的一个链接到网页Pi,那么网页Pj将会将其重要性的1/lj赋给Pi。 网页Pi的重要性就是所有指向这个网页的其他网页所贡献的重要性的加和。 换言之,如果我们记链接到网页Pi的网页集合为Bi,那么

这或许让你想起“先有鸡还是先有蛋”的问题:为了确定一个网页的重要性,我们首先得知道所有指向它的其他网页的重要性。然而,我们可将这个问题改写为一个更数学化的问题。
首先建立一个矩阵,称为超链矩阵(hyperlink matrix),H=[Hij],其中第i行第j列的元素为

注意到H有一些特殊的性质。首先,它所有的元都是非负的。其次,除非对应这一列的网页没有任何链接,它的每一列的和为1。所有元均非负且列和为1的矩阵称为随机矩阵,随机矩阵将在下述内容中起到重要作用。
我们还需要定义向量I=[I(Pi)],它的元素为所有网页的网页排序—— 重要性的排序值 。前面定义的网页排序可以表述为

换言之,向量I是矩阵H对应特征值1的特征向量。我们也称之为矩阵H的平稳向量(stationary vector)。
让我们来看一个例子。下图所示为一个网页集合(8个),箭头表示链接。

其相应的矩阵为

这说明网页8的受欢迎程度最高。下图是阴影化的图,其中网页排序值越高的网页阴影越浅。

计算平稳向量
有很多方法可以找到一个方阵的特征向量。然而,我们面对的是一个特殊的挑战,因为矩阵H是一个这样的方阵,它的每一列都对应谷歌检索到的一个网页。也就是说,H大约有n=250亿行和列。不过其中大多数的元都是0;事实上,研究表明每个网页平均约有10个链接,换言之,平均而言,每一列中除了10个元外全是0。我们将选择被称为幂法(power method)的方法来找到矩阵H的平稳向量 I。
幂法如何实现呢?首先选择 I 的备选向量I0,进而按下式产生向量序列 Ik
![]()
这个方法是建立在如下的一般原理上:
一般原理:序列Ik将收敛到平稳向量I。
我们首先用个例子验证上面的结论。

一个自然的问题是,这些数字有什么含义。当然,关于一个网页的重要性,可能没有绝对的度量,而仅有比较两个网页的重要性的比例度量,如“网页A的重要性是网页B的两倍。”基于这一原因,我们可以用一个固定量去同乘以所有的重要性排序值,这并不会影响我们能获得的信息。这样,我们总是假定所有受欢迎程度值(popularity)的和为1,原因稍后解释。
三个重要的问题
自然而然产生的三个问题是:
序列Ik总是收敛吗?(即运算多次后,Ik和Ik+1几乎是一样的)
收敛后的平稳向量是否和初始向量I0的选取没有关系?
重要性排序值是否包含了我们想要的信息?
对目前的方法而言,上述三个的答案都是否定的!下面,我们将看看如何改进我们的方法,使得改进后的算法满足上述三个要求。 先看个非常简单的例子。考虑如下包含两个网页的小网络,其中一个链接到另一个:

下例展示了算法的运行过程:

在这个例子中,两个网页的重要性排序值均为0,这样我们无法获知两个网页之间的相对重要性信息。问题在于网页P2没有任何链接。因此,在每个迭代步骤中,它从网页P1获取了一些重要性,但却没有赋给其他任何网页。这样将耗尽网络中的所有重要性。没有任何链接的网页称为悬挂点(dangling nodes),显然在我们要研究的实际网络中存在很多这样的点。稍后我们将看到如何处理这样的点,在此之前我们先考虑一种新的理解矩阵H和平稳向量I的思路。
H的概率化解释
想象我们随机地在网上跳转网页;也就是说,当我们访问一个网页时,一秒钟后我们随机地选择当前网页的一个链接到达另一个网页。例如,我们正访问含有lj个链接的网页Pj,其中一个链接引导我们访问了网页Pi,那么下一步转到网页Pi的概率就是1/lj。
由于跳转网页是随机的,我们用Tj表示停留在网页Pj上的时间。那么我们从网页Pj转到网页Pi的时间为Tj/lj。如果我们转到了网页Pi,那么我们必然是从一个指向它的网页而来。这意味着

其中求和是对所有链接到Pi的网页Pj进行的。注意到这个方程与定义网页排序值的方程相同,因此I(Pi)=Ti。那么一个网页的网页排序值可以解释为随机跳转时花在这个网页上的时间。如果你曾经上网浏览过某个你不熟悉的话题的相关信息时,你会有这种感觉:按照链接跳转网页,过一会你会发现,相较于其他网页,你会更频繁地回到某一部分网页。正如谚语所说“条条大路通罗马,”这部分网页显然是 更重要的网页 。
基于这个解释,很自然地可以要求 网页排序向量I的所有元之和为1 。
当然,这种表述中还存在一个问题:如果我们随机地跳转网页,在某种程度上,我们肯定会被困在某个悬挂点上,这个网页没有给出任何链接。为了能够继续进行,我们需要随机地选取下一个网页;也就是说,我们假定悬挂点可以链接到其他任何一个网页。这个效果相当于将超链矩阵H做如下修正:将其中所有元都为0的列替换为所有元均为1/n的列,前者就对应于网页中的悬挂点。这样修正后悬挂点就不存在了。我们称修正后的新矩阵为S。
我们之前的例子,现在就变成了

换言之,网页P2的重要性是网页P1的两倍,符合你的直观认知了。
矩阵S有一个很好的性质,即其所有元均非负且每列的和均为1。换言之,S为随机矩阵。随机矩阵具有一些很有用的性质。例如,随机矩阵总是存在平稳向量。
为了稍后的应用,我们要注意到S是由H通过一个简单的修正得到。定义矩阵A如下:对应于悬挂点的列的每个元均为1/n,其余各元均为0。则S=H+A。
幂法如何实现?
一般而言,幂法是寻找矩阵对应于绝对值最大的特征值的特征向量。就我们而言,我们要寻找矩阵S对应于特征值1的特征向量。首先要说到的是最好的情形。在这种情形下,其他特征值的绝对值都小于1;也就是说,矩阵S的其它特征值都满足 λ <>
我们假定矩阵S的特征值为λj,且
![]()
对矩阵S,假设对应于特征值λj的特征向量存在一个基向量vj。这一假设在一般情况下并不一定要成立,但如果成立可以帮助我们更容易地理解幂法如何实现。将初始向量I0写成如下形式
![]()
那么

当j≥2时,因为所有特征值的绝对值小于1,因此这是λkj→0。从而Ik→I=c1v1,后者是对应于特征值1的一个特征向量。 需要指出的是,Ik→I的速度由 λ2 确定。当 λ2 比较接近于0时,那么λk2→0会相当快。例如,考虑下述矩阵

这个矩阵的特征值为λ1=1及λ2=0.3。下图左可以看出用红色标记的向量Ik收敛到用绿色标记的平稳向量I。

再考虑矩阵

其特征值为λ1=1及λ2=0.7。从上图右可以看出,本例中向量Ik收敛到平稳向量I的速度要慢很多,因为它的第二个特征值较大。
不顺之时
在上述讨论中,我们假定矩阵S需要满足λ1=1且 λ2 <>
假定网络关系如下:

在这种情形下,矩阵S为

那么我们可以得到

在这种情况下,向量序列Ik不再收敛。这是为什么?注意到矩阵S的第二个特征值满足 λ2 =1,因此前述幂法的前提不再成立。
为了保证 λ2 <><>
下面说明我们的方法行不通的另一个例子。考虑如下图所示的网络

在此例中,矩阵S为

注意到前四个网页的网页排序值均为0。这使我们感觉不太对:每个页面都有其它网页链接到它,显然总有人喜欢这些网页!一般来说,我们希望所有网页的重要性排序值均为正。这个例子的问题在于,它包含了一个小网络,即下图中蓝色方框部分。

在这个方框中,有链接进入到蓝色方框,但没有链接转到外部。正如前述中关于悬挂点的例子一样,这些网页构成了一个“重要性水槽”,其他四个网页的重要性都被“排”到这个“水槽”中。这种情形发生在矩阵S为可约(reducible)时;也即,S可以写成如下的块形式

实际上,我们可以证明:如果矩阵S不可约,则一定存在一个所有元均为正的平稳向量。
对一个网络,如果任意给定两个网页,一定存在一条由链接构成的路使得我们可以从第一个网页转到第二个网页,那么称这个网络是强连通的(strongly connected)。显然,上面最后的这个例子不是强连通的。而强连通的网络对应的矩阵S是不可约的。
简言之,矩阵S是随机矩阵,即意味着它有一个平稳向量。然而,我们同时还需要S满足(a)本原,从而 λ2 <>
最后一个修正
为得到一个本原且不可约的矩阵,我们将修正随机跳转网页的方式。就目前来看,我们的随机跳转模式由矩阵S确定:或者是从当前网页上的链接中选择一个,或者是对没有任何链接的网页,随机地选取其他网页中的任意一个。为了做出修正,首先选择一个介于0到1之间的参数α。然后假定随机跳转的方式略作变动。具体是,遵循矩阵S的方式跳转的概率为α,而随机地选择下一个页面的概率是1?α。
若记所有元均为1的n×n矩阵为J,那么我们就可以得到谷歌矩阵(Google matrix):
![]()
注意到G为随机矩阵,因为它是随机矩阵的组合。进而,矩阵G的所有元均为正,因此G为本原且不可约。从而,G存在唯一的平稳向量I,后者可以通过幂法获得。
参数α的作用是一个重要因素。若α=1,则G=S。这意味着我们面对的是原始的网络超链结构。然而,若α=0,则G=1/nJ。也即我们面对的是一个任意两个网页之间都有连接的网络,它已经丧失了原始的网络超链结构。显然,我们将会把α的值取得接近于1,从而保证网络的超链结构在计算中的权重更大。
然而,还有另外一个问题。请记住,幂法的收敛速度是由第二个特征值的幅值 λ2 决定的。而对谷歌矩阵,已经证明了第二个特征值的幅值为 λ2 =α。这意味着当α接近于1时,幂法的收敛速度将会很慢。作为这个矛盾的折中方案,网页排序算法的提出者谢尔盖?布林和拉里?佩奇选择α=0.85。
计算排序向量 I
到目前为止,我们所讨论的看起来是一个很棒的理论,然而要知道,我们需要将这个方法应用到一个维数n约为250亿的n×n矩阵!事实上,幂法特别适用于这种情形。
回想随机矩阵S可以写成下述形式

从而谷歌矩阵有如下形式

其中J是元素全为1的矩阵,从而
![]()
现在注意到,矩阵H的绝大部分元都是0;平均而言,一列中只有10个元是非零数。从而,求HIk的每个元时,只需要知道10个项即可。而且,和矩阵J一样,矩阵A的行元素都是相同的。从而,求AIk与JIk相当于添加悬挂点或者所有网页的当前重要性排序值。而这只需要一次即可完成。
当α取值接近于0.85,布林和佩奇指出,需要50到100次迭代来获得对向量I的一个足够好的近似。计算到这个最优值需要几天才能完成。
当然,网络是不断变化的。首先,网页的内容,尤其是新闻内容,变动频繁。其次,网络的隐含超链结构在网页或链接被加入或被删除时也要相应变动。有传闻说,谷歌大约1个月就要重新计算一次网页排序向量I。由于在此期间可以看到网页排序值会有一个明显的波动,一些人便将其称为谷歌舞会(Google Dance)。(在2002年,谷歌举办了一次谷歌舞会!)
总结
布林和佩奇在1998年创建了谷歌,正值网络的增长步伐已经超过当时搜索引擎的能力范围。在那个时代,大多数的搜索引擎都是由那些没兴趣发布其产品运作细节的企业研发的。在发展谷歌的过程中,布林和佩奇希望“推动学术领域更多的发展和认识。”换言之,他们首先希望,将搜索引擎引入一个更开放的、更学术化的环境,来改进搜索引擎的设计。其次,他们感到其搜索引擎产生的统计数据能够为学术研究提供很多的有趣信息。看来,联邦政府最近试图获得谷歌的一些统计数据,也是同样的想法。
还有一些其他使用网络的超链结构来进行网页排序的算法。值得一提的例子是HITS算法,由乔恩·克莱因伯格(Jon Kleinberg)提出,它是Teoma搜索引擎的基础。事实上,一个有意思的事情是比较一下不同搜索引擎获得的搜索结果,这也可以帮助我们理解为什么有人会抱怨谷歌寡头(Googleopoly)。
更多阅读:
- 更多的数据 & 更好的模型
并不是数据越多结果就越好,高质量的数据才能产生高质量的结果。多并不意味着好,事实上,有些情况下较少的数据反而效果更好,因此数据要适量,质量要高。 - 可能并不需要所有的大数据
组织可能积累了不同种类的大数据,但是并不是每一个场景都会用到所有的数据。大部分情况下,通过一些样本数据就能获得比较好甚至是比使用全量数据更好的效果。 - 有时候更复杂的模型并没有带来任何提升,但这并不意味着就不需要它了
如果将一个线性模型的特征数据作为另一个更复杂模型(例如非线性模型)的输入,而复杂模型产生的结果并没有任何提升,那并不意味着这个复杂模型就毫无意义。因为通常情况下只有更复杂的特征数据才需要更复杂的模型,对于简单的特征数据复杂模型往往难以发挥出自身优势。 - 学会处理展现偏见
系统通常会将那些预测的比较正确的结果展示给用户,用户会选择性的查看,但是用户不看的那部分并不一定就毫无吸引力。更好的选择是通过关注模型或者MAB分析用户的点击概率,合理地呈现内容。 - 认真思考训练数据
构建训练和测试数据的时候需要充分考虑结果和各种不同的场景。例如,如果要训练一个预测用户是否喜欢某部电影的分类器,那么产生数据的可能场景包括:用户看完电影并给出了一星的评价,用户看了5分钟、15分钟或者一小时之后离开,用户再次查看电影等,如何选择这些数据是需要经过深思熟虑的。 - UI是用户与算法通信的唯一方式
系统通过UI展现算法结果,用户通过UI提供算法反馈,它们应该是相互对应的关系,任何一个发生变化另一个也需要进行改变。 - 数据和模型是否已经足够好了?要有正确的评估方法
产品决策始终应该是数据驱动的。对于不同的问题,要选择正确的评估方法,例如,通过A/B测试来衡量不同特征数据,不同算法的优劣;通过脱机测试使用 (IR) 度量测试模型的性能。 - 分布式算法重要,但是理解它的分布式程度更重要
分布式/并行算法分三级:第一级针对总体的每一个子集,第二级针对超参数的每一种组合,第三级针对训练数据的每一个子集,每一级都有不同的要求。 - 慎重地选择超参数
要选择正确的度量标准自动化超参数的优化。 - 有些事情能线下做,有些不能,有些介于两者之间,为此需要支持多层次的机器学习。
- 隐式信号几乎总是打败显式信号
许多数据科学家认为隐式反馈更有用。但真的是这样么?实际上有些情况下结合不同形式的隐式和显式信号能更好地表示长期目标。 - 模型会学习你教给他的内容
机器学习算法并不是一个随意的过程,它的每一步都涉及到科学方法。模型要从训练数据、目标函数和度量中学习。 - 有监督的 + 无监督的学习
开发模型的时候不能简单地选择有监督的或者无监督的学习,它们各有长处,适用场景不同,用户需要根据具体情况同时迭代地使用它们,通过两种方法的融合获得更好的效果。
- 所有的事情都是一种集成(Ensemble)
使用机器学习的大部分应用程序都是一个集合体。你可以添加完全不同的方法(例如CF和基于内容的方式),你也可以在集成层使用许多不同的模型(例如LR、GDBT、RF和ANN)。 - 一个模型的输出可能是另一个模型的输入
确保模型的输出具有良好的数据依赖关系,例如可以容易地改变值的分布而不影响依赖它的其他模型。要尽量避免反馈循环,因为这样会在管道中造成依赖和瓶颈。另外,机器学习的模式设计也需要遵循最佳的软件工程实践,例如封装、抽象、高内聚和松耦合。 - 特征工程的失与得
良好的机器学习特征可重用、可转换、可解释并且可靠。捕获的特征越好,结果越精确。为了量化数据的属性必须将维度翻译成特征。 - 机器学习基础设施的两面性
任何机器学习基础设施都需要考虑两种不同的模式。模式1:机器学习实验需要扩展性、易用性和可重用性。模式2:机器学习产品不仅需要模式1的特性,还需要性能和可伸缩性。理想情况下,应该保持这两种模式尽可能地相近。 - 要能回答有关于模型的问题
必须能够向产品所有者解释模型的行为,知道如何使用模型,它需要哪些特征,导致失败的原因是什么;同时还需要知道产品所有者或投资者的期望,能够向他们介绍模型为产品带来了什么价值。 - 不需要分发机器学习算法
Hadoop/Spark这些“容易的”分布式计算平台也有一些陷阱,例如成本和网络延迟,实际上有些情况不使用它们也能很好的完成工作,通过智能数据样本、离线模式以及高效的并行代码等方法训练模型所花费的时间甚至比这些分布式平台要少的多。 - 数据科学 vs. 机器学习工程不为人知的故事
拥有强大的能够挖掘数据价值的数据科学家是非常值得的。但是既懂数据又有扎实工程技能的数据科学家非常稀少,通常情况下,构建数据科学家团队和机器学习工程团队并让他们通力配合才是比较好的方案。



via:InfoQ中文站
更多阅读:
数据技能的熟练程度
首先,Bob在AnalyticsWeek的研究包含了很多向数据专家提出的,有关技能、工作角色和教育水平等有关的问题调查。该调查过程针对5个技能领域(包括商业、技术、编程、数学和建模以及统计)的25个数据技能进行,将其熟练程度划分为了6个等级:完全不知道(0分)、略知(20分)、新手(40)、熟练(60分)、非常熟练(80分)和专家(100分)。这些不同的等级就代表了数据专家给予帮助或需要接受帮助的能力水平。其中,“熟练”表示刚好可以成功完成相关任务,为某个数据技能所能接受的最小等级。“熟练”以下的等级表示完成任务还需要帮助,等级越低需要的帮助越多;而“熟练”以上的等级则表示给予别人帮助的能力,等级越高给予的帮助可以更多。

Bob列出了4中不同工作角色对于25种不同数据技能的熟练程度。从上图可以看出,不同领域的专家对其领域内技能的掌握更加熟练。然而,即使是数据专家对于某些技能的掌握程度也达不到“熟练”的程度。例如,上图中浅黄色和浅红色区域都在60分以下。这些技能包括非结构化数据、NLP、机器学习、大数据和分布式数据、云管理、前端编程、优化、概率图模型以及算法和贝叶斯统计。而且,针对以下9种技能,只有一种类型的专家能够达到熟练程度——产品设计、商业开发、预算编制、数据库管理、后端编程、数据管理、数学、统计/统计建模以及科学/科学方法。
并非所有的数据技能都同等重要
接下来,Bob继续探讨了不同数据技能的重要性。为此,AnalyticsWeek的研究调查了不同数据专家对其分析项目结果的满意程度(也表示项目的成功程度):从0分到10分,其中0分表示极度不满意,10分表示极度满意。
对于每一种数据技能,Bob都将数据专家的熟练程度和项目的满意度进行了关联。下表就列出了4种工作角色的技能关联情况。表中关联度越高的技能就表示该技能对项目成功的重要性越高。而表中上半部分的技能相比于下半部分的技能对于项目结果更加重要。从表中可以看出,商业管理者和研究者的数据技能和项目结果的满意度关联度最高(平均r=0.30),而开发人员和创新人员的关联度只有0.18。此外,四种工作角色中不同数据技能之间的平均关联度只有0.01,表明对于一种数据专家是必须的数据技能对于其他数据专家未必是必须的。

数据科学驱动力矩阵:图形化结果
基于熟练程度和关联度的结果,Bob绘出了数据科学驱动力矩阵(Data Science Driver Matrix,DSDM)的示意图。其中,x轴代表所有数据技能的熟练程度,y轴代表技能与项目结果的关联度,而原点则分别对于熟练程度的60分和关联度的0.30。

结果解读:改善数据科学的实践
在DSDM中,每一种数据技能都会落在其中的一个象限中。由此,这种技能所代表的含义也就不同。
- 象限1(左上):该区域内的技能对于项目结果非常重要,但熟练程度却不高。那么,通过聘请掌握相关技能的数据专家或者加强相关技能的员工培训,项目就可以取得很好的改进。
- 象限2(右上):该区域内的技能对于项目结果非常重要,而掌握的熟练程度也不低。
- 象限3(右下):该区域内的技能对于项目结果而言为非必须,但掌握的熟练程度较高。因此,需要避免在这些技能上的过度投入。
- 象限4(左下):该区域内的技能对于项目结果而言为非必须,掌握的熟练程度也不高。但是,仍然没有必须要加强对这些技能的投入。
对于不同数据角色的DSDM
Bob针对商业管理者、研究者、开发人员和创新人员4中角色分别创建了DSDM,并主要关注落在第一象限的技能。
- 商业管理者对于商业管理者而言,第一象限中的技能包括统计学/统计建模、数据挖掘、科学/科学方法、大数据和分布式数据、机器学习、贝叶斯统计、优化、非结构化数据、结构化数据以及算法。而没有任何技能落在第二象限。
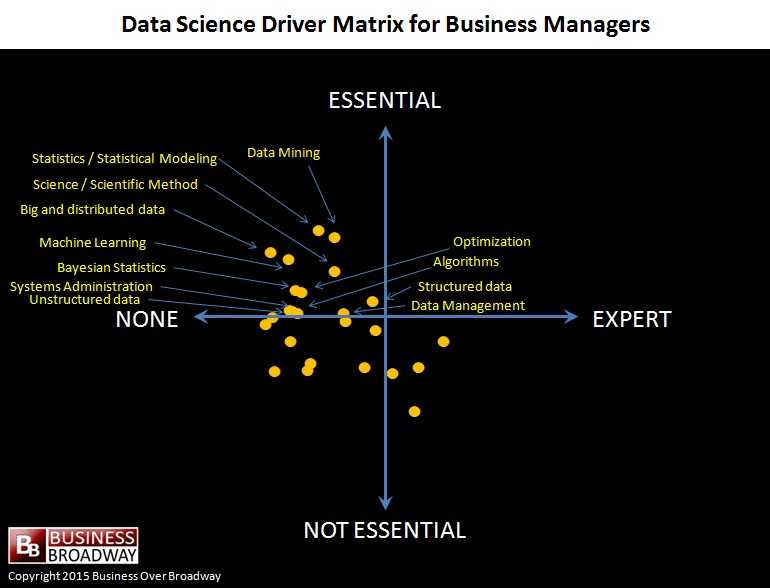
- 开发人员对于开发人员,只有系统管理和数据挖掘两种技能落在第一象限。绝大部分技能都落在第四象限。
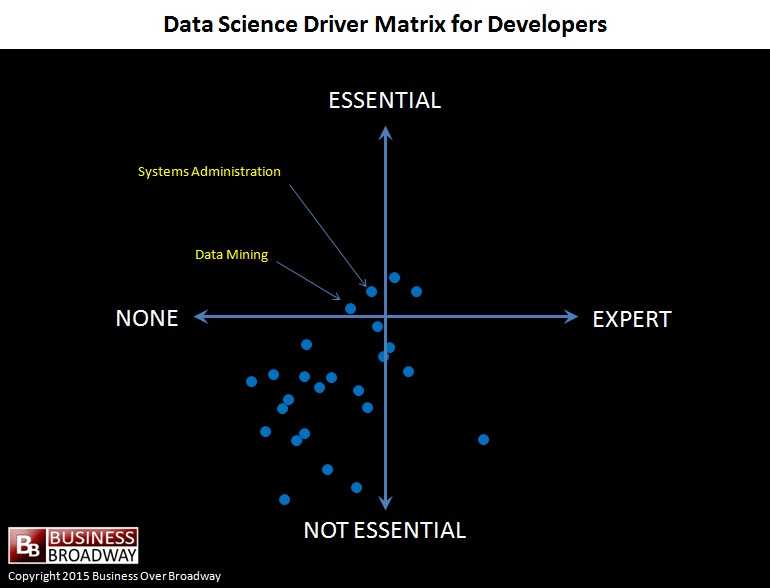
- 创新人员对于创新人员,共有数学、数据挖掘、商业开发、概率图模型和优化等五种技能落在第一象限。而绝大部分技能都落在第四象限。
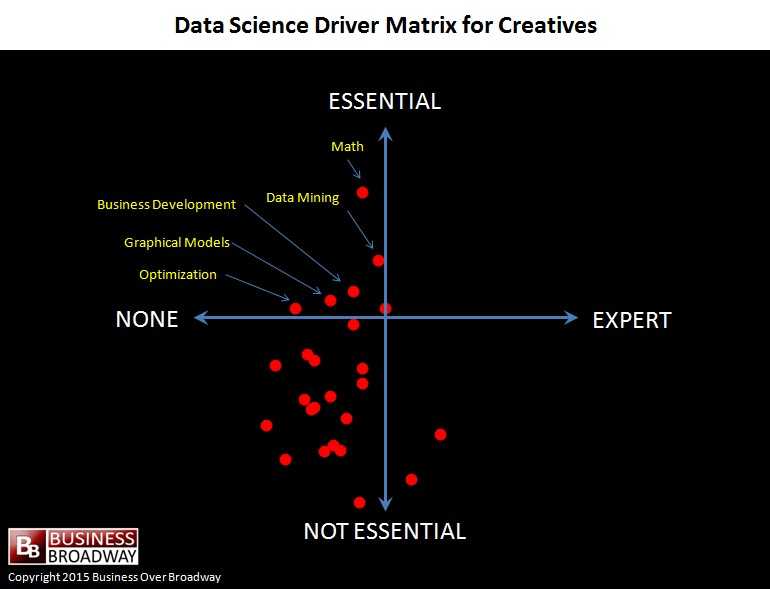
- 研究者对于研究者,共有算法、大数据和分布式数据、数据管理、产品设计、机器学习和贝叶斯统计等五种技能落在第一象限。而落在第二象限的技能却很少。
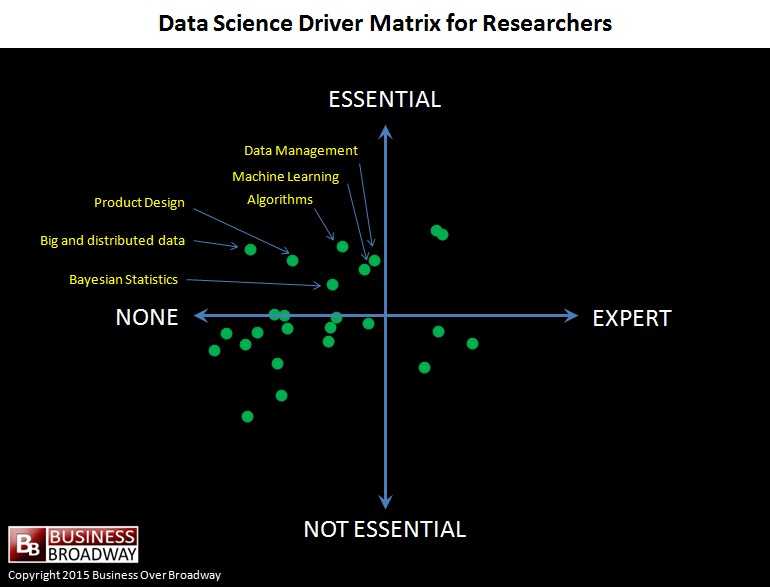




结论
从以上的研究中,Bob得到以下结论:
- 无论是对于哪个领域的专家,数据挖掘对于项目结果都十分重要。
- 商业管理者和研究者可以通过改善数据技能来增加数据分析项目的满意度。
- 某些特殊的数据技能对于一些分析项目的结果非常重要。
除此之外,Bob还提出团队合作对于项目成功也有着非凡的意义。
来自:InfoQ中文站
更多阅读:
:基于R语言的跨平台大数据机器学习与数据分析系统_000001.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000002.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000003.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000004.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000005.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000006.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000007.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000008.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000009.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000010.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000011.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000012.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000013.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000014.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000015.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000016.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000017.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000018.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000019.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000020.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000021.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000022.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000023.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000024.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000025.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000026.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000027.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000028.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000029.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000030.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000031.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000032.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000033.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000034.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000035.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000036.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000037.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000038.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000039.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000040.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000041.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000042.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000043.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000044.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000045.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000046.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000047.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000048.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000049.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000050.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000051.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000052.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000053.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000054.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000055.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000056.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000057.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000058.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000059.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000060.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000061.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000062.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000063.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000064.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000065.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000066.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000067.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000068.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000069.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000070.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000071.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000072.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000073.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000074.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000075.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000076.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000077.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000078.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000079.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000080.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000081.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000082.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000083.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000084.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000085.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000086.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000087.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000088.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000089.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000090.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000091.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000092.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000093.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000094.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000095.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000096.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000097.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000098.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000099.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000100.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000101.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000102.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000103.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000104.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000105.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000106.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000107.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000108.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000109.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000110.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000111.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000112.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000113.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000114.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000115.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000116.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000117.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000118.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000119.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000120.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000121.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000122.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000123.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000124.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000125.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000126.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000127.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000128.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000129.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000130.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000131.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000132.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000133.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000134.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000135.png)
:基于R语言的跨平台大数据机器学习与数据分析系统_000136.png)
更多阅读:

作者:学飞 从坠落开始
本篇综述主要参考了Liu Bing的《Sentiment analysis and opinion mining》,增加了一些自己的观点。
Liu B. Sentiment analysis and opinion mining[J]. Synthesis Lectures on Human Language Technologies, 2012, 5(1): 1-167.
摘要
近年来微博等用户自媒体的爆炸式增长,使得利用计算机挖掘网民意见不但变得可行,而且变得必须。这其中很重要的一项任务就是挖掘网民意见所讨论的对象,即评价对象。本文概览了目前主流的提取技术,包括名词短语的频繁项挖掘、评价词的映射、监督学习方法以及主题模型方法。目前抽取的问题在于中文本身的特性、大数据等。
引言
随着互联网信息的不断增长,以往的信息缺乏消失了。但海量的数据造成的后果是,人们越来越渴望能在快速地在数据汪洋中寻找属于自己的一滴水,新的信息缺乏诞生。对于电子商务来说,消费者希望能从众多的商品评论获得对商品的认识,进而决定是否购买,商家则希望从评论中获得市场对商品的看法,从而更好地适应用户的需求。类似的情况相继出现在博客、微博、论坛等网络信息聚合地。为了解决信息过载与缺乏的矛盾,人们初期手动地对网上海量而丰富的资源进行收集和处理,但瞬息万变的网民意见,突发的话题爆发很快让人手捉襟见肘。工程师们慢慢将开始利用计算机自动地对网络信息进行处理,意见挖掘由此应运而生。目前意见挖掘主要的研究对象是互联网上的海量文本信息,主要的任务包括网络文本的情感极性判别、评价对象抽取、意见摘要等。近年来,机器学习的发展让人们看到了意见挖掘的新希望。意见挖掘的智能化程度正在逐步提高。
评价对象(Opinion Targets)是指某段评论中所讨论的主题,具体表现为评论文本中评价词语所修饰的对象。如新闻评论中的某个人物、事件、话题,产品评论中某种产品的组件、功能、服务,电影评论中的剧本、特技、演员等。由于蕴含着极大的商业价值,所以现有的研究大部分集中于产品领域的评价对象的抽取,他们大多将评价对象限定在名词或名词短语的范畴内,进而对它们作进一步的识别。评价对象抽取是细粒度的情感分析任务,评价对象是情感分析中情感信息的一个重要组成部分。而且,这项研究的开展有助于为上层情感分析任务提供服务。因而评价对象抽取也就成为某些应用系统的必备组件,例如:
- 观点问答系统,例如就某个实体X,需要回答诸如“人们喜不喜欢X的哪些方面?”这样的问题。
- 推荐系统,例如系统需要推荐那些在某个属性上获得较好评价的产品。
- 观点总结系统,例如用户需要分别查看对某个实体X就某个方面Y的正面和负面评价。如图1所示为淘宝上某秋季女装的评价页面的标签。

图1:淘宝新款秋季女装的评价简述。其中“款式”、“材质”和“颜色”就是评价对象,红色表示对女装的正面评价,靛色表示负面评价。
这些任务的一个公共之处是,系统必须能够识别评论文本讨论的主题,即评价对象。评价对象作为意见挖掘的一个基本单元,一直是自然语言处理的热点。文章接下来将讨论评价对象抽取的研究现状。首先从名词的频率统计出发,阐述抽取评价对象的早期方法,然后在考虑评价对象与评价词的关系的基础上,讨论如何利用评价词发现已经出现和隐藏的评价对象、接着叙述经典的监督学习方法(隐马尔可夫方法和条件随机场)的优劣,最后详述了主题模型在评价对象抽取上的应用和展现。
研究现状
评价对象抽取属于信息抽取的范畴,是将非结构文本转换为结构化数据的一种技术。目前评价对象的抽取主要用于网络文本的意见挖掘。长如博客,短如微博都可以作为评价对象的抽取对象。在特定的情感分析环境下,所抽取的文本所处的领域往往能简化抽取的难度。一个最重要的特征就是文本中的名词。提取文本所描述的评价对象,并进一步地提取与评价对象相关的评价词,对于文本的自动摘要、归纳和呈现都有非常重要的意义。但需要注意的是评价词与评价对象的提取并没有什么先后关系,由于评价词与评价对象的种种联系。实践中往往会利用评价对象与评价词之间的特定映射来抽取信息。例如“这辆车很贵”中的“贵”是一个评价词(情感词),其评价的对象是车的价格。“贵”和“便宜”往往是用来描述商品的价格的。即使文本中没有出现“价格”,但依然可以判断其修饰的评价对象。第2小节将着重讨论这类隐式评价对象。前四节则探讨如何挖掘在文本中已经出现的评价对象。主流的方法有四种,分别是名词挖掘、评价词与对象的关联、监督学习方法和主题模型。
从频繁的名词开始
通过对大量商品评论的观察,可以粗略地发现评价对象大都是名词或者名词短语。Hu和Liu(2004)从某一领域的大量语料出发,先进行词性标记得到语料中的名词,再使用Apriori算法来发现评价对象。其具体步骤如下:
- 对句子进行词性标注,保留名词,去掉其它词性的词语。每个句子组成一个事务,用于第二步进行关联发现;
- 使用Apriori算法找出长度不超过3的频繁词集;
- 进行词集剪枝,去除稀疏和冗余的词集:
- 稀疏剪枝:在某一包含频繁词集f的句子s中,设顺序出现的词分别为,若任意两个相邻的词的距离不超过3,那么就称f在这一句子s中是紧凑的。若f至少在两条句子中是紧凑的,那么f就是紧凑的频繁词集。稀疏剪枝即是去除所有非紧凑的频繁词集;
- 冗余剪枝:设只包含频繁词集f,不包含f的超集的句子数目是频繁词集的p支持度。冗余剪枝会将p支持度小于最小p支持度的频繁词集去除。
这一方法尽管简单,但却非常有效。其原因在于人们对某一实体进行评价时,其所用词汇是有限的,或者收敛的,那么那些经常被谈论的名词通常就是较好的评价对象。Popescu和Etzioni(2005)通过进一步过滤名词短语使算法的准确率得到了提高。他们是通过计算名词短语与所要抽取评价对象的分类的点间互信息(Point Mutual Information,PMI)来评价名词短语。例如要在手机评价中抽取对象,找到了“屏幕”短语。屏幕是手机的一部分,属于手机分类,与手机的关系是部分与整体的关系。网络评论中常常会出现诸如“手机的屏幕…”、“手机有一个5寸的屏幕”等文本结构。Popescu和Etzioni通过在网络中搜索这类结构来确定名词短语与某一分类的PMI,继而过滤PMI较低的名词短语。PMI公式如下:
[Math Processing Error]
,其中a是通过Apriori算法发现的频繁名词短语,而d是a所在的分类。这样如果频繁名词短语的PMI值过小,那么就可能不是这一领域的评价对象。例如“线头”和“手机”就可能不频繁同时出现。Popescu和Etzioni还使用WordNet中的is-a层次结构和名词后缀(例如iness、ity)来分辨名词短语与分类的关系。
Blair-Goldensohn等人(2008)着重考虑了那些频繁出现在主观句的名词短语(包括名词)。例如,在还原词根的基础上,统计所有已发现的名词短语出现在主观句频率,并对不同的主观句标以不同的权重,主观性越强,权重越大,再使用自定义的公式对名词短语进行权重排序,仅抽取权重较高的名词短语。
可以发现众多策略的本质在于统计频率。Ku等人(2006)在段落和文档层面上分别计算词汇的TF-IDF,进而提取评价对象。Scaffidi等人(2007)通过比较名词短语在某一评论语料中出现的频率与在普通英文语料中的不同辨别真正有价值的评价对象。Zhu等人(2009)先通过Cvalue度量找出由多个词组成的评价对象,建立候选评价对象集,再从评价对象种子集出发,计算每个候选评价对象中的词的共现频率,接着不断应用Bootstrapping方法挑选候选评价对象。Cvalue度量考虑了多词短语t的频率f(t)、长度|t|以及包含t的其它短语集合[Math Processing Error]。计算公式如下:
[Math Processing Error]
评价词与对象的关系
评价对象与评价意见往往是相互联系的。它们之间的联系可以被用于抽取评价对象。例如情感词可以被用于描述或修饰不同的评价对象。如果一条句子没有频繁出现的评价对象,但却有一些情感词,那么与情感词相近的名词或名词短语就有可能是评价对象。Hu和Liu(2004)就使用这一方法来提取非频繁的评价对象,Blair-Goldenshohn等人(2008)基于情感模式也使用相似的方法。

图2:利用评价词发现评价对象,甚至是隐藏的评价对象
举例来说,“这个软件真有趣!”由于“有趣”是一个情感词,所以“软件”即被抽取作为评价对象。这一方法常常被用于发现评论中重要或关键的评价对象,因为如果一个评价对象不被人评价或者阐述观点,那么它也就不大可能是重要的评价对象了。在Hu和Liu(2004)中定义了两种评价对象:显式评价对象和隐式评价对象。Hu和Liu将名词和名词短语作为显式评价对象,例如“这台相机的图像质量非常不错!”中的“图像质量”,而将所有其它的表明评价对象的短语称为隐式评价对象,这类对象需要借由评价词进行反向推导。形容词和动词就是最常见的两种推导对象。大多数形容词和动词都在描述实体属性的某一方面,例如“这台相机是有点贵,但拍得很清晰。”“贵”描述的是“价格”,“拍”和“清晰”描述的是“图像质量”。但这类评价对象在评论中并没有出现,它隐含在上下文中。

图3:依存句法示例
如果评价词所对应的评价对象出现在评论中,评价词与评价对象之间往往存在着依存关系。Zhuang等人(2006)、Koaryashi等人(2006)、Somasundaran和Wiebe(2009)、Kessler和Nicolov(2009)通过解析句子的依存关系以确定评价词修饰的对象。Qiu等人(2011)进一步将这种方法泛化双传播方法(double-propagation),同时提取评价对象和评价词。注意到评价对象可能是名词或动词短语,而不只是单个词,Wu等人(2009)通过句子中短语的依存关系来寻找候选评价对象,再然后通过语言模型过滤评价对象。
尽管显式评价对象已经被广泛地研究了,但如何将隐式评价对象映射到显式评价对象仍缺乏探讨。Su等人(2008)提出一种聚类方法来映射由情感词或其短语表达的隐式评价对象。这一方法是通过显式评价对象与情感词在某一句子中的共现关系来发现两者的映射。Hai等人(2011)分两步对共同出现的情感词和显式评价对象的关联规则进行挖掘。第一步以情感词和显式评价对象的共现频率为基础,生成以情感词为条件,以显式评价对象为结果的关联规则。第二步对关联规则进行聚类产生更加鲁棒的关联规则。
监督学习方法
评价对象的抽取可以看作是信息抽取问题中的一个特例。信息抽取的研究提出了很多监督学习算法。其中主流的方法根植于序列学习(Sequential Learning,或者Sequential Labeling)。由于这些方法是监督学习技术,所以事先需要有标记数据进行训练。目前最好的序列学习算法是隐马尔可夫模型(Hidden Markov Model,HMM)和条件随机场(Conditional Random Field,CRF)。Jin和Ho等人使用词汇化的HMM模型来学习抽取评价对象和评价词的模式。Jakob和Gurevych则在不同领域上进行CRF训练,以获得更加领域独立的模式,其使用的特征有词性、依存句法、句距和意见句。Li等人(2010)整合了Skip-CRF和Tree-CRF来提取评价对象,这两种CRF的特点在于其既能学习词序列,也能发现结构特征。除了这两种主流的序列标注技术外。Kobayashi等人(2007)先使用依赖树发现候选评价对象和评价词对,接着使用树状分类方法去学习这些候选对,并对其分类。分类的结果就在于判断候选对中的评价对象与评价词是否存在评价关系。分类所依据的特征包括上下文线索、共现频率等。Yu等人(2011)使用单类SVM(one-class SVM,Manevitz和Yousef,2002)这一部分监督学习方法来提取评价对象。单类SVM的特点在于其训练所需的样本只用标注某一类即可。他们还对相似的评价对象进行了聚类,并根据出现的频率和对评论评分的贡献进行排序,取得较优质的评价对象。Kovelamudi等人(2011)在监督学习的过程中加入了维基百科的信息。

图4:评价对象标注示例,进而可用于序列学习
虽然监督学习在训练数据充足的情况下可以取得较好的结果,但其未得到广泛应用的原因也在于此。在当前互联网信息与日俱增的情况下,新出现的信息可能还未来得及进行人工标记成为训练语料,就已经过时了。而之前标记过的语料又将以越来越快的速度被淘汰。尽管不断涌现出各种半监督学习方法试图弥补这一缺憾,但从种子集开始的递增迭代学习会在大量训练后出现偏差,而后期的人工纠偏和调整又是需要大量的工作,且维护不易。有鉴于此,虽然学术界对在评价对象抽取任务上使用监督学习方法褒贬不一,但在工业界的实现成果却不大。
主题模型(Topic Model)
近年来,统计主题模型逐渐成为海量文档主题发现的主流方法。主题建模是一种非监督学习方法,它假设每个文档都由若干个主题构成,每个主题都是在词上的概率分布,最后输出词簇的集合,每个词簇代表一个主题,是文档集合中词的概率分布。一个主题模型通常是一个文档生成概率模型。目前主流的主题模型有两种:概率潜在语义模型(Probabilistic Latent Semantic Analysis,PLSA)和潜在狄利克雷分配(Latent Dirichlet Allocation,LDA)。Mei等人(2007)提出了一种基于pLSA的联合模型以进行情感分析,这一模型的特点在于是众多模型的混合,包括主题模型,正面情感模型和负面情感模型。如此多的模型自然是需要较多数据进行学习。这之后的其它模型大多是利用LDA挖掘评价对象。

图5:LDA示例
从技术上讲,主题模型是基于贝叶斯网络的图模型。但却可以被扩展用于建模多种信息。在情感分析中,由于每种意见都包含一个评价对象,那么就可以使用主题模型进行建模。但主题与评价对象还是有些不同的,主题同时包含了评价对象和情感词。就情感分析来说需要被分割这两者。这可以通过同时对评价对象和情感词建模来完成。还需注意的是主题模型不仅能发现评价对象,还能对评价对象进行聚类。
Titov和McDonald(2008)开始发现将LDA直接应用全局数据可能并不适用于识别评价对象。其原因在于LDA依靠文档中词共现程度和主题分布的不同来发现主题及其词概率分布。然而,某一商品下的评论往往都是同质的,也就是都是在讨论同一个商品,这使得主题模型在挖掘评价对象上表现不好,仅能在发现实体上发挥些余热(不同品牌和产品名称)。Titov和McDonald因此提出了多粒度主题模型。在全局数据上利用主题模型发现讨论实体,与此同时也将主题模型应于文档中的连续的数条句子。发现得到的某一类评价对象实际上是一个一元语言模型,即词的多项分布。描述相同评价对象的不同词被自动聚类。然而这一方法并没有将其中的评价词(情感词)加以分离。
通过扩展LDA,Lin和He(2009)提出了一个主题和情感词的联合模型,但仍未显式地分开评价对象和评价词。Brody和Elhadad(2010)认为可以先使用主题模型识别出评价对象,再考虑与评价对象相关的形容词作为评价词。Li等人(2010)为了发现评价对象及其褒贬评价词,提出了Sentiment-LDA和Dpeendency-sentiment-LDA两种联合模型,但既没有独立发现评价对象,也没有将评价对象与评价词分开。Zhao等人(2010)提出MaxEnt-LDA(Maximum Entrpy LDA)来为评价对象和评价词联合建模,并使用句法特征辅助分离两者。他们使用多项分布的指示变量来分辨评价对象、评价词和背景词(即评价对象和评价词以外的词),指示变量使用最大熵模型来训练其参数。Sauper等人(2011)则试图通过加入HMM模型达到区分评价对象、评价词和背景词的目的。但他们只应用在文本的短片段里。这些短片段是从评价论中抽取出的,例如“这电池正是我想要的”。这与Griffiths等(2005)于2005年提出的HMM-LDA颇有异曲同工之妙。Mukherjee和Liu(2012)从用户提供的评价对象种子集开始,应用半监督联合模型不断迭代,产生贴近用户需要的评价对象。联合模型的其它改进见于Liu等人(2007),Lu和Zhai(2008)和Jo和Oh(2011)。
在数据量巨大的情况下,抽取得到的评价对象往往也比较多。为了发现较为重要的评价对象,Titov和McDonald(2008)在从评论中找出评价对象的同时,还预测用户对评价对象的评价等级,并且抽取部分片段作为等级参考。Lu等人(2009)利用结构pLSA对短文本中各短语的依赖结构进行建模,并结合短评论的评价等级预测评论对象的评价等级。Lakkaraju等人在HMM-LDA(Griffiths等人,2005)的基础上提出了一系列同时兼顾在词序列和词袋的联合模型,其特点在于能发现潜在的评价对象。他们与Sauper等人(2011)一样都考虑了句法结构和语义依赖。同样利用联合模型发现和整理评价对象,并预测评价等级的还有Moghaddam和Ester(2011)。
在实际应用中,主题模型的某些缺点限制了它在实际情感分析中的应用。其中最主要的原因在于它需要海量的数据和多次的参数微调,才能得到合理的结果。另外,大多数主题模型使用Gibbs采样方法,由于使用了马尔可夫链蒙特卡罗方法,其每次运行结果都是不一样的。主题模型能轻易地找到在海量文档下频繁出现的主题或评价对象,但却很难发现那些在局部文档中频繁出现的评价对象。而这些局部频繁的评价对象却往往可能与某一实体相关。对于普通的全局频繁的评价对象,使用统计频率的方法更容易获得,而且还可以在不需要海量数据的情况下发现不频繁的评价对象。也就是说,当前的主题建模技术对于实际的情感分析应用还不够成熟。主题模型更适用于获取文档集合中更高层次的信息。尽管如此,研究者们对主题建模这一强大且扩展性强的建模工具仍抱有很大期望,不断探索着。其中一个努力的方向是将自然语言知识和领域知识整合进主题模型(Andrzejewski和Zhu,2009;Andrejewski等人,2009;Mukherjee和Liu,2012;Zhai等人,2011)。这一方向的研究目前还过于依赖于统计并且有各自的局限性。未来还需要在各类各领域知识间做出权衡。
其他方法
除了以上所谈的主流方法外,某些研究人员还在其它方法做了尝试。Yi等人(2003)使用混合语言模型和概率比率来抽取产品的评价对象。Ma和Wan(2010)使用中心化理论和非监督学习。Meng和Wang(2009)从结构化的产品说明中提取评价对象。Kim和Hovy(2006)使用语义角色标注。Stoyanov和Cardie(2008)利用了指代消解。
总结
大数据时代的到来不仅给机器学习带来了前所未有的机遇,也带来了实现和评估上的各种挑战。评价对象抽取的任务在研究初期通过名词的频率统计就能大致得到不错的效果,即使是隐含的对象也能通过评价词的映射大致摸索出来,但随着比重越来越大的用户产生的文本越来越口语化,传统的中文分词与句法分析等技术所起到的作用将逐渐变小,时代呼唤着更深层次的语义理解。诸如隐马尔可夫和条件随机场这样监督学习方法开始被研究者们应用到评价对象的抽取上,在训练数据集充足的情况下,也的确取得了较好的效果。然而仅靠人工标注数据是无法跟上当前互联网上海量的文本数据,像LDA这样扩展性好的无监督方法越来越受到人们的关注。但LDA目前还存在着参数多,结果不稳定等短板,而且完全的无监督方法也无法适应各种千差万别的应用背景下。展望未来,人们希望能诞生对文本——这一人造抽象数据——深度理解的基础技术,或许时下火热的深度学习(Deep Learning)就是其中一个突破点。
参考文献
- Hu M, Liu B. Mining and summarizing customer reviews[C]//Proceedings of the tenth ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2004: 168-177.
- Popescu A M, Etzioni O. Extracting product features and opinions from reviews[M]//Natural language processing and text mining. Springer London, 2007: 9-28.
- Blair-Goldensohn S, Hannan K, McDonald R, et al. Building a sentiment summarizer for local service reviews[C]//WWW Workshop on NLP in the Information Explosion Era. 2008.
- Ku L W, Liang Y T, Chen H H. Opinion Extraction, Summarization and Tracking in News and Blog Corpora[C]//AAAI Spring Symposium: Computational Approaches to Analyzing Weblogs. 2006: 100-107.
- Scaffidi C, Bierhoff K, Chang E, et al. Red Opal: product-feature scoring from reviews[C]//Proceedings of the 8th ACM conference on Electronic commerce. ACM, 2007: 182-191.
- Zhu J, Wang H, Tsou B K, et al. Multi-aspect opinion polling from textual reviews[C]//Proceedings of the 18th ACM conference on Information and knowledge management. ACM, 2009: 1799-1802.
- Zhuang L, Jing F, Zhu X Y. Movie review mining and summarization[C]//Proceedings of the 15th ACM international conference on Information and knowledge management. ACM, 2006: 43-50.
- Kobayashi N, Iida R, Inui K, et al. Opinion Mining on the Web by Extracting Subject-Aspect-Evaluation Relations[C]//Proceedings of AAAI Spring Sympoia on Computational Approaches to Analyzing Weblogs. AAAI-CAAW, 2006.
- Somasundaran S, Wiebe J. Recognizing stances in online debates[C]//Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP: Volume 1-Volume 1. Association for Computational Linguistics, 2009: 226-234.
- Kessler J S, Nicolov N. Targeting Sentiment Expressions through Supervised Ranking of Linguistic Configurations[C]//ICWSM. 2009.
- Qiu G, Liu B, Bu J, et al. Opinion word expansion and target extraction through double propagation[J]. Computational linguistics, 2011, 37(1): 9-27.
- Wu Y, Zhang Q, Huang X, et al. Phrase dependency parsing for opinion mining[C]//Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing: Volume 3-Volume 3. Association for Computational Linguistics, 2009: 1533-1541.
- Su F, Markert K. From words to senses: a case study of subjectivity recognition[C]//Proceedings of the 22nd International Conference on Computational Linguistics-Volume 1. Association for Computational Linguistics, 2008: 825-832.
- Hai Z, Chang K, Kim J. Implicit feature identification via co-occurrence association rule mining[M]//Computational Linguistics and Intelligent Text Processing. Springer Berlin Heidelberg, 2011: 393-404.
- Jin W, Ho H H, Srihari R K. A novel lexicalized HMM-based learning framework for web opinion mining[C]//Proceedings of the 26th Annual International Conference on Machine Learning. 2009: 465-472.
- Jakob N, Gurevych I. Extracting opinion targets in a single-and cross-domain setting with conditional random fields[C]//Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2010: 1035-1045.
- Li F, Han C, Huang M, et al. Structure-aware review mining and summarization[C]//Proceedings of the 23rd International Conference on Computational Linguistics. Association for Computational Linguistics, 2010: 653-661.
- Kobayashi N, Inui K, Matsumoto Y. Extracting Aspect-Evaluation and Aspect-Of Relations in Opinion Mining[C]//EMNLP-CoNLL. 2007: 1065-1074.
- Yu J, Zha Z J, Wang M, et al. Domain-assisted product aspect hierarchy generation: towards hierarchical organization of unstructured consumer reviews[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2011: 140-150.
- Manevitz L M, Yousef M. One-class SVMs for document classification[J]. The Journal of Machine Learning Research, 2002, 2: 139-154.
- Kovelamudi S, Ramalingam S, Sood A, et al. Domain Independent Model for Product Attribute Extraction from User Reviews using Wikipedia[C]//IJCNLP. 2011: 1408-1412.
- Hofmann T. Probabilistic latent semantic indexing[C]//Proceedings of the 22nd annual international ACM SIGIR conference on Research and development in information retrieval. ACM, 1999: 50-57.
- Blei D M, Ng A Y, Jordan M I. Latent dirichlet allocation[J]. the Journal of machine Learning research, 2003, 3: 993-1022.
- Mei Q, Ling X, Wondra M, et al. Topic sentiment mixture: modeling facets and opinions in weblogs[C]//Proceedings of the 16th international conference on World Wide Web. ACM, 2007: 171-180.
- Titov I, McDonald R. Modeling online reviews with multi-grain topic models[C]//Proceedings of the 17th international conference on World Wide Web. ACM, 2008: 111-120.
- Lin C, He Y. Joint sentiment/topic model for sentiment analysis[C]//Proceedings of the 18th ACM conference on Information and knowledge management. ACM, 2009: 375-384.
- Brody S, Elhadad N. An unsupervised aspect-sentiment model for online reviews[C]//Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics. Association for Computational Linguistics, 2010: 804-812.
- Li F, Huang M, Zhu X. Sentiment Analysis with Global Topics and Local Dependency[C]//AAAI. 2010.
- Zhao W X, Jiang J, Yan H, et al. Jointly modeling aspects and opinions with a MaxEnt-LDA hybrid[C]//Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2010: 56-65.
- Sauper C, Haghighi A, Barzilay R. Content models with attitude[C]. Association for Computational Linguistics, 2011.
- Griffiths T L, Steyvers M, Blei D M, et al. Integrating topics and syntax[C]//Advances in neural information processing systems. 2004: 537-544.
- Mukherjee A, Liu B. Aspect extraction through semi-supervised modeling[C]//Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics: Long Papers-Volume 1. Association for Computational Linguistics, 2012: 339-348.
- Liu Y, Huang X, An A, et al. ARSA: a sentiment-aware model for predicting sales performance using blogs[C]//Proceedings of the 30th annual international ACM SIGIR conference on Research and development in information retrieval. ACM, 2007: 607-614.
- Lu Y, Zhai C. Opinion integration through semi-supervised topic modeling[C]//Proceedings of the 17th international conference on World Wide Web. ACM, 2008: 121-130.
- Jo Y, Oh A H. Aspect and sentiment unification model for online review analysis[C]//Proceedings of the fourth ACM international conference on Web search and data mining. ACM, 2011: 815-824.
- Lu Y, Zhai C X, Sundaresan N. Rated aspect summarization of short comments[C]//Proceedings of the 18th international conference on World wide web. ACM, 2009: 131-140.
- Lakkaraju H, Bhattacharyya C, Bhattacharya I, et al. Exploiting coherence for the simultaneous discovery of latent facets and associated sentiments[J]. 2011.
- Moghaddam S, Ester M. Opinion digger: an unsupervised opinion miner from unstructured product reviews[C]//Proceedings of the 19th ACM international conference on Information and knowledge management. ACM, 2010: 1825-1828.
- Andrzejewski D, Zhu X. Latent Dirichlet Allocation with topic-in-set knowledge[C]//Proceedings of the NAACL HLT 2009 Workshop on Semi-Supervised Learning for Natural Language Processing. Association for Computational Linguistics, 2009: 43-48.
- Andrzejewski D, Zhu X, Craven M. Incorporating domain knowledge into topic modeling via Dirichlet forest priors[C]//Proceedings of the 26th Annual International Conference on Machine Learning. ACM, 2009: 25-32.
- Zhai Z, Liu B, Xu H, et al. Constrained LDA for grouping product features in opinion mining[M]//Advances in knowledge discovery and data mining. Springer Berlin Heidelberg, 2011: 448-459.
- Yi J, Nasukawa T, Bunescu R, et al. Sentiment analyzer: Extracting sentiments about a given topic using natural language processing techniques[C]//Data Mining, 2003. ICDM 2003. Third IEEE International Conference on. IEEE, 2003: 427-434.
- Ma T, Wan X. Opinion target extraction in Chinese news comments[C]//Proceedings of the 23rd International Conference on Computational Linguistics: Posters. Association for Computational Linguistics, 2010: 782-790.
- Meng X, Wang H. Mining user reviews: from specification to summarization[C]//Proceedings of the ACL-IJCNLP 2009 Conference Short Papers. Association for Computational Linguistics, 2009: 177-180.
- Kim S M, Hovy E. Extracting opinions, opinion holders, and topics expressed in online news media text[C]//Proceedings of the Workshop on Sentiment and Subjectivity in Text. Association for Computational Linguistics, 2006: 1-8.
- Stoyanov V, Cardie C. Topic identification for fine-grained opinion analysis[C]//Proceedings of the 22nd International Conference on Computational Linguistics-Volume 1. Association for Computational Linguistics, 2008: 817-824.
更多阅读:

文/李建平,来源:建行报
让历史告诉未来。客户价值分析就是通过数学模型由客户历史数据预测客户未来购买力,这是数据挖掘与数据分析中一个重要的研究和应用方向。RMF方法就是让历史告诉未来的趋势分析法,利用RMF方法科学地预测老客户未来的购买金额,然后对产品成本、关系营销费用等进行推算,即可按年、按季度、按月预测出客户未来价值。这里以信用卡为例,讨论和分析信用卡客户价值。
一、预测模型
对银行而言,预测客户未来价值能够使银行将传统的整体大众营销推进到分层差异化营销、一对一差异化营销的高度,对不同的分层客户采取不同的营销模式、产品策略和服务价格,从而推动和促进客户购买交易。
根据RFM方法,“客户价值”预测模型为:
客户未来价值 = 银行未来收益 – 未来产品成本 – 未来关系营销费用
对于信用卡客户,我们定义此处的“未来”是指未来一年(也可以是未来一季度)。“银行收益”包括信用卡年费、商户佣金、逾期利息,以及其他手续费等;“产品成本”即产品研发、维护和服务成本,包括发卡、制卡、换卡和邮寄等费用,以及其他服务费用;“关系营销费用”即关系维护和营销成本,包括商户活动、积分礼品兑换、营销宣传等。
RFM方法是目前国际上最成熟、最通用、最被接受的客户价值分析的主流预测方法。实际上,RFM方法是一整套客户价值分析方法中的一部分(其中,R:最近购买日Recency,F:购买频率Frequency,M:平均单次购买金额Monetary),但是RFM方法最具有代表性,其它还包括客户购买行为随机过程模型、马可夫链状态移转矩阵方法、贝氏机率推导状态移转概率方法和拟合回归分析方法等。
(一)预测未来收益
由于“银行收益”包括信用卡年费、商户佣金、逾期利息,以及其他手续费等,这里统一称为“购买金额”。因此,“客户未来购买金额”预测模型为:
客户未来购买金额 = 未来购买频率 * 未来平均金额 * 未来购买频率概率 * 未来平均金额概率
其中,未来购买频率、未来平均金额、未来购买频率概率、未来平均金额概率均可通过客户购买行为的随机过程模型来描述和求解。对于信用卡客户,“客户购买行为”包括刷卡、透支、取现、支付、分期等,以及客户消费习惯、还款习惯、收入贡献、信用额度、用卡来往区间、逾期时长、进件通路、客户服务和副卡的客户购买行为等。
根据RFM方法预测过程,随机过程模型除了推导和计算客户未来购买频率概率、未来平均金额概率的密度分配之外,还隐藏着客户未来购买频率、未来平均金额的状态移转期望值和概率。因此,除了使用随机过程模型之外,还需使用贝氏机率方法推导状态移转期望值和概率。
此外,要科学地分析和预测客户未来价值,有必要用长度和宽度的二维样本数据建立一套牢固、可靠的随机过程模型,样本越大,客户未来价值的预测结果就越接近未来的事实。其中二维样本数据是指客户购买频率与购买金额是两个相互独立的不同的行为维度,不具有相关性。
(二)预测未来产品成本和关系营销费用
RFM方法只能预测客户未来购买金额(或银行未来收益情况),却不能预测出未来产品成本和关系营销费用。而采取平均法或移动平均法将客户历史价值、历史关系营销费用直接应用到客户未来,显然不适合;同样,采取RFM方法的概率分析方法来推断客户未来价值也是不适合的。因为未来产品成本和未来关系营销费用并不是源自客户的随机行为,而是由银行整体产品成本控制和差异化营销决定的,其未来变化不一定按趋势平滑,未来客户的情况可能会出现逆反或抖动。因此,预测未来产品成本和关系营销费用需要采取其他方法。
首先要明确,未来产品成本和未来关系营销费用并不是随机现象,而是遵循各自发生的规律;且客户未来关系营销费用服从客户历史关系营销费用与购买金额的比例,即服从关系营销投入产出比。对于信用卡客户而言,通常以“年”为最小期数进行分析和预测,历史区间和未来区间是连续的,即两者之间无交易期数。所以,未来产品成本和未来关系营销费用的变化符合银行整体产品成本和营销费用的线性拟合回归规律。
因此,对于信用卡客户,“未来产品成本”预测模型为:
未来产品成本 = 未来购买金额 *(1-CRM毛利率),CRM毛利 = 购买金额 – 产品成本 – 关系营销费用
对于“未来关系营销费用”,定义:
Ratei = ∑客户历史关系营销费用/∑客户历史购买金额
Expensei = 客户历史最小关系营销费用(须大于0)
Monetaryi = 客户未来购买金额
X = Monetaryi * Ratei
因此,如果X>Expensei,那么“未来关系营销费用”=X。否则,如果Monetaryi<Expensei,那么“未来关系营销费用”=X;如果Monetaryi≥Expensei,那么“未来关系营销费用”=Expensei。
二、客户价值
从以上分析,客户价值 = CRM毛利 = 购买金额 – 产品成本 – 关系营销费用。因此,在完整的客户关系生命周期内(即从建立关系到未流失的最近一次交易),分析客户未来价值的意义远远大于分析客户历史价值,因此通常意义上的客户价值分析就是对客户未来的价值进行分析和预测。
对于预测出的客户未来价值的结果,可按客户价值分层,并将传统的整体大众营销推进到分层差异化营销、一对一差异化营销的高度,其立足点就是客户价值的差异化分析。
通过分析和预测客户未来价值,即可清楚一旦高端客户、大客户流失将会造成未来怎样的利润损失,也可以挖掘出那些临近亏损或负价值的客户,并进行置疑分析,找出对策。但同时也要认识到,即使预测出客户的未来价值较高,也只能说明其价值势能(即潜在购买力)较高,坐等客户主动上门的价值动能(实际购买力)是不现实的,还需要通过其他沟通交流和营销渠道(如人工坐席外呼、短信发送、微博私信、微信、邮件推送等)与客户互动,推动客户追加购买、交叉购买。
更多阅读:
移动分析和广告公司 Flurry在周二发布的一个报告中指出,美国人每天花在移动设备上的时间比坐在电视机前的时间多了将近十分钟。这个报告是一个混合了来自 Flurry自己和comScore公司的移动设备使用分析,以及来自美国劳工部的平均电视使用数据。Flurry表示美国人花费2小时48分钟看电视,而移动设备使用的时间是2小时57分钟。

Flurry的最新报告是受到Benedict Evans最近的演讲的启发,他是风投公司Andreessen Horowitz的合伙人。
故事背后的故事:Flurry的报告虽然有趣,但是只有当你购买了美国劳工部的数据时才起作用,它来自于一个被称为“美国时间使用调查”的自我报告研究。来自尼尔森公司的数字讲的却是另一个不同的故事。9月份,尼尔森发布的2014年第二季度跨平台报告中表示4-6月中,美国成年人每天平均花费在电视机前的时间是4小时36分钟
很多人同时使用这两者
值得注意的是,Flurry表示它不能测量出平均每天中,观看电视和移动设备使用有多少部分是重叠的。但是,它猜测重合的部分会很多。
考虑到我自己观看电视时,我会花费许多时间在自己的智能手机上。我可能在电影数据库上查一个男演员的名字,快速的回复邮件、和朋友发短信,或者在电视内容没意思时浏览Twitter和新闻。不管我在看什么,我的智能手机总是不离我左右。
即使你把更多的股票投在尼尔森公司的数字而不是美国劳工局的统计是,然而似乎智能手机和平板电脑将不可避免的取代花费在电视上的时间。包括在尼尔森在内的一些统计公司报道了移动设备使用的快速增长,特别是当提到APP时。
这也是有道理的。“因为更多的消费者几乎在每天每一个日常任务中使用移动设备,因此他们使用手机比他们使用电视多是唯一合理的解释。”Flurry在报告中说。
一份4月份的英国调查中表示,当问到英国的成年人如果必须放弃,他们最可能怀念哪一个设备。年龄越大的受访者,越可能选择电视作为他们最怀念的媒体活动。而年龄在16-34岁间的人的第一选择是智能手机。
正如Evans在他的演讲中说的那样“移动设备正在蚕食这个世界。”
但是,即使移动设备代替电视成为了关注的首位,但是内容紧随其后。电视巨头们将自己重新定义为所有平台的娱乐制作商。例如,CBS和HBO最近推出了独立的线上流媒体包,为他们的产品在移动主导的媒体未来搭了一个帐篷。
199IT编译自http://www.pcworld.com/article/2849239/watching-shows-online-is-more-common-now-flurry-says-but-tvs-hardly-dead-yet.html
更多阅读:
在econsultancy的最新的B2B实时营销报告中,它与Monetate联合,揭示出目前B2B实时营销的现状,揭示出的见解或许将挑战我们认为的实时营销对B2B的重要性的偏见。
例如,事实上65%的B2B公司正在实施某种形式的实时营销,并且有87%的公司认同实时营销作为行为、设备、地点和时间的集合是至关重要的。
完整的报告中可以发现,其突出显示出商业买家是如何不间断地明确他们的需求,以及实时营销的好处和挑战。
B2B公司是如何定义实时营销的?以及为什么它很重要?今天的公司在做什么,以及它如何为明天做打算?实时营销的优先权以及实现它们的必备功能。
报告是基于我们前期的调查——2014年实时营销调查报告,在报告中,Econsultancy 和 Monetate调查了将近900家B2C营销者,本次只将关注点放在B2B营销者上。
我们将简明的看一下实时营销对B2B公司意味着什么。
什么是实时营销?
随着我们的生活方式因为多设备的使用而变得越来越“永远在线”,并且这种易于连接性在不断改善,我们越来越多的要求与我们打交道的公司进行快速的、个性化的反应。
这导致了敏捷营销的增加。营销已经变得越来越少计划性,更灵活。
实时营销对B2B意味着什么呢?
与B2C市场相反,通过B2B开始的客户旅程包含了多重的决策人,有不同的议程、汇款和目标。
这导致通常的观念认为任何灵活或者速度都会立即被它所面临的巨量的过程所妨碍。当然即使B2C实时营销也需要一定的前期策划。
值得庆幸的是,认为B2B营销是一个缓慢的、多头治理的怪兽的这种观念正逐渐变得多余。正如我们报告建议的实时互动在经过思考的销售中,可能提供与与短期客户营销一样的价值。
实时营销意味着在合适的时间提供合适的内容,B2B和B2C公司适当的营销流程将能够在客户认为“现在”这个时间,提供内容和参与。
另一个需要记住的重要原因是,实际上,任何B2B客户将会有与B2C供应商接触的经验,他们的预期很可能一样。因此你尽可能的符合这些预期是必要的。
实时营销的益处
我们向受访者询问“你认为实时营销最大的好处是什么”

更好的客户体验无疑是这里的赢家。尽可能快的回复客户相关的信息,也为改善客户维系、改善转换和提高品牌认知等带来连锁反应。
实时功能不仅仅限于客户体验和参与,其他与销售有关的方面也将受益。
当谈到B2B时候,转换在时间线上常常走的更远,因此像下载或者注册这样的二级指标往往被测量。当询问实时营销对转换率的影响时,26%的B2B受访者表示是上升的,这与B2C公司的百分比完全一致。
更多阅读:

Opera Mediaworks发布了2014年移动广告状态报告。报告中包括了90%的全球顶级广告主,他们在平台上运行移动活动,覆盖超过8亿独立用户,跨越了17500多个出版商网站和APP。他们发现移动视频广告快速发展,Android取得进展。
Android继续赢得市场份额,截取了57.6%的流量份额,相对比iOS的份额为30.2%。Android在收益方面的差距也在缩小,第三季度上升了3%,收益占到了41.8%,iOS仍旧在收益方面处于领导地位占51.2%。

两个操作系统领导者的手机在流量和收入方面相比平板电脑来说都处于领导地位。这点在Android上尤为明显。
Opera Mediaworks发现2014年第三季度公布的iOS 8普及率比去年公布的iOS 7的普及率要慢。iOS 8发布一周后,其展现量占比只有28.55%,相比iOS 72013年9月发布后的比例为64.93%。
社交网络在展现量上占优势,但音乐、视频和媒体支配移动收益
2014年第三季度,社交网站和app以21.8%的展现量,继续引领移动展现量份额。音乐、视频和媒体网站及APP同样保持他们的收入创造,占移动收入的23.1%,

亚洲地区移动广告的增长在2014年第二季度后开始放缓,在第二季度它超过欧洲位居移动广告展现量第二位,广告展现量份额从去年的15.3%增长到27.4%。2014年第三季度,亚洲移动广告收益从4.9%上升到8.4%。
2014年第三季度欧洲移动广告收益份额占17.3%,美国继续位居首位,占全球份额的44%。
墨西哥和阿根廷在上一季度的收益出现明显增长。墨西哥从Opera Mediaworks移动广告收益前20位排行榜榜单的第10位跳升到第四位,阿根廷第一次进入榜单,排名第13位。
美洲(排除美国)目前收益份额占到了10.3%。
移动视频展现量今年增长了三倍多
2014年前三个季度,移动视频广告展现量增长了3.5倍。
以下是报告内容:
2014年第一季度,我们报道了我们全球广告展现量中有11%是富媒体,2.5%是视频。在本季度结束的时候,超过15%的全球流量是富媒体,其中一半以上的8.7%来自视频格式。由于设备需求和多样的广告客户资源,Opera Mediaworks发现移动视频广告的使用,不同的国家之间非常不同。

法国在移动视频广告展现量上位居领先——Opera Mediaworks交付的超过34%的广告展现量是视频格式。在西班牙和意大利,分别有27.9%和17.5%的移动广告展现量来自视频。但是,在美国这一比例只有10.5%,刚刚高于8.7%全球平均水平。也就是说,在美国十个移动广告中有一个是视频。
毫不意外的,娱乐是移动视频广告格式最多的。快消品公司和金融服务公司分列二三位,电子产品和零售在移动视频广告采用中最少。
出版商通常出产eCPM(每千次展示费用)高于横幅广告八倍的视频广告。即使在欧洲和美国这样的成熟市场,视频eCPM都比常规横幅广告高一倍。
iOS和平板视频广告展现量超过总体展现量份额
虽然iOS只占全球智能手机广告展现量的32%,但这一操作系统占全球视频广告展现量的48%。同样的平板电脑,包括Android和 iPad,视频广告展现量占比超过了他们的总体展现量份额。

更多阅读:
Facebook 的社交点击率年同比上升了148%,搜索点击率增长了23%,推动点击量上升了11%。
“通过持续增长的支出和性能证明,营销人员越来越清楚的看到了利用付费搜索和社交媒体创造的巨大的互补性活动的价值,”Kenshoo首席市场官Aaron Goldman表示,“营销人员通过Kenshoo运行他们的活动受益匪浅,在点击率和收益上相比去年同期获得巨大的增长。”
Kenshoo搜索和社交快照:2014年第三季度发现,付费搜索同比去年支出增长了19%,收益增长了22%。

更多阅读:
随之它的增长,APP产物和购买正在上升。

随着全球十亿的智能手机,人们购买APP.
这就是为什么APP商店优化(ASO)对营销人员和搜索优化专家来说如此火爆。可惜的是,还有许多神话再继续,还有许多秘密需要揭开。我们正在处理的是一个严肃的话题,我们不能搞砸它。
App商店优化有多重要?
首先,ASO真的非常重要。
为什么?不仅是因为APP是一个大产业,而且因为客户在寻找这些APP。Apptentive报道有63%的苹果APP客户浏览APP商店来寻找新的APP。

客户寻找新的APP有许多不同的方法——媒体、网站、朋友等等。但是毫无一问,客户们在寻找APP。尼尔森的数据与Apptentive的相呼应。

根据Google Play、Ankin Jain搜索和发现的主管,12%的全天活跃用户每天寻找APP。有庞大的50%的每日活跃用户至少一周寻找一次APP。在一个月的过程中,Google Play处理了600万个独特的搜索短语
针对ASO,我们需要越来越好的应对,来摆脱下述谬论
谬论一:改变你的标题通常适应高级搜索
真相:选择一个标题并坚持下去
毫无疑问,标题是app 商店优化的一个最重要的单元。 作为虔诚者,Google Play’搜索的主管在Inside Mobile Apps报告中表示,标题是最重要的单元。
作为回应,一些ASO开始转换标题来更好地适应高级搜索。他们每天创造了不同的各种各样的标题,改变关键词,增加关键词并重新命名他们的产品。然而这样做,对排名毫无作用。事实上,会伤害它。在前期的关于ASO的文章中, Robi Ganguly指出:
“改变你的标题,常常包括不同的关键词是有害的。随着你的app开始排名靠前并获得更多的评论,关于你的app的消息也将通过口头传播起来,改变标题将让口头传播变得困难。一旦你选定一个标题,那就是它了,你最好让它是好的,以下是四个小窍门。”
1、让它不要太长——25个字符
短标题可以让用户在蛋屏幕上阅读。长标题会被切断。作为APP商店最重要的搜索数据之一,你不会希望它被砍掉。
下面的APP——Productivity Wizard在屏幕上只能看到它名字的部分。他们组好不要用这么长的名字,因为无法在app浏览屏幕上看它,就不太可能下载它。

2、让它有新意
为什么要有新意?搜索者要么是分类,要么是导航。用户在听到或看到的你APP后将进行导航搜索来进入它。如果标题有新意,它更可能被记住,并成功地被搜索。
导航搜索是像“愤怒的小鸟”和“印象笔记”这样,而不是查询像“鸟类游戏”或者“笔记APP”。
3、让它独特
独特和新意差不多,但是有一点不同。新意是突出在用户面前的。你不希望你的app迷失在诸如Flappy Pig, Flappy Wings, Flappy Fall, Flappy Hero, Flappy Monster, Flappy Nyan等等跟风的app的沼泽里,令人作呕。跟风app很少能像他们跟风的app那样成功。
搜索“flappy”会有2193个app产品结果。缺乏独特性的标题意味着你将迷失在人群中。

4、使用一个关键词,但不是关键词堆砌
关键词堆砌在ASO中和在搜索引擎优化中差不多。苹果报道“重复的或者不相干关键词在app标题的使用,描述或者促销描述将给用户带来不愉快的体验,导致一款app暂停。”

记住,你只有25个字符,一个简洁的标题加上一个短的关键词是你的全部余地。
谬论二:关键词不重要
真相:关键词很重要
有人认为,关键词对SEO(搜索引擎优化)很重要,排名对ASO很重要。因为ASO和SEO完全不同,许多优化在标题创作和描述上无需考虑关键词的重要性。
真相是关键词非常重要。关键词在你的标题和描述中很重要,不要忽视它,使用关键词。
MobileDevHQ关于标题关键词的研究:

包含关键字的APP标题比不包含的排名高出10.3%,这听起来并不是高很多。但是,在标题里加入关键字很容易,为什么不做呢?
回到文章开头调查的数据,记住多少用户在搜索APP。

App Store和Android Market有计算方法,这些计算方法使用传统的搜索方法——关键字,不要忽视关键字。
谬论三:所有的一切都与等级有关
真相:等级很重要,但不是全部
毫无争议的事实是等级很重要。从推送通知和app近乎乞讨来判断,你会认为等级是ASO中最重要的特征。
等级,作为app功能清单中最重要的特征,有影响用户进入或者下载app的可能性的作用。

真相是,虽然app等级很重要,但并不像大多数人认为的重要到会影响app的排名。
为了揭示出评级影响背后的真相,Inside Mobile Apps进行了一个研究。他们首先检查了随机采样了简单的搜索字词(1-25个结果),中等搜索字词(25-100个结果)和复杂的的搜索字词(101+个结果)来观察每一个app如何根据等级排名。
以下是他们针对iOS得出的等级/排名比较

Graph from insidemobileapps.com
第八名以后的那些app的等级急剧下滑。但有趣的是前八位的等级影响似乎并没有那么大,波动都是上上下下。在简单搜索字词中,研究者发现第十位排名的app等级低至1.09,坦白的说,很烂。
以下是Google Play对app的排名。不像iSO,在排名的末端出现大幅下滑,研究者怀疑“Google Play 对app发现和可见度的搜索算法似乎采用更加精英管理的方法。让更高质量的app上升到前面。”

Graph from insidemobileapps.com
有更多破坏等级是一切的谬论。甚至在图表顶端的一些高竞争性的app没有被高等级支持。看下图,没有人想被评为一星或二星,但是这就是事实,甚至在排名表的最前面。

Graph from insidemobileapps.com
当然,等级是好的。高等级很好。对用户来说,那些四星或五星的身份给人一个好的印象。但是,在排名方便,它的作用比我们想象的要低。
谬论四:只要在商店,人们就会发现它
真相:需要大量的下载来获得认可。
有一些ASO人员认为一款app,只要它在Google Play或者App Store就会被发现,会被下载,并会获得渴望的收益。请看下面的统计。
- 在2014年6月,iTunes App Store有120万app
- 在2014年6月,Google Play store有超过100万个app
有大量的app存在。为了成功的竞争,你需要更多的差异化,而不是仅仅是在标题和描述中用一些聪明的关键词。
你需要下载,下载的影响常常被低估。
这是一个艰难的交易。因为为了得到更多的下载,你需要更多的下载。以下让数据说话。

下载越多的App,排名就更高,就是这样。
下载速度很大程度上取决于你怎样的营销观点。根据SEW报告,高排名的App的下载速度具有广泛的差异化,这依赖于它们普及的路径。

Image from Search Engine Watch.
为了有组织的增加App的下载量,通常最好采用传统的营销路线——社交媒体、内容营销、PPC、邮件列表等等。一旦你慢慢获得下载,你就可能增加你的排名,然后获得更多的下载,更高的排名,更多的下载,直到达到临界点。
不要走那些骗子增加垃圾下载量来简单的增加他们的排名这样的路。这种算法是被编程的来自动下载的方法。例如自动的或者无机病毒的喷发下载。此外,据报道甚至能通过电子邮件巨大的潜在客户清单,识别垃圾邮件,让下载爆升。
谬论五:描述不是非常重要
真相:描述非常重要
据说ASO达不到极好,是因为他们在描述上失败了。
下面的报道声称可以将你训练为ASO忍者:
Description doesn’t make a difference.
他们的全权委托声明说:
从纯粹的ASO角度来说,描述方面并没有影响在App Store的搜索排名,换句话说,Google Play的算法在排名上考虑进去了你的app描述的内容
描述对Google Play和 App Store来说都很重要,即使描述的质量和关键词对排名的计算方法没有任何影响,它无法论证是否存在潜在的影响让用户下载app。反过来,这些下载统计对排名有重要的影响。
Search Engine Watch报道指出在App Store中第二位的影响排名的因素是“应用描述”直接排冠军后。他们指出“描述帮助你在App Store中得到更好的排名。”排名第一的是“专注于标题和描述数据的关键字的自然结合。”
AppTweak有类似的描述:
关键词对ASO有巨大的影响。事实上,不论是iOS apps标题或是关键词方面还是Google Play apps的标题或是描述,关键词对App Store运算法则有重要的影响,因此,他们需要明智的选择让app得到最大的可见度并获得最大被发现的机会。
结论
部分app商城成功只是简单的避开了误区,你不可能创造这个世界上下一个疯狂的小鸟或者一个十亿美元Instagram。但是伴随着充分的努力和足够的悟性,你能创造一个app被发现,被下载并让你成功。
更多阅读:

特别是搜索广告比2013年增长了92%,显示广告也几乎增长了这么多。

然而,全球来看,促进广告收入的广告类型却截然相反。移动搜索广告在北美和欧洲处于绝对优势地位,但是在亚太地区、中东和非洲、以及拉丁美洲却不是这样。

但是,从2012年到2013年,几乎所有地区移动搜索广告收入方面都增长了。

并且所有地区的搜索广告都增长了,拉丁美洲增长了354%。

7月,Covario的报告显2014年第二季度移动搜索广告在全球广告支出中占25%,同比增长了98%。

在另一份报告中,eMarketer 预测北美地区到2016年移动广告支出将占到全球移动广告支出的58%,拉丁美洲将以23%位居第二。

根据eMarketer,Google以88.5亿美元的净收入位居2013年全球移动广告收入的首位,Facebook2013年的净收入显示为20多亿美元。

全球范围内,Google占净收入份额的56%,Facebook占13%。
当谈到移动广告收入,eMarketer报告指出Google 和 Facebook占2013年移动广告增长的大部分。这两家公司的移动广告净收入增长了69.2亿美元,声称2013年额外增长的92亿美元中有75.2%是由移动广告构成的。
199IT编译
更多阅读:
西班牙移动营销协会(MMA Spain)近期报告指出,根据埃森哲咨询公司在2014年1-2月组织的一项调查发现,西班牙移动市场持续快速发展。

研究发现所有形式的移动营销支出在去年达到1.105亿欧元(1.473亿美元),年增长率达到19.9%,不到2011-2012年间增长率的一半(44.9%)。但是可预测的两位数增长率的下降表明了市场的逐渐成熟。
考虑到西班牙仍旧陷入在严重的经济紧缩中,这些结果更值得注意。许多广告商已经削减了他们的支出;eMarketer估计所有可测量的媒体支出从2012年的67.9亿美元下降至去年的62.5亿美元,预计今年的支出为63.4亿美元。然而对移动营销发展而言,2014年应该是又一个强劲之年。MMA Spain和埃森哲咨询公司预计支出将进一步增长17.2%,达到1.293亿欧元(1.724亿美元)。
需要注意的是,这些数据远远高于大多数的西班牙移动广告的支出预计。例如,国家 Interactive Advertising Bureau和Grupo Consultores近期估算出2013年西班牙移动广告支出只有不足4000万欧元(5330万美元)。但是MMA Spain和埃森哲咨询公司研究超出了广告支出本身,包括所有形式的移动营销,它还包含了技术和开发,以及生产成本等“幕后”支出。可以说,相比较小数量的移动广告,它提供了西班牙移动营销市场更为全面的情况。
即使移动营销预算发展,但西班牙移动营销者仍旧面临着严峻的挑战。像英国和美国这样移动文化相对先进的国家,广告商发现与当地众多居民不断变化的习惯保持同步非常困难,民众使用移动设备并且如今几乎在生活的各个领域应用移动设备。eMarketer预测今年在西班牙将有2230万人使用智能手机,这一数量在2015年将达到2600万,几乎占据人口的54%。

即使有一天这些消费者适应了智能手机或者平板电脑,对品牌营销人员来说需要花费几个月的时间来掌握广泛的移动应用的影响,并开始在他们的战略思维和预算计划中引入移动平台。毫无疑问这些变化正在发生,虽然是从MMA Spain和埃森哲咨询公司的数据得出的判断。
更多阅读:

带有本地目的搜索更可能在一天内引导店铺访问和销售。新的Google调查发现50%的手机用户在进行本地搜索后更可能访问店铺,而平板电脑或个人电脑消费者这一比例为34%。
Google同时表示这些人一旦到了店铺,他们会愿意购物,因为有18%的本地搜索导向销售,相比非本地化搜索的比例为7%。
Google的新研究关注于本地搜索意图和产生的结果——当人们进行本地搜索时候检索什么信息、在什么特定的设备上和本地搜索如何影响他们的决定和购买行为的。
这个研究的参与者自愿完成一个在线调查或者通过移动日志来记录他们的智能手机搜索和店内活动。
Google调查发现五分之四的被调查者使用搜索引擎来进行本地搜索,88%的人使用智能手机,84%的人使用个人电脑或平板电脑。

根据研究,被调查者在工作时间搜索,确定一个本地店铺的路线、看产品是否有库存或者本地店铺的地址。

消费者表示在以下情况他们相比在线购买更愿意到店铺去购买:
• 知道他们靠近店铺(30%)
• 可以更快的得到商品(35%)
• 价格更为优惠(31%)
15%的店内活动与智能手机搜索一个产品或进行价格对比有关。
超过60%的被调查者表示他们在广告中发现本地信息,这些本地信息中:
• 73%的智能手机用户表示方位在广告中非常重要,78%的个人电脑和平板电脑用户表示同样如此。
• 77%的个人电脑和平板电脑用户同样表示电话号码很重要,智能手机用户的这一比例为70%。
为了改善广告体验,这些被调查者表示他们希望可以根据他们的位置进行自定义设置。70%的个人电脑和平板电脑用户以及61%的智能手机用户表示他们希望可以自定义他们周围环境的广告。

本地广告也可以意外的赢得消费者。19%的被调查者基于本地广告,访问过一个计划外店铺并且进行购买。

在一个博文中,Google针对让本地广告更有针对性提出一些建议:
• 针对消费者的位置进行优化。广告商可以通过以更广泛的地理区域开始来获得更多消费者,例如整个美国,然后利用本地出价调整来对特定地区或邮政编码进行微调。
• 帮助消费者找到他们需要的。让人们可以更容易的找到他们最需要的信息。只需在广告上简单的附加上地址信息、电话号码或者在右边增加一个点击呼叫按钮,可以帮助消费者更快的采取行动。
• 吸引消费者靠近你的店铺。利用半径范围出价达到消费者在店铺附近的目的,并为本地搜索建立归因模型
更多阅读:
北美占移动广告的最大份额达41.9%,领先亚太(38.9%)、欧洲(17.3%)、中东和非洲(1.2%)以及拉丁美洲(0.7%)。
由于基础小,拉丁美洲是2013年增长最快的地区,增长率为215%(达到1.44亿美元),虽然北美已经是一个成熟的市场,但是增长仍旧达122%,达到81亿美元。欧洲的移动支出增长了90%,达到33亿美元,亚太增长了69%,达到75亿美元,中东和非洲增长45%,达到2.25亿美元。
在广告类型方面,移动显示广告增长最快,激增123%达到36亿美元,同时搜索广告上升92%达到49亿美元。这两种类型被智能手机广泛采纳,更多的价格实惠的数据计划推动移动内容使用和本地化搜索。来自短信的广告收益上升19.4%达到15亿美元,短信和彩信服务的增长可能放缓,转移向WeChat, Line和 WhatsApp这样的平台。
搜索广告达95亿美元,几乎占到移动广告收益总数的一半(48.9%),显示广告占据41.5%(80亿美元),短信功能占9.6%(19亿美元)。
IAB’s Mobile Marketing Center of Excellence 副总裁兼总经理Anna Bager认为数据表明移动手机正在成为营销媒体组合中关键的一部分。“尤其是,随着移动广告营销在计划、创作、购买和衡量上变得更容易了。很大一部分原因是由于程序化策略,它们让移动显示广告市场的运营效率激增。”
然而,IAB Europe的CEO Townsend Feehan表示,许多出版商还是要提高他们的移动广告策略和能力,因为数据增长主要来自嵌入式应用程序和本地化广告,而不是通过品牌活动。
这项研究结果是基于当地IABs报告数据和“统计和计量经济学模型“,数据对折扣和代理佣金进行了调整。IAB表示,建模数据是基于如智能手机普及率、3 g用户和短信量等变量。














199IT原创编译 转载请注明199IT
译者:Jane
更多阅读:
相比Twitter和 Pinterest,Facebook对小企业在短期内推动线下销售是一个更为有效的营销工具。
在G/O Digital最新发布的关于Facebook广告研究中,G/O Digital调查了1000名美国年龄在18-29岁的用户。发现有62%的受访者认为在他们们访问一个本地化企业前,Facebook是最有效的研究产品或服务的社交媒体网络,相比Pinterest (12%),Twitter (11%).

此外,84%的被调查消费者认为在Facebook上的本地经营或者报盘对他们店内购买决策有很大影响,有25%的人表示“它非常重要,并且我很可能在一周内进行店内购买。”
G/O Digital 的CMO Jeff Fagel表示:“就短期而言,对许多通过社交营销来推动店内活动和销售的小企业来说,最实惠的社交营销方法是使用Facebook。”Pinterest 和Twitter在他们较大的社交影响策略中无疑占有一席之地,但是它们适合不同的目标和支持不同的目标。
深入观察不同的营销策略会揭示出,40%的受访者表示Facebook提供的可以在当地商店兑换,最可能说服他们进行店内购买,其次是推广帖子(12%)和平台上的相片/视频(11%)。

有趣的是,虽然Facebook已经因为侵犯用户隐私而受到指责,他们的报告显示在权衡Facebook广告的价值和合理性时,本地关联性和个性化比隐私问题更重要
事实上,36%的受访者将“目标是基于您个人兴趣和过去的购买的广告”看作是最可能影响他们与小企业的Facebook广告互动,超过25%的受访者认为“目标是基于当前位置的广告”最有影响力。
“这些都是相关的”, Fagel表示,“例如,如果你在一个棒球比赛中提供给我优惠2美金的热狗,我不会介意我的手机观看被这则广告打断。因为它解决了我一个即时的、相关的需求:解决了我的饥饿并且同时给了我一个折扣。”
199IT原创编译自 译者 Jane
更多阅读:

但不久之前可不是这样。计算机技术相对来说是个新学科。19世纪30年代,库尔特·哥德尔、阿隆佐·丘奇、波斯特和阿兰·图灵发表了一系列标志性的文章,从学术领域开始研究计算机计算。这些文章建立了定义计算的数学基础,并讨论了实现方案。他们清楚自动计算的重要性,寻求其精确的数学基础;他们各自提出了不同的计算实现方案,很快发现这些方案本质上是等价的,在其中一个方案下的运算也能在另一个方案内进行。更值得注意的是,他们的模型都得到了同样的结论:某些现实领域的函数不能通过计算机运算解决,例如一个求值的计算机算法最终是否能完成计算,或陷入死循环中。
在这些文章所处的年代,“计算”和“计算机”这样的表述经常使用,但和今天的涵义略有不同。当时“计算”意味着机器遵循步骤计算数学函数,而“计算机”是做运算的家伙。为了纪念先驱者们引发的社会变革,第一代数字计算机项目的系统命名时都被设计者加上了后缀“-AC”,这两个字母是“自动计算机”的缩写,例如埃尼阿克(ENIAC),尤尼法克(UNIVAC)和EDSAC。
随着二战的开始,英美军方开始对应用计算机计算感兴趣了,将其用于弹道计算、航海图计算和破译密码,并委派了多个设计和建造电子数字计算机的项目。最终只有一个项目在战争结束前完成,这个项目是布莱切利公园(英国的密码破译中心)的最高机密,它利用图灵设计的方法破译了德军的英格玛密码。
随后的50年代,许多该计划的曾经参与者都创立了自己的计算机公司;50年代晚期,大学也开始提供相应的课程。自此之后,计算机研究领域和相关产业逐渐成长为现代巨兽。今天,那些网络数据中心据说消耗了世界1/3的电力。
计算机技术刚刚兴起时,那时的科学界和工程界认为它不过是个难解的题目,仅仅是附属于数学、电力工程或科学的一门应用技术而已。然而多年之后,携卷着无数新思想的计算机技术却反过来吸收了这些基础学科,打破了早期的各种预言。到1980年时,计算机技术已经发展到包括算法、数据结构、数值方法、程序语言、操作系统、网络、数据库、图论、人工智能和软件工程等等领域;芯片、个人电脑、因特网等伟大的技术成就走入了无数人的生活中;一系列的新行业被激发,包括网络科学、万维网科学、移动计算、企业计算、协同工作、虚拟空间保护、用户交互界面设计和信息可视化等。商业应用也带来了新的研究挑战,尤其是在社交网络、无限进化计算、音乐、视频、数字照片、视觉、大型多人在线游戏、用户生成内容等等方面。
“计算机技术”一开始并不叫这个名字,而是随潮流变化了好几次。40年代人们把它称作“自动运算”,50年代改叫“信息处理”;60年代进入学术界后,它在美国被称作“计算机科学”,在欧洲是“信息学”。80年代,已经分化出一系列学科:计算机科学、信息学、计算科学、计算机工程、软件工程、信息系统和信息技术。1990年,“计算机技术”成为这些核心学科的标准名称。
计算机计算范式
传统科学家们总是质疑计算机“科学”之名,他们认为,在计算机领域可以轻易看到工程范式和数学范式,但看不到什么科学范式;前二者描述系统的设计与实施以及对理论的论证,后者则是以实验证明假设的体系。除此之外,“科学”被认为是处理自然世界的学科,而计算机太“人工”了。
事实上,计算机科学是在这三种范式上建立起来的。有人认为计算机计算是应用数学的分支,部分又属于电力工程,或面向计算的科学。刚起步的四十年间,计算机技术聚焦于工程学部分的发展,例如建造可靠计算机、可靠的网络和可靠的复杂软件,吓人的挑战使人们全身心投入。到80年代,工程学问题大多被解决,计算机技术开始在网络、超级电脑和个人电脑的帮助下传播开来。80年代的科幻作家已经能预见到强大的计算机技术将帮助攻克科学界和工程界最难的问题了——那些人类史上的“大挑战”。世界各地的科学家都参与了计算科学运动,最高潮发生在1991年,美国国会通过了《高性能计算和通讯法案》(HPCC Act)以支持计算科学对许多重要问题的研究。
今天,通常的认识是计算机技术例证了科学和工程,但反过来科学和工程并未塑造计算机技术。到底是什么塑造了这门技术?什么是计算机计算范式?
从一开始先锋者们就在为这个计算范式问题头疼。历史上总共有三波较统一的观点。1967年,第一波浪潮由艾伦·纽厄尔、艾伦·佩利和赫伯特·西蒙领导。他们认为计算机技术和当时其它科学都不同,它有着独特的信息处理过程。其中诺贝尔经济学奖获得者西蒙走得更远,他称计算机技术为“一项人工科学”。当时流行的说法是:“计算机技术就是研究围绕计算机的现象。”
第二波浪潮聚焦于编程,一门设计信息处理进程的算法的技术。在70年代早期,计算机技术的先驱者艾兹赫尔·戴克斯特拉和高纳德强烈支持将算法分析作为统一主题。“计算机科学等于编程”成为这次运动的标语。当今年代,这个观点逐渐沉寂,因为计算机技术的发展早已超越了编程;公众眼中的编程者仅仅是敲代码的人。
第三次浪潮起源于70年代晚期布鲁斯·阿登领导的计算机科学与工程研究,宣称“计算机技术是信息处理的自动化”。此次研究的最终报告揭示了计算机计算的科学属性,向外行解释了许多艰深问题;但除此之外,其核心观点并未流行开来。
这三种定义最突出的特点在于,将计算机视为关注的中心对象。80年代的计算科学运动开始破陈出新:计算机不只是科学工具,也是思考和探索科学的新方法。90年代晚期,以诺贝尔获得者大卫·巴尔的摩和认知科学家侯世达为代表的生物学界将生物学称作信息科学,认为DNA转录是自然信息处理过程,这标志着计算机本身已基本脱离关注核心。大量计算机科学家与生物学家合作,研究DNA信息处理的本质、探寻何种算法控制了这一处理过程。
感受一下生物学对计算范式作出的区分。首先,有些信息处理过程是自然界产生的;其次,我们不知道所有的自然信息处理是否都依据算法进行。第二点挑战了传统认知中将算法和编程置于计算机计算的核心,意味着信息处理比算法更基础更重要。
其它领域的科学家也得到了同样结论,包括研究量子运算和加密的物理学家、材料化学家、研究经济系统的经济学家和研究交际网络的社会学家,都声称在他们学科的深层结构中发现了信息处理过程。物理学家兼Mathematica软件的创始人史蒂芬·沃尔弗拉姆走得更远,认为信息处理蕴藏于宇宙间所有自然过程中。
于是我们看到,时兴的说法变成了:“计算机技术是关于自然和人工信息处理的学科”。计算机是研究的工具,而不是研究的对象。如同戴克斯特拉曾说的那样,“计算机相较于计算机技术,和望远镜相较于天文学差不多。”
“计算思维”的说法日益流行,指伴随着计算机计算得出的设计或探索思维方式。这个说法最初叫“算法思维”,由纽厄尔、佩利和西蒙在1960年提出,在八十年代被广泛认为是计算科学基本原理的一部分。“用计算的方式思考”意味着用信息流程的方式解决问题、寻求算法解答;不少诺贝尔奖都由这个强大的范式得出。
计算机计算的基本原则
我们对于计算机计算的解读日益成熟,对于这个领域的内容也有了新的认识。直到九十年代,大部分计算科学家依然会说计算机技术有关算法、数据结构、数学方法、编程语言、操作系统、网络、数据库、图论、人工智能和软件工程。这是对该领域的技术解读,科学的解释则需要侧重于授权和约束技术的基础原则。
为了实现这个目标,我的同事和我提出了计算机计算基本原则的框架,分为七部分:计算、通信、协调、回溯、评估和设计。

每个分类都是计算机计算的一个方面,也是了解计算机计算知识的一个窗口。分类并不互斥,例如,因特网可同时被视为通信系统、协调系统或存储系统。我们发现大部分计算机技术会涵盖七个类别的所有原则,虽然每个分类所占比例不同,但同时存在。
除了这些相对静止的原则之外,我们还要考虑计算机技术和其他领域的动态交互。科学现象通过两种方式相互影响:实现和作用。现存事物的组合通过产生行为来“实现”现象。因此,数字硬件从物质上实现了计算,人工智能实现人类思想,编译器通过机械码实现高级编程语言,氢和氧实现了水,氨基酸的复杂组合实现了生命。
“作用”发生于两种科学现象互动时。原子从质子、中子和电子间的相互作用力中产生,星系通过引力波互动,人类通过说话、触摸和计算机互动。互动既存在于领域间,也存在于领域内。例如,计算作用于物理动作(电路控制)、生命进程(DNA转录)和社会进程(有产出的博弈)。第二张表展示了计算分别和物理、生命、社会科学、计算内部的相互作用。毫无疑问,计算渗透了科学的所有领域。
信息进程是什么?
信息本身似乎就没有清晰的定义,从信息的角度定义计算有潜在的危险。信息论之父香农在1948年将信息定义为“通过信道传输的、有限数量必须回答的二元问题”。他刻意回避了比特模式的定义问题,这对定义信息至关重要。2010年,保罗·罗基浏览了各种出版物的定义,归纳出信息的定义必须涉及到客观部分(标志及其指向,或符号及其象征)和主观部分(意义)。我们怎么能从如此主观的基础上得出信息的科学定义呢?
生物学家在定义“生命”时也遇到了同样的难题。生命科学家罗伯特·哈森提到,生物学家并没有给“生命”明确定义,但对于有生命的实体有七个准则。可观察到的生命感受足以奠基生物科学,例如化学变化、能量和繁殖等。同样,我们可以将信息科学建立在可观察到的感受(标志及指向)上。
“表征”意味着代表某物的符号模式。表征和事物之间的联系可以记录在二维表或数据库中,也可以储存在人类记忆中。表征有两个重要方面:句法规则和语义结构。句法规则是构建模式的规则,它允许我们区分某些模式是否代表某物。语义结构是表征所指称的可度量的物理状态,通常是存在于媒体或信号中。将这二者放在一起,我们可以建造机器,检测有效的表征模式是否存在。
代表“计算函数的方法”的表征是“算法”。代表“值”的表征是“数据”。通过机器实现时,算法控制着输入数据表征到输出数据表征的转化;算法表征控制着数据表征的转化。算法表征和数据表征之间的区别微乎其微:编译器产生的可执行代码对于编译器来说是数据,对于运行代码的人来说是算法。
即使是简单的表征概念也会有深刻的影响。例如,如同蔡汀展示的那样,并没有一种算法来寻找某物最简单的可能表征。
有些科学家对观察到的信息处理进程是否真的被算法控制持开放态度。DNA转录可以被称为信息处理进程;如果有人发现了控制这个过程的算法,那它也可以被称为计算。
有些数学家定义计算时将其从实现中分离出来。他们将计算视为抽象语言表示的连续的逻辑指令。然而,为了描述可观察计算的运行时间,他们引入了成本概念——存储、检索或转化表征所耗费的时间或能量。许多真实世界的问题需要指数时间运算作为可实现表征的结果。我的同事和我更倾向于处理可实现表征,因为他们是科学转向计算的基础。
这些关于表征的概念足够给出满足我们需求的计算的定义了。信息处理进程就是一系列表征;物质世界中,它是持续进化和变化的表征。计算是一种信息处理过程,它在表征的控制下,依次处理序列中的元素;在物质世界中,我们会说表征控制着每一无穷小的时间和空间步骤。
计算的地位

计算,如同工程学一样,例证了正面科学。科学对于计算机计算的发展功不可没,因为许多系统太过复杂,以至于实验法是唯一可以探寻和理解其极限的方法。计算现在被视为研究自然和人工信息处理进程的广阔领域。
这个定义非常宽泛,包括了三个困扰计算科学家多年的问题。持续信息进程,例如通信系统或模拟电脑里的信号;互动进程,例如执行中的网络服务;自然处理进程,例如DNA转录;它们都看起来像计算,但不符合传统的算法定义。
基本原则框架揭示了所有计算基于的一系列规则。这些原则与物理、生命、社会科学领域以及计算本身互动。
计算并不是其它科学的子集。尽管信息处理对这些科学领域来说至关重要,但并没哪个领域从基础上关注信息处理和转化的本质。2009年,南加州大学的计算科学家保罗·罗森布罗姆说,计算是科学的新领域。他说对了。
译者: fainche 原作者:Peter J. Denning
更多阅读:

人们对大数据兴趣激增,数据分析团队也显得供不应求。大数据能让企业变得更有效率,提升整体的竞争力。具备高级数据分析能力的公司已经找到了构建长期优势的方法。例如联邦快递在过去几年里就已经靠内部的专业数据分析团队强化了收入、减少了成本,从而创造并保持了竞争优势。沃尔玛能成为全球最大、最成功的零售商,也和它强大的数据分析能力密不可分。
不过,组建数据分析团队并非易事。首先,许多公司内部缺乏相关的知识与经验,无法组建数据分析团队。另外,数据分析专业人士的市场需求也日益增加。《财富》杂志最近报道,“根据对人才市场的统计,网上征求数据分析专家的广告自 2011 年 4 月以来增长了 46%,自 2009 年 4 月以来增长了 246%,目前有超过 31000 个职位空缺。”分析师的短缺──尤其是有能力组建世界级团队并带领他们通过数据分析为企业打造竞争优势的──令企业开始考虑将数据分析业务外包。不过,要选择数据分析供应商并与之构建有效的工作关系,从而为企业传递价值,需要管理者对于自己的需求以及潜在风险有清晰了解。
企业一直在将商业流程外包,数据分析是最新的一块业务。随着电信业在 1990 年代末开始勃兴,新兴市场的通讯开始改善。于是,财富 500 强公司开始将呼叫中心转移到印度和菲律宾等地,以利用当地的廉价劳动力。其中,印度由于英语普及程度和劳动人口的受教育程度较高而受到欢迎。负责客服与远程销售的呼叫中心在海外建立后,企业开始寻找其它可以外包的业务:IT 服务、电脑编程、法律研究、应用处理与会计等。
数据分析在商业流程外包中可谓姗姗来迟。印度是一个天然的选择,因为他们具备数学与统计方面的优势。许多做数据分析的离岸商业流程公司最初都是跨国公司的分部,这些跨国公司原本已经在新兴市场拥有基础设施了。有些分部一直没有脱离总公司(例如“戴尔全球分析”就是戴尔在印度负责数据分析的分部),但也有的分离了出来,或是被其它公司收购,开始向第三方提供服务。到了 21 世纪初,从事数据分析的商业流程公司已经构成了一个既成类别。部分知名财富 500 强公司都会把至少一部分数据分析工作外包。

虽然有关 IT 外包和其它商业流程外包的研究汗牛充栋,但关于企业外包数据分析的研究却十分有限。关于 IT 外包的早期研究表明,在快速变化的市场里,外包可以通过打散固定开支来增加企业的灵活性,从而促进其它和成功相关的元素。研究员也指出,企业与外包公司的关系取决于两者间的距离、是否有足够的基础设施与联系、语言与技术能力是否过关、是否有适当的应急预案等等。潜在顾客在项目开始前需要进行适当而彻底的调研,管理层要和所有相关人等全面沟通重要的决策。(注四)顾客还必须注意保护其专业知识与核心知识产权。这意味着企业首先应该弄清楚哪些属于核心业务,哪些则是外包出去更好。
虽然以上研究结果主要适用于 IT 外包,但数据分析业务与之有明显的近似之处,例如在涉及知识产权归属时做决策要格外小心。不过,数据分析外包也有一些和 IT 外包不一样的特性。举例来说,企业通过数据分析可以创造长期的竞争优势。(注六)那么,数据分析外包对于创建和维持这种优势能起到什么作用?另外,有的公司内部就有世界级的数据分析需求,但也有的公司是第一次思考数据分析的问题。这两种公司应该用不同的思维看待数据分析外包吗?
如何处理能力鸿沟
我们研究了四家跨国公司,它们都和一家或多家外包公司有合作。另外,我们也研究了四家位于印度的商业流程外包公司。在四家跨国公司里,两家的数据分析技能可谓“高超” ,另外两家则属于“有待提高”。数据分析技能有待提高的两家公司将外包公司视为获取资源和培训的管道,希望通过这些资源来管理与执行数据分析业务,快速获得深入的见解。这两家公司的一位管理者对我们说,“设立内部数据分析团队总是不错的选择,但会很贵,在无法完全预计未来能得到什么好处的前提下,很难说服管理层进行这样的投入。外包则相对简单,可以低成本地迅速获得各种能力。”
数据分析技能有待提高的两家公司在难以找到具有熟练量化分析技巧的员工的地区设有事业部。他们知道自己在数据分析方面的不足,也知道设立内部数据分析团队的难度:设立这样的团队的成本很高,若投入不足,则失败的风险很大。因此,设立专门的离岸数据分析团队也显得过于冒险。最后,他们请商业流程外包公司为他们的员工进行了数据分析方面的培训。将数据分析外包则被视为实现竞争优势的一种方式。在某些案例中,他们会根据规模、特定的技巧以及领域知识来选择外包公司。一家发包公司的管理者说:
某些规模较大的外包数据分析公司只是请了一群廉价劳动力提供一些低级分析服务,没有什么创新。不过有些小公司,创始人来自特定行业的,他们反倒有一些别人没有的技巧和知识。那些东西可以给我们带来价值。另外他们也更有竞争意识,想做我们的生意,和大的公司竞争,所以会非常努力地提供更好的服务。
不太具备数据分析能力的公司一般不需要担心内部分析团队与外包团队之竞争的问题。他们本身几乎就没有内部分析师,涉及数据分析的员工似乎很欢迎外包公司的专业人士。“我们工作很忙,分析师不够多,因此很欢迎我们在印度的离岸合作方,”一家发包公司的员工说。

原本我们以为关于知识产权的归属问题会在发包方和外包方之间形成冲突,但事实并非如此。做数据分析的外包公司一旦为甲方开发了软件,就会希望将自己的知识与经验推广给其它潜在客户──即便它是原甲方的竞争对手。对于销售人员可以拿提成的外包公司更是如此。不过,缺乏数据分析能力的甲方管理者说他们不具备处理知识产权归属的专业技能。我们研究的两家这样的甲方公司都说他们愿意将知识产权分享给外包公司。
精通数据分析的公司如何看待外包
缺乏数据分析能力的公司通常很愿意将这部分业务外包,而精通数据分析的公司则希望扩充自己内部的分析技能。大部分情况下,这些公司只会将低端分析工作(例如对追踪维护程序等自动化任务进行报告)外包给离岸公司,而不会把全部数据分析工作外包。我们采访的一位管理者解释说:
> 我们开发了自主知识产权的分析工具,因为我们的竞争对手也在这么干。在这一行里,拥有最佳分析能力的公司才能获得市场份额并让公司更高效地运转。我们不会把这些外包给数据分析供应商,因为这是和我们的竞争力息息相关的东西。
> 不过,把重复性的分析和报告工作外包给离岸公司,可以让我们内部的分析师专注于更加高级的技巧。这能让我们在竞争中保持领先。
许多专注于数据分析的外包公司(包括我们这次研究的)都分离自大企业。因此,它们保留了原企业文化的特点,同时也有更为创新的商业实践。举例来说,为了以一种更加高效的方式服务客户,某家离岸外包公司把本地分析师和全球业务代表结成了小组。某擅长数据分析的甲方公司的一位管理者说,在和某家外包公司合作的过程中,他和其他管理者找到了某些最佳实践方法,并可以在公司内部更广泛地应用。这家公司当时正在试图将其国际业务整合到两个由美国与国际子公司构成的新事业部中,以提高整个公司的全球化程度。管理者们将外包公司视作思维领袖,希望他们可以帮助自己完成这次转型。一位管理者告诉我们:“在全球化这件事上我们有很多要(向该外包公司)学习的。”
我们和那几家给擅长数据分析的跨国公司提供外包服务的公司进行了访谈,发现其中有些潜在的矛盾。某些外包公司的管理者感到他们的知识并没有被充分利用。他们说,要是甲方内部掌握了更好的数据分析技能,他们就可以向其提供更复杂的服务。显然,他们忽视了这样一种可能性:甲方将自己的分析技能视为知识财产,不愿意与外部公司分享。的确,在知识转移这件事上,甲方和外包公司可能会有严重的矛盾。外包公司将其跨行业的工作经验视为优势,这种优势可以深化他们的知识的价值。但付了钱的甲方并不总乐于看到自己的经验(以及洞见)被其它公司廉价地分享。一位外包公司的管理者说:
> 如果客户用更战略性的角度对待外包,我们就能给他们的数据分析带去更多价值。所谓战略性的角度是指我们也能参与他们的某些和竞争力相关的数据分析项目当中,对于这些项目,我们具备更强的能力。但客户在听到这样的建议时往往会感觉受到了威胁,这会令我们的关系受损。
离岸外包公司的管理者们都认同一点:若他们和甲方的关系更加开放透明,他们的服务质量也会提高。甲方通常把外包公司当成供应商,和他们之间在数据分析上的合作也往往是跟着项目走,而不是当成整体战略规划中的一个组成部分。一位外包公司的管理者说:
> 虽然我们的数据分析能力比竞争对手要强,但通常起到决定性作用的仍然是谁能以最低的价格提供常规性服务。离岸数据分析服务的商品化妨碍了更深入的合作,我们原本可以和甲方从战略性的角度一起构建更好的数据分析竞争力。
这些评语很有意思,也令我们意外,因此我们又对那两个擅长数据分析的跨国公司进行了一轮回访。我们特地问了他们:如果能和外包公司结成战略性合作关系,对方是否可以帮助他们改进业务?一位管理者回答说:
> 这些外包公司都说他们希望能更加创新,但我觉得在实际中不可行。他们雇佣的统计分析师通常都是刚刚毕业,没有什么经验。这些人的统计技能很好,但对我们的业务就是不够了解,没法做出战略性贡献。大多数情况下,我们都得自己培训外包公司的分析师……不过,一旦告诉他们应该怎么做了之后,他们都能在现有的环境中很好地创新。但是如果说要让他们一来就产生关于数据分析的突破性点子,我觉得不太可能。
在这个案例中,外包公司的管理者对于自己能够做出的贡献的认知与甲方的认知不符。的确,跨国公司或许已经想好了外包公司是否能在更高层次上提供服务──事实上他们或许已经将自己的这种构想变成了现实。
除此之外,外包公司之间可能发生的收购与并购也会令人担忧。并购可能令双方悉心构建的战略关系毁于一旦,导致客户的“战略分析”落到他人手中。
创建成功的数据分析合作关系
我们发现,不擅长数据分析、但意识到需要在这方面加强的公司可以利用离岸外包公司获得优势。一旦选择了适合自己的文化和业务需要的外包公司,这些公司就能发展出竞争力与独一无二的分析技能,从而获得竞争优势。不过要做到这点,企业必须悉心设计与外包公司的合作关系。他们要做的事情包括对外包公司的营销维持一定程度的控制权,防止外包公司将双方共同的工作过分地据为己有。
对于擅长数据分析的公司则是另一回事。对于它们而言,与外包公司合作的好处不仅仅在于低成本与低税率。我们通过研究发现了有趣的一点:即便对于擅长数据分析的公司而言,这些外包公司都能够教给他们新的东西。不过,我们采访的甲方要么已经有了内部的数据分析团队,要么打算建立这样的团队。他们不准备把全部数据分析业务都外包出去。当然,在内部做分析的好处之一是可以保护知识产权。
对于任何考虑外包数据分析业务的公司而言,若想获得外包公司较高阶的技能,就需要仔细构建与它们的关系。你需要了解双方各自的动机,以及对方被并购的可能性。在协商时,需要明确双方权责、产权归属以及各方使用信息的权限、以及一旦外包公司被并购,应该如何处理既成的工作成果、信息与知识。随着企业越来越倚赖于数据分析,这些与知识产权归属相关的问题对双方都至关重要──他们必须达成一套对双方都有益的解决方案。
作者:大卫·傅加提、彼得·C·贝尔 来源:MIT科技评论
更多阅读:

Baekdal Plus可以对分享进行追踪,而不需要广告变量或者社交按钮(这些通常不可靠)。当一个用户分享了一篇文章,URL会自己识别出被分享。  换句话说,通过URL本身,可以细分出只是通过分享到达的流量。这可以让人更好的洞察混合的真正的社交分享是怎样的。 以下是2014年前两季度的分类
换句话说,通过URL本身,可以细分出只是通过分享到达的流量。这可以让人更好的洞察混合的真正的社交分享是怎样的。 以下是2014年前两季度的分类  记住,这里面的流量全部来自“分享”。这里你能看到的只是那些通过一个用户的分享链接进入Baekdal Plus的人。没有自然流量,也没有任何搜索流量。只是通过其他人分享的流量。 可能你第一个会注意到的就是“社交媒体”只占整体比例的3-4%。考虑到所有的这些是被分享的,这个结果让人吃惊。因此,这就是全部的社交媒体。 而这一结果是因为一个分享的链接通常由在Twitter/Facebook上被分享开始,但是它会被其他渠道获取并再次分享。但是因为Baekdal Plus的分析系统不能跨过人们来追踪来源,这一结果最终呈现出是3-4%来自社交媒体,96%来自其他渠道。这是为什么我们看到“社交媒体”分享如此低的主要原因之一。 最大的来源是多种形式的推荐,从一个月到另一个月的变化很明显。像’Pocket’、Reddit这样的网站通常得分高,但是大多数分享流量来自成千上百的个人网站,每一个都不多,但是合在一起数量巨大。
记住,这里面的流量全部来自“分享”。这里你能看到的只是那些通过一个用户的分享链接进入Baekdal Plus的人。没有自然流量,也没有任何搜索流量。只是通过其他人分享的流量。 可能你第一个会注意到的就是“社交媒体”只占整体比例的3-4%。考虑到所有的这些是被分享的,这个结果让人吃惊。因此,这就是全部的社交媒体。 而这一结果是因为一个分享的链接通常由在Twitter/Facebook上被分享开始,但是它会被其他渠道获取并再次分享。但是因为Baekdal Plus的分析系统不能跨过人们来追踪来源,这一结果最终呈现出是3-4%来自社交媒体,96%来自其他渠道。这是为什么我们看到“社交媒体”分享如此低的主要原因之一。 最大的来源是多种形式的推荐,从一个月到另一个月的变化很明显。像’Pocket’、Reddit这样的网站通常得分高,但是大多数分享流量来自成千上百的个人网站,每一个都不多,但是合在一起数量巨大。
邮件是另一个大的来源。但是这不是来自我的新闻(这些都不是来自我的渠道,而是来自别人的),换句话说,这是人们在他们的新闻中分享了一个到Plus文章的链接。
当我们遇到“不确定”流量这一大障碍或者大多数分析服务定位为“直接”的。正如你了解的,这就是当你分析时不能确定人们来自哪里。
但事情就是这样。一个被分享的plus文章像这样: http://www.baekdal.com/insights/the-future-of-news-and-the-replicators/F436152DDC174B1A8CCA64C9835B77E491A2E70AB498099CA88ECB3991FCC9CB 很明显没有办法,这是直接的。没有人会输入这个指令,也没有人能通过书签产生流量(因为我追踪的是人而不是观点)因此,本质上,这就是我说的“黑暗社交”这是分享流量中我们没办法知道是什么的部分。
最后,有一部分是“其他”,这是在我的分析系统中被列为奇怪的或者不被确定的部分。你会注意到“其他”的流量有时比“社交媒体”还要多。
因此,你看到问题了吗?所有这些被分享的流量中,最初被我的用户分享,然后被其他人再次分享。所有的这些是社交媒体,然而只有3-4%是被确认的。 这是理解分享的关键内容。如果你观察你的来源,你只能了解到最后一次分享。对此有个简单的例子: 以下通过我一个在Twitter上的订阅者,可以看到一个连接被分享时会发生什么。换句话说,第一次分享100%是社交媒体,并通过Twitter。然后他的一些Twitter的关注者点击链接,一些关注者转发再次分享。一些通过Twitter,一些通过Facebook或Google+,但是社交媒体以外的链接传播逐渐增加,并进入博客和媒体网站。  结果是,由某人推发的一个链接开始,到被不同的来源分享。由于你的分析只能记录最后一次分享,所以你就不会知道对这个链接最初100%由社交互动引起。 到最后,注意到只有3%被记录是来自社交媒体,但是如果这个订阅者一开始没有推发这个链接,什么都不会发生。 很明显,这只是一个例子。其他的人可能通过另一种方法来分享链接,将会有另一个结果。但是问题在于,正像电子商务不想看到“最后一次点击”一样,你也不想在社交媒体上只看到“最后一次分享”。 通过比较Twitter分析来从另一种角度看这一问题,分享的实际的数量。当你使用Twitter Cards,你可以得到关于人们分享你内容的清晰分类,以及他们分享的个人的推文。
结果是,由某人推发的一个链接开始,到被不同的来源分享。由于你的分析只能记录最后一次分享,所以你就不会知道对这个链接最初100%由社交互动引起。 到最后,注意到只有3%被记录是来自社交媒体,但是如果这个订阅者一开始没有推发这个链接,什么都不会发生。 很明显,这只是一个例子。其他的人可能通过另一种方法来分享链接,将会有另一个结果。但是问题在于,正像电子商务不想看到“最后一次点击”一样,你也不想在社交媒体上只看到“最后一次分享”。 通过比较Twitter分析来从另一种角度看这一问题,分享的实际的数量。当你使用Twitter Cards,你可以得到关于人们分享你内容的清晰分类,以及他们分享的个人的推文。  看第一个,这个人从一个推文中引发了196次点击,这非常棒。但是因为我可以通过Baekdal Plus追踪个人连接,因此我可以比较他和我自己的分析,我的记录下669次点击。
看第一个,这个人从一个推文中引发了196次点击,这非常棒。但是因为我可以通过Baekdal Plus追踪个人连接,因此我可以比较他和我自己的分析,我的记录下669次点击。
换句话说,从这一个推文,有196次点击直接来自Twitter(最初的推文和再次推文),另外473次点击来自通过其他形式分享的别的来源。对这个推问来说,社交媒体的真正影响被低估了341%。
这令人惊讶吗?
这引出了一个非常重要的问题:你个人的社交媒体渠道作为一个整体与分享相比有多重要?
明显地,因为它受到很多因素影响,因此不可能是一个单一的答案。你与人们进行社交上的互动的理由是建立动力。
而你的社交媒体渠道的效果依赖于这个动力是否是你需要的,或者你可以通过其他手段得到它。
以这个网站为例,我从来没有真正在这个网站上花钱做广告。我从2004年开始,从开始随着时间流逝只是增长缓慢到现在的情况。因此,从这层意义上说,我所有的流量从某种意义上说是受我影响的。如果不是因为我已经从其他渠道联系人们(开始是在论坛和社区网站,现在主要通过社交网站),我现在所做的是不可能的。
如今,这个网站已经众所周知了。如果我观察六个月内引起新的流量和新的订阅者的原因,大多数不是因为我自己。而是由其他人分享和再次分享我的文章引起的。
因此,从增长方面说,我在Twitter, Google+ 或Facebook上做的对我来说基本没有区别。相反,我自己的社交渠道聚焦于“培育”我现有的读者。如果大多数我的增长来自于别的人,那对我来说培育你,我的读者是重要的,因此我们紧密相连。对Twitter 和Google+上尤其如此,我最忠实的读者将大多数时间花费在那里。
做一个比较:上个月我在Twitter上发布了一个链接(这样我可以追踪),然后对比了我所有的分享流量(每一个链接)。结果是我发布的链接获得了一个高水平的查阅,但是分享只占总数的2%。
因此你的战略应该与每一个品牌和每一个出版商不同。你需要观察你今天在哪,与你在哪里缺乏动力相比较,以及你现有的关系圈有多好。
对一些品牌来说,实际上你自己的渠道可能更重要。例如:你最终使得客户从哪里发现新的内容?为了让其他人开始分享你的东西,他们首先需要知道你在做什么。
这都依赖于你与你的客户间的性质和你所在的市场。例如,我在YouTube上关注了一些品牌,没有这些渠道,我几乎不知道他们做了哪些新的内容,它是我唯一的联系来源。
一般来说,你最重要的渠道不是你的任何社交渠道。而是你的产品,是你的客户或者读者将分享的。第二重要的渠道是可以让人们以最合理的方式关注的渠道。
我的结论有两个:首先,通过观察最后的分享点,你通常得到的是一个几乎完全扭曲了你的社交媒体互动真实价值的画面。其次,这些社交互动通常不是从你把他们发布在Facebook或Twitter上开始的.
你必须将你的社交战略聚焦在分享本身,而不是去关注你正在自己的社交渠道做的事情。
199IT 编译自https://www.baekdal.com/analysis/a-lesson-in-social-tracking/ ,转载请注明
译者 Jane
更多阅读:

除收益之外,iTunes同样可以按开票数(或总收入)测量。开票数增长率更高,超过25%。相对于在音乐方面逐步衰弱,这主要是APP的更快速增长。因为苹果只记录了30%那些保持为“收益”的APP,在APP方面的整体增长在它的账目上不是很明显。
开票数的相对表现和报告的收入如下图所示:

注意在媒体类型和软件和服务间预计的分裂。业务中软件和服务的销售额到19亿美元,而来自第三方的内容或APP的收入达到26亿美元。
这一数据的价值在于它包含了几乎完整的苹果生态体系视图。由于几乎所有的内容和交易被追踪和记录,人们可以得到一个该生态体系经济价值的非常精确地视图。【1】【2】【3】
自从iPhone发布后,苹果生态体系的价值增长了超过600%,比整体销售增长(大约400%)要快。如果生态体系价值增长远高于下层的硬件销售增长速度,问题就浮现了,那就是什么时候生态体系交易价值超过业务是所谓的支持。
现在,iTunes/S/S生态体系大约200亿美元/年。iPod, iPhone, iPad 和 Mac销售额大约1500亿美元/年。看起来前者超过后者的可能性不大。如果情况属实,那么不禁就要问了,为什么建立一个完全以零售和服务为基础的业务,没有硬件收入的支撑,类似于亚马逊。
【1】除了iTunes/软件/服务以外,Accessories也可以被看作是生态体系的一部分。按照苹果记录的Accessories和许可证的价值为iTunes/软件/服务增加了另外的60亿美元。
【2】被遗漏的是通过APP产生的广告的收入,不是使用iAd广告平台。
【3】同样值得询问的是可代替的生态体系是什么规模,如Microsoft, Google等
原创编译,转载请注明出处
199IT编译自asymco
译者 Jane
更多阅读:

一批具有智能搜索特征和语音辅助服务功能的设备继续让更多的投入向移动搜索引擎、APP和网站转移。2014年第二季度,Covario的高科技消费性电子产品和零售客户在移动搜索广告上支出增长了近两倍,和去年同期一样。总体来说,移动广告这一季度比去年同期增长了98%,环比增长6%。
在Covario客户中,移动搜索广告占整个全球搜索投资的25%。移动设备上的广告支出的差距相比上一季度缩小了,第二季度预算中智能手机占38%,平板电脑占62%。设备的媒体支出中台式机占75%,平板占15%,智能手机占10%。
根据Covario ,2014年第二季度展现量、点击量和预算同比出现两位数增长。每点击成本和点击率夷为平地。总体来说,每点击成本同比增长0.7%,环比下降6%。对台式机每点击成本保持大幅折扣,移动点击率第二季度下降43%。
总体来说,付费搜索每点击成本同比增长2%,点击量增多,点击率为40%,继续的,该公司发现它12%的客户每点击成本和点击率分别下降了9%和14%。
根据Covario,本季度全球范围内,谷歌获得73%的展现量,60%的点击量和86%的预算。百度紧随其后,占比分别为17%,34%和7%。微软排名第三,占3%的展现量,4%的点击量和4%的预算。Naver占1%的展现量,1%的点击量和1%的支出。Yandex占5%的展现量,2%的点击量和2%的预算
eMarketer预测虽然谷歌相比去年失去一小部分份额,但基于越来越多的广告费用向搜索转移,它将保持控制全球半数以上的移动广告费用。2014年全球大约50.2%的移动互联网广告纯收益将属于谷歌,Facebook将占22.3%,Twitter占2.8%。
199IT原创编译 译者 Jane
更多阅读:

这个列表包含了几乎所有经常更新的大数据的博客,属于一个广泛的类别:数据科学,数据分析,商业智能,机器学习,数据可视化,数据挖掘,NoSQL,Hadoop的等等。博客是按字母顺序排列。如果我们错过了任何重要的博客,请告诉我们。
4. A Computer Scientist In A Business School
7. Advanced Football Analytics
8. Adventures In Analytics And Visualization
10. Ai, Data Mining, Machine Learning And Other Things
13. Analyticbridge
16. Atbrox
17. Bitquill
18. Ben Lorica – O’reilly Radar
19. Benfry
20. Benoreilly
21. Beyenetwork
23. Blog About Stats
25. Infochimps
26. Blprnt
28. Ai And Social Science – Brendan O’connor
29. Brent Ozar
30. Business Intelligence News By Marcus Borba
31. Business. Statistics. Technology
32. Byte Mining
34. Chart Porn
36. Chuck’s Blog
38. Cloudera
39. Compilation Of Links And News For Data Mining Geeks
40. Cool Data
42. Crowdflower
44. Dana Gardner’s Briefingsdirect
45. Daniel Lemire’s
46. Data Analysis
47. Data Beta
48. Data Doghouse – Performance Management, Business Intelligence, And Data
49. Data Evolution
50. Data Miners Blog
53. Data Mining: Text Mining, Visualization And Social Media
54. Data Wrangling
55. Betaworks
56. Data Doodle
57. Data Is Nature
58. Datalligence
59. Datascience
61. Dbms2 — Database Management System Services
62. Deal Architect
63. Decision Stats
66. Dmr – Data Mining And Reporting
67. Drunkendata
68. Eagereyes
69. Evanmiller.Org
70. Fern Halper’s Data Makes The World Go ‘
71. Flowingdata
74. Google Analytics
75. Hadoop And Distributed Computing At Yahoo!
77. High Scalability – Building Bigger, Faster, More Reliable
78. Hilarymason.Com – Hilary Mason
82. Igvita
86. Jon Udell
87. Journey To Sql Authority With Pinal Dave
89. Juice Analysis
90. Julian Hyde On Open Source Olap. And
92. Kevin Hillstrom: Minethatdata
93. Laura Edell’s Scorecard Street & Business Intelligence Blog
94. Life Analytics
95. Lingpipe Blog
96. Machine Learning
99. Market Strategies For It Suppliers
100. Marktab Data Mining
101. Metaoptimize
102. Michael G. Noll
103. Michael Nielsen
104. Mixpanel
105. Monsi Terdex Blog
106. My Biased Coin
107. Mynosql
108. Mysql Dba
109. Mysql Expert
111. Nati Shalom’s Blog
112. Natural Language Processing
113. Neoformix
115. Northscale Blog
116. Nuit Blanche
117. Ocdq Blog Feed
118. Oktrends
121. Overstated
122. Pedro Alves On Business Intelligence
123. Pete Warden’s Blog
124. Predictive Analytics
127. R Blogger
128. Radical Data Science
129. Rasmus Bååth’s Research Blog
130. Recorded Future Blog
131. Research Blog
132. Research Computing At Stern/Nyu
133. Revolutions
134. Riccomini
135. Richard Lees On BI
136. Robert Grossman
137. Roland Bouman’s
138. Saaientist
139. Salmon Run
140. Sarah’s Thoughts On Mysql
141. Sas Blogs
142. Sas Programming For Data Mining
143. Simplified Analytics
144. Simply Statistics
145. Simply Statistics
146. Social Mashup
148. Statistical Modeling, Causal Inference, And Social Science
149. Statistics And Machine Learning
150. Stats With Cats Blog
151. Storagemojo
152. Stream Computing
153. Streamhacker
154. Talend
155. Tanel Poder’s Blog
156. Text & Data Mining By Practical Means
157. Text Data Mining
158. The Data Mining & Research Blog
160. The Endeavour
161. The Enterprise System Spectator
162. The Geomblog
163. The Openstack Blog Open Source Cloud Computing Software
164. The Practical Quant
165. The Text Frontie
166. Thoughts Of Machine Learning
167. Umbc Ebiquity Blog
168. VC
169. Via Science Blog
170. Vision
171. Visual Business Intelligence
172. Web Analytics, Behavioral Targeting And Optimization By Anil Batra
173. Well-Formed
174. What’s New
175. Yhat
译:199IT.com 来源:bigdata-madesimple.com
更多阅读:
五分之一的人对企业保障个人数据持信任态度。
华盛顿发生了一系列的网络安全故障,eBay系统开始关注消费者对商业持有客人信息的安全性。只有21%的美国人非常相信他们互动的企业的信息安全。而且不仅是对信息安全信任下降,美国人对公司的信任度也在下降,37%的受访者说他们对企业的信任度下降。

银行、信用卡公司位于消费者信任机构列表榜首
银行和信用卡公司是九项个人信息安全机构中信任度最高的,39%的消费者非常信任,紧随其后的是医疗保险企业(26%)和手机供应商(19%),排在末尾的是在线零售商(6%)和社交网站或应用(2%)。

金融危机后美国消费者对银行和其他金融机构也失去了信心。2012年6月美国消费者信心指数达到最低点,只有21%,而五年前对银行的信心指数是41%,现在,根木盖洛普2014年3月调查显示,美国消费者对银行等金融机构的信心指数是22%。金融机构使用特定的法律参数保护私人信息,增强消费者对金融机构持有个人信息的信任度。
意义
调查结果给银行业带来契机。尽管面对重拾公众信心的重任,银行业仍然在保护私人信息方面领先于其他行业。这只代表了信心的一个方面,但是在消费者信任度总体下降和个人信息面临越来越频繁威胁情况下它就更重要了。
盖洛普致力于与消费者建立情感联系来建立信心的重要性,但是这种情感联系不是一夜之间就能建立的。银行需要提供一致的服务满足客户基本需求,同时兑现他们的承诺。根据盖洛普2013年对银行业的研究显示,与消费者建立情感联系无疑是艰难的,但是信任带来参与,参与进来的消费者不仅给银行带来利润,而且也能带来更多的投资和银行储备。
银行能够借此机会展示他们对私人信息的保护不仅仅是出于法律责任,而且承诺保护私人信息是因为他们关心他们的客户的财务福祉,这是与客户建立情感联系的契机。个人理财是私人事情,没有变通之法。银行需要确保客户与他们是同一阵线,确保客户敏感信息的安全,时刻把客户利益放在心中。世界越来越不安全,客户需要得到信息安全伙伴。
更多阅读:
近期,移动设备的品牌编辑媒体正在吸引用户。Sharethrough2014年6月发布的数据显示,2014年Q1通过该公司的“Sharethrough Exchange”在移送手机上以原生和信息流广告形式推广的品牌编辑内容的互动率高达2.2%

观察不同的编辑媒体类型,存在于自有网站的内容在支出上占有绝对优势,从2013年第四季度到2014年第一季度增加了31%,占比达68%。虽然存在于专业出版商网站的赞助编辑媒体被看做是一个小得多的份额,但在移动设备上可以看到其支出上的显著增长,同时,赢得媒体——不用付费的关于品牌的文章,占据了剩余3%的份额。
自有媒体范围广泛,Sharethrough发现企业博客是运营这一内容的最受欢迎的网站类型,占据近一半的支出。品牌编辑网站——“一个主题编辑网站,使用品牌作为它名字的一部分,并可能存在于这个品牌企业网站内,或是一个独立的网址”,和企业网站获取的投资份额分别占23%。
但是费用支出并不意味着全部,Sharethrough指出,赢得媒体有最高的参与率,这表明品牌可以通过此形式获取更高的价值。同时,赞助媒体和自有媒体分别位列第二位和第三位。
2013年8月,Sharethrough发现几乎所有的美国数字广告专家认为本地化的移动广告对品牌活动总体来说都非常或者多少有效的,并且这一渠道的支出在未来几年很可能增长。根据2013年9月由Interactive Advertising Bureau 和 Ovum发布的数据显示,74%的美国移动营销人员表示本地移动广告是一项重要或非常重要的移动广告发展。
199IT编译自emarketer
更多阅读:
智能手机在旅游业方面的消费在上升:eMarketer预测今年会有0.26亿美国消费者通过手机订购旅行。

智能手机的便利和针对手机用户的打折推动了最后一刻旅馆销售(一种限时打折的旅馆订购模式)的增长。根据eMarketer新报告“旅游购物:手机订购旅馆兴起,但其他交易落后”,随着智能手机订购旅馆的兴起,行业营销人员打算建构应用程序来简化手机消费流程。
旅游营销人员称手机应用能够简化手机销售过程。Will Pinnell是Sabre控股公司移动战略和游客解决方案总监,他说“那些认真对待生意,想吸引人们订购旅馆、房间、机票的公司正在投资手机应用程序。”

JiWire(现在叫Ninth Decimal)在2013年3月进行的调查发现游客喜欢通过手机应用上网消费。调查显示,美国手机Wi-Fi用户最喜欢集成旅游应用软件,相比于公司提供的手机网站更重要的是应用集合了航空和旅馆。
应用软件给智能手机用户消费提供了很多好处,更重要的是,程序设计结合了手机的“本机”特点,让用户体验更人性化的消费过程。旅游应用的本机特点之一是保存个人信用卡信息、钟爱的程序号码或最喜欢的旅馆。
本机应用还能利用智能手机定位特性搜索周边旅馆。游客可以通过定位查找相关属性旅馆,而不需要提供其他细节。这种功能通过手机网络也能实现,但是移动应用更有效。2013年4月,Hospitality Technology发现全世界38%的酒店经理有通过手机GPS进行属性搜索的手机应用,而且随着品牌和游客对这一技术越来越满意,这个数量还将增加。
199IT编译
更多阅读:

众筹正让3D打印离个体消费者更近
根据Canalys估计,2014年第一季度,26800台3D打印机发货到世界各地。这些大多数被企业消费者购买,范围从微型企业到大型机构,但是有46%的3D打印机被消费者购买,相比2013年(43%)出现上升,这反映出在价格上越来越具有竞争力的3D打印机的普及。
Canalys 高级分析师Tim Shepherd指出:“迄今为止,企业仍旧是3D打印活动的重点。来自很多行业的企业已经向3D打印的技术方面进行投资,来实验并测试它的潜能、加快设计和原型设计过程以及使本地定制生产成为可能。当企业的参与不断增长的同时,在不久的将来,消费者领域也将推动发货量。我们已经看到相当数量的早期技术采用者和爱好者投资相对便宜的3 d打印机。随着价格持续下降,技术的改善和使用案例被测试,这一趋势将继续下去。”
低成本3D打印机的日益普及的一个值得注意的因素是众筹。“超低价3D打印机的数量之多令人印象深刻,特别是来自通过诸如Kickstarter 和Indiegogo这样的众筹网站来寻找投资的创新企业和有抱负的初创企业。这些项目在实现其融资目标方面往往迅速成功表明众筹网站代表了在这一领域的一个可靠地融资渠道,并且更重要的是,这证明了实际消费者的兴趣水平。虽然他们经常被能打印物品的尺寸、能使用的材料和能提供的结果所限,但经济实惠的打印机将继续引起新兴消费者市场的兴趣和采纳,给供应商一个增加销售的机会。”Shepherd表示。
Canalys表示2014年第一季度发货的3D打印机67%的定价是税前低于10000美金的。“事实上,有许多低于1000美金的基础打印机型号将上市,并有一些众筹项目承诺出低于500美金的价格。”Canalys分析员 Joe Kempton表示,“由于市场竞争压力的增加,各种技术专利的失效和供应商渴望满足兴趣和要求,跌价让打印机对更多的消费者来说更为实惠。不仅初创公司来供应这些消费者,还建立了供应商,例如Stratasys通过它的MakerBot品牌。我们也看到其他的努力让3D打印更可行,最近,Autodesk公司让它的3D打印机硬件和它的星火设计软件开源。10年以内,3D打印机在发达市场将成为家庭常见物品,这些正带我们朝着正确的方向发展。”
同时,在高端市场,价格超过10万美金的工业级打印机仍旧占据1%的发货量。供应商对此细分市场的目标是一年内销售少量的打印机,但是随着一些高端打印机的价格超过100万美元,它仍旧可能获取客观的收益。并且随着制造业使用3D打印的增加,明年在这一市场的发货量仍有望增加。
199IT编译自http://www.canalys.com/newsroom/3d-printers-gaining-significant-traction-among-consumers
更多阅读:

根据Devicescape一份市场研究报告,零售商和其他面向消费者的企业看到了提供免费商用Wi-Fi的好处,Devicescape自己号称是“世界上最大的Wi-Fi服务平台的经营商”。
这份对美国超过400个小型的,面向消费者企业的调查结果显示,相比其他关键指标,通过提供免费的Wi-Fi可以改善客流量、增加客人在店时间和增加消费者的消费。
使用免费Wi-Fi的消费者的消费情况
将近三分之二的受访者(62%)表示自从他们引进免费Wi-Fi,消费者在店内的时间更长了,半数受访者表示使用免费Wi-Fi使消费者的消费额增加。只有0.1%受访者表示出现下降。
这项由iGR代表Devicescape组织的调查涵盖了各类小型、零售企业,包括酒吧、咖啡店、服装精品店、书店和沙龙。
超过四分之三(77%)的受访者认为免费提供Wi-Fi对与他们的生意是“重要的”或“非常重要的”。 Devicescape指出“许多人将其描述为有竞争力的必要条件”。
这一调查显示出虽然不同企业引进免费Wi-Fi的目的是不同的,但它取得很高的成功率。根据Devicescape调查,通过以下引入Wi-Fi被认为是成功的:
- 79%的受访者引入Wi-Fi将其作为对消费者的一项额外服务。
- 69%的受访者引入Wi-Fi来增加客流量。
- 72%的受访者引入Wi-Fi来提高销量
在让受访者评价客户对他们提供的免费Wi-Fi 服务的性能表现时,66%的受访者表示他们的客户认为“快”或者“非常快”。将近四分之三(73%)的人表示他们“从没有”或“很少”收到客户对Wi-Fi速度或者质量的抱怨。
在对调查结果评论时,iGR的创始人和董事长Iain Gillott阐述:“调查结果显示出对零售企业来说,开通面向消费者的Wi-Fi已变得多么重要。Wi-Fi的有效性已经不再是一项限制于大型零售连锁的创新,小型企业现在也开始在他们的场所向雇员和客户提供相同的服务。在不久的将来,小型企业将把Wi-Fi看作对他们成功很重要的动力和源泉。”
Devicescape的 CEO Dave Fraser补充道:“有一个非常大的误解,就是认为商用Wi-Fi的质量很差。这一研究表明我们已经认识了很久的商用Wi-Fi对小企业来说正在成为常态,而且提供的服务室非常快、质量很高的。对移动连接来说它是一个非常强大的平台,并且可以为企业和消费者都带来巨大的利益。”
199IT编译自Jane